By Harsh Jain, Sahil Hindwani, Dinesh Garg, and Gaurav Jain
One of the key goals for Harness CI is to enable our customers to run faster builds at scale.
The purpose of this tutorial is to give insights into the architecture for Harness CI and talk about the major design decisions taken to handle scale with reliability and resilience.
Typical CI flow
Let's understand a basic CI flow before diving into the details of the architecture.
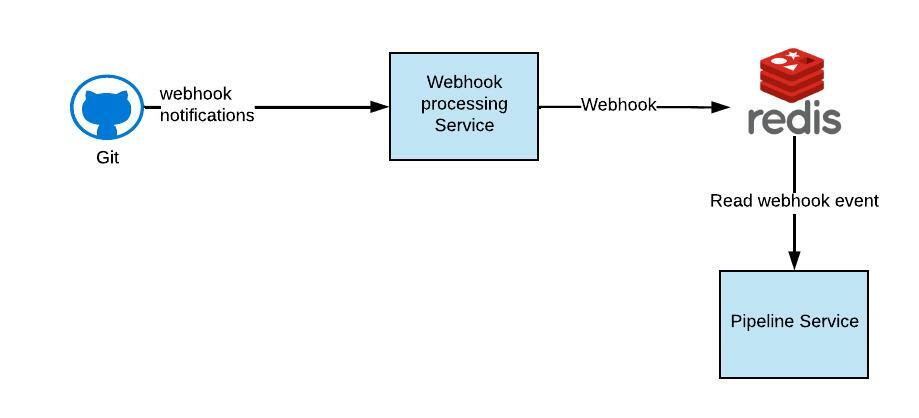
Receive the webhook from the source code manager (SCM) provider.
Create a build pod and clone the code.
Build the code.
Run tests.
Send test results.
Update the status of the build pipeline back to developer PR.
Here is a pictorial representation of the above flow
Harness CI Architecture
CI platform consists of a set of microservices in the backend and these services are used for the core platform functions (pipelines, user management, authentication, authorization, audit trails, secrets etc.). All the other Harness modules follow the same overall architecture and get connected through the pipeline.
The overall Harness CI platform has a lot of components and microservices, and the diagram below only shows the ones that are relevant to this post.
The core design of CI is guided by the following principles:
Simple: It’s designed not just for DevOps engineers but also for everyone in the team who should be able to use Harness CI to quickly and easily create and execute pipelines.
Extensible: Maintain loose coupling between the microservices, and encapsulate the core logic in the microservice itself. New functionality and modules can be added immediately without impacting other components.
Scalable: It should scale automatically as we onboard more customers and each of them should be able to run thousands of builds a day.
Highly Reliable: The system should be highly reliable and builds should not fail even under heavy load.
Let us now deep dive into how we apply these principles to scale our systems, delegates/runners.
Scaling With Microservices
An important part of running Harness Infra is ensuring our services are highly available and they automatically scale up with demand. Our traffic fluctuates depending on the day and time of the day, and our cloud footprint should scale dynamically to support this.
To support this scaling, Harness utilizes GCP hosted Kubernetes cluster to run all of our microservices on different pods. More details of Harness deployment architecture are in a separate blog.
All the external traffic and requests reach the gateway first for sanitization and authentication before communicating to services via configured Ingress rules.
We make sure that we follow scalability best practices for distributed systems across all microservices.
All the inter-microservice communication is asynchronous via message queue or with event-driven architecture to handle peak load. This also provides a seamless pipeline execution experience without any system issues.
We enable auto-scaling for all the microservices to avoid bottlenecks during peak load.
We set up rate limits per account based on the license to prevent impact on other customer executions.
All microservices have separate databases to avoid bottlenecks.
We use fully managed solutions such as MongoDB, Redis enterprise, and GCP Kubernetes to scale on-demand without any operational overhead.
All our microservices are stateless and scale horizontally to support peak load.
Disaster Recovery - Harness also keeps a failover cluster handy in different availability zones to recover quickly from any disaster.
Scaling Tens of Millions of Webhooks Generated by SCM Providers in a Day
Webhook processing service handles all incoming webhooks by putting them in a Redis queue for asynchronous processing by the pipeline service built for handling end-to-end pipeline executions.
We send acknowledgement to SCM provider by writing a webhook in MongoDB for persistence in case we have to replay and also push it to redis queue for asynchronous processing by pipeline service which starts the execution by creating an execution plan by validating all the provided inputs.
