After part three where we discussed Kubernetes Cluster Deployment, we are now getting dangerous in the Kubernetes world. We have a great understanding of doing basics on the platform. If you are feeling adventurous, you can get the learning material and even sign up for the Certified Kubernetes Exam [CKA] and further your bad-ass-ery.In the Kubernetes ecosystem, there are some lines in the sand that become blurry. Is certain functionality to be delegated to the Kubernetes platform or is functionality is the responsibility of the application being deployed?Muddying the waters, even more, there are hot technologies that are enhancing pluggable Kubernetes functionality like Ingress Controller options such as Gloo and Kong. The bootstrap question comes back into play; we can use Ingress Controllers to enhance our deployments but getting them on our platform (e.g a Kubernetes infrastructure change) requires due care propagating changes to the Kubernetes platform itself. I thought Kubernetes was supposed to be easy!
Kubernetes the hard way
Like showing your work on a math test or whiteboarding during a software engineering interview, learning how to create a Kubernetes cluster without any helper methods gets you very familiar with the platform. The quintessential example of the hard way is by Kelsey Hightower called “Kubernetes the Hard Way."Reading through the steps can be very helpful especially around adding nodes and seeing how the communication is wired up, because one operation that will be bound to happen during any Kubernetes journey is adding and subtracting Kubernetes Worker Nodes. Understanding those steps one can conjure up several self- or community-prescribed ways of scaling clusters using automation tools.I'll say this, though: the "hard way" might be dying by the vine with so many providers/projects looking to ease folks into Kubernetes.
Add me a K8s Node, please
There are certainly more ways to add worker nodes than Kelsey’s bare-bones example. Early value adds from vendors were more streamlined and elastic ways to expand and contract your Kubernetes Cluster. Remember: Kubernetes is still a piece of infrastructure that has to be managed.Public cloud and platform-as-a-service vendors, depending on what flavor of service you receive from them, make adding a node easy. Below is a list of a few major vendors that can add worker nodes. Most of them have a few caveats such as the cluster has to be created with one of their CLIs/SDKs or the potential maximum size of clusters.
Adding a Kubernetes Node is pretty baked with that list above. Modern complexities around cluster sizing, such as when to scale a Kubernetes Cluster, are still up for interpretation. Adding K8’s nodes and infrastructure to support those nodes can take minutes and having a good grasp on events that would require your cluster to scale is a science in itself. Good capacity planning discipline is still needed.With just a few nodes, we can start deploying our actual applications into Kubernetes.
Kubernetes - always be deploying
In the background, containers are being spun up without admin intervention all the time in Kubernetes. That is a core benefit of the Kubernetes scheduler (remember from part two) enforcing the defined number of Replicas in case an ephemeral Kubernetes container (remember from part one) dies which is per design.My colleague wrote an excellent blog piece on the different types of deployment strategies. Two prominent release strategies are canary releases and blue/green (or pick your color of choice e.g red/black).Though the concept of blue/green is to have identical production environments aka 100% more infrastructure that is actually running in production to minimize risk and flip the proverbial switch. This would be expensive for your Kubernetes Cluster to scale or having the extra capacity for the blue/green.From a pure deployment strategy, a canary deployment can be seen as being more complicated because you are splitting a percent e.g flipping the switch twice (or more if incremental canaries) but you can accomplish on less firepower than a blue/green.
Canary me some apps in K8s - not getting easier
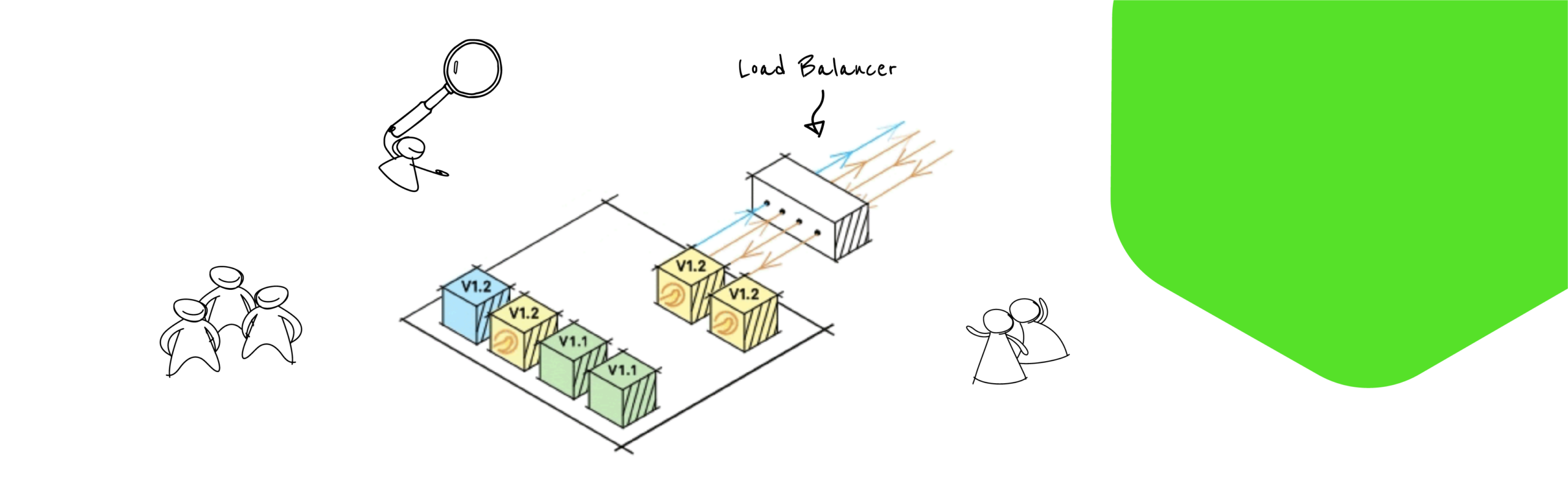
One of the most comprehensive guides I have seen about pulling off a canary deployment in Kubernetes is this post from Dockbit from 2017. When you are reading the post, you might start to notice that the post keeps going for a while and your finger is tired of scrolling. This is not by accident; there are several moving pieces that need to be orchestrated and strategy around each. As the Kubernetes ecosystem starts to expand and become more fine-grained, the decisions become more complex.As a reminder, the purpose of a canary is to be seamless for the clients needing to access the application; one URL/URI with potentially two eventual versions inside the cluster. The strategy of load balancer -> [ canary (label) + stable (label) ] is achieved by orchestrating Deployments and Deletes that will help achieve a canary release.
Labels and Selectors
We need to introduce some sort of change / new deployment into Kubernetes. How do we differentiate one deployment from the next? In our previous example of the Kung-Fu-Canary.YAML deployment, let’s say we are ready to introduce some changes. We will need to designate to Kubernetes that this is a different somehow; if we just re-deploy the same configuration and just increment let’s say the Docker Image, Kubernetes will work as fast as possible to replace every known Pod and we just went for the gold, not a phased approach.Luckily for us, there are Labels and Selectors. When creating our objects, we can add Label elements helping differentiate one from the next. Labels can contain any sort of details/meta-data you would like to add; for a canary, this might be designating a certain environment or even labeling a particular Deployment as the canary. We can create another version of our deployment, this time with a label. Since we are deploying a canary, the number of replicas we need will be less; we moved from 3 to 1.
Now that Deployment which will be used as the canary has the correct Label, operations that we need to actually introduce the canary and eventually flip the switch such as a Service or Ingress load balancer can operate on that label with a Selector. To introduce your new deployment to the Kubernetes load balancer rotation, you can expand the Selector the Kubernetes load balancer to include the new Label or make sure the Labels are common and line up across versions like “application name."
Where do we make the flip?
Since the Dockit blog, there has been a growth in Ingress options in Kubernetes. What Ingress is the communication from the outside the Kubernetes Cluster to inside the Kubernetes Cluster. Load balancing can take many shapes and forms; the level four ->level seven load balancing could easily happen outside the Kubernetes cluster as user requests race across the internet.However, inside your cluster, there could be other items running such as a service mesh like Istio. Do we delegate the canary load balancing logic to the service mesh routing rules or somewhere else?What about at the Ingress layer with a project like Gloo instead of the ephemeral load balancer? As you can see there are lots of options for us to decide where to match the switch. As new ways to wire our cluster communications together become popular, we will certainly be presented with more options.With all of the technique and preparation, we can have a successful canary; though success in canary terms if the canary lives or dies still proves value.
When “ship” hits the fan
Oh no, our little canary did not survive in the coal mine -- I mean the K8s cluster. A commonly used command is the Rollout command which is the plan that K8’s takes to deploy resources. For example, in the original kung-fu-canary.YAML from part three, we set three Replica Sets.To take a quick look at a Rollout, all you have to do is deploy the Kung Fu Canary Deployment, again. If you have this currently running, can delete with “kubectl delete deploy/kung-fu-canary”. We can re-deploy with “kubectl apply -f kung-fu-canary.yaml” and take a look at the Rollout status with “kubectl rollout status deployment/kung-fu-canary”
Let’s say we wanted to make a few changes. Instead of using Nginx, we want to use Apache HTTPD and start with five Replicas.
We save that as kung-fu-canary_update.YAML. Now we can deploy the update with “kubectl apply -f kung-fu-canary_update.yaml” and watch the Rollout with again “kubectl rollout status -w deployment/kung-fu-canary”
We can take a look at the Rollout history with “kubectl rollout history deployment/kung-fu-canary” and see we added another revision.
Oh no, we decided that we would like nginx better so let’s trigger the rollback with “kubectl rollout undo deployment/kung-fu-canary”
Congratulations, you just went through a basic rollback example. We only had one simple-ish Deployment and did not have to worry about multiple transient pieces. Luckily, Harness is here to help.
With Harness, wave the magic wand
With all of these options and the number of options only seem to expand, how can we focus on just having Canary functionality work? Well never fear, Harness software delivery platform is here! Harness can easily make a Kubernetes Canary part of your overall Continuous Delivery pipeline. Even if your opinion leans towards Istio and traffic splitting there, Harness has your back there also. Stay tuned for part five where we take a look at why all of our workloads are not in Kubernetes today.-Ravi
.svg)
.png)