Majority of the pipeline executions in Harness CI get triggered via webhook from SCM providers. Recently we built an additional layer of reliability into webhook handling by creating a git polling framework to handle cases where webhooks fail to reach Harness because of any network issues.
Our delegate keeps polling scm providers via api to find unprocessed webhooks. Delegate agent sends unprocessed webhook to Harness service if any for processing.
Scaling Pipelines Executions
Pipeline microservice is the entry point for starting the pipeline execution. Pipeline service starts execution by first creating a plan by validating all the given inputs and then, starts the build by executing one step at a time.
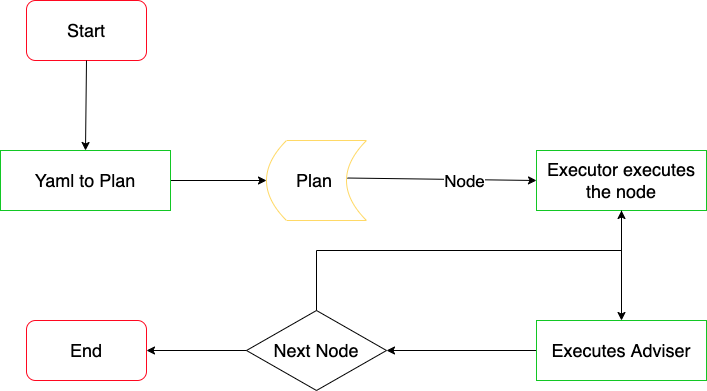
The below diagram shows a high level view of how the pipeline execution works:
Pipeline execution is a 2 step process to provide scalability and reliability.
1. Plan creation Pipeline execution starts with plan creation which converts pipeline yaml to execution graph along with all the required nodes.
A few important designs taken during plan creation for better scaling and performance:
Plan creation happens in parallel in multiple threads for better performance.
We store the complete plan in mongodb and then start the execution asynchronously to avoid any failure in case the service pod gets restarted.
2. Plan Execution
Once the plan creation is complete, we start with the pipeline execution asynchronously.
A few important design decision taken during plan execution for better scaling and performance:
Each plan node executes on a respective module microservice asynchronously backed by a Redis based queue.
All the created delegate tasks during execution are asynchronous. We don’t have any blocking calls on delegates so it gives us the liberty to scale well in case a delegate task takes more time.
All redis consumers are configurable and we can increase consumers based on the load we expect on our services.
In order to decouple our executions and visualization layer, we calculate our visualization graph asynchronously by observing the mongo updates on our main collection and performing an update on our graph. We use event sourcing for keeping the graph consistent with the execution and this also gives the ability to replay the event in order to generate the graph.
Scaling delegate agents installed in customer infrastructure
Harness delegate agent gets installed in customer infrastructure as a stateful set and we have following guards in place to handle failures and scale them in case of heavy load.
There are multiple ways Delegate(s) can be deployed; one of the most commonly used ways is stateful set.
One can provide auto scaling parameters for the delegate's pod, to handle peak load or else they themselves can deploy multiple delegate instances depending on the regular load.
Delegate manager maintains threshold limits for currently executing tasks per delegate, in order to avoid overwhelming single instance.
Delegate manager also perform admission controlling i.e. deliver the task to a delegate which has the maximum resources to execute it, instead broadcasting it blindly.
Watcher process is present along with a delegate to maintain high availability, to bring up the delegate process in case it goes down or freezes.
Each task which executes on delegate, comes with a timeout. This to avoid infinitely long running jobs.
Watcher process also provides maintainability, upgrades / downgrades delegate version when needed.
Scaling Infrastructure for running build jobs
Harness CI leaverages k8 to improve the efficiency of deploying, scaling, and managing pods.
Few advantages of using kubernetes infrastructure
Kubernetes automatically schedules pods to nodes based upon the available resources in the nodepool. Advantage of using kubernetes infrastructure is that the scheduler selects an optimal node for the pod to run.
Kubernetes infra also provides auto scaling capability and nodepool size changes dynamically based upon the load.
In a cluster, Nodes that meet the scheduling requirements for a Pod are called feasible nodes. If none of the nodes are suitable, the pod remains unscheduled until the scheduler is able to place it and build pipeline execution does not fail in case resources are not available during peak load time.
Separate node pools can be created as per resource requirements to run build.
We also support scalable ephemeral VMs, Docker based runners, Harness hosted infra in addition to the customer hosted K8S based offering.
Handling monitoring and alerting of complete Harness CI application
Each microservice has separate monitoring and alerting to keep track of the health. Few of the tools which we use for monitoring and alerting.
AppDynamics to monitor and alert on ART for APIs.
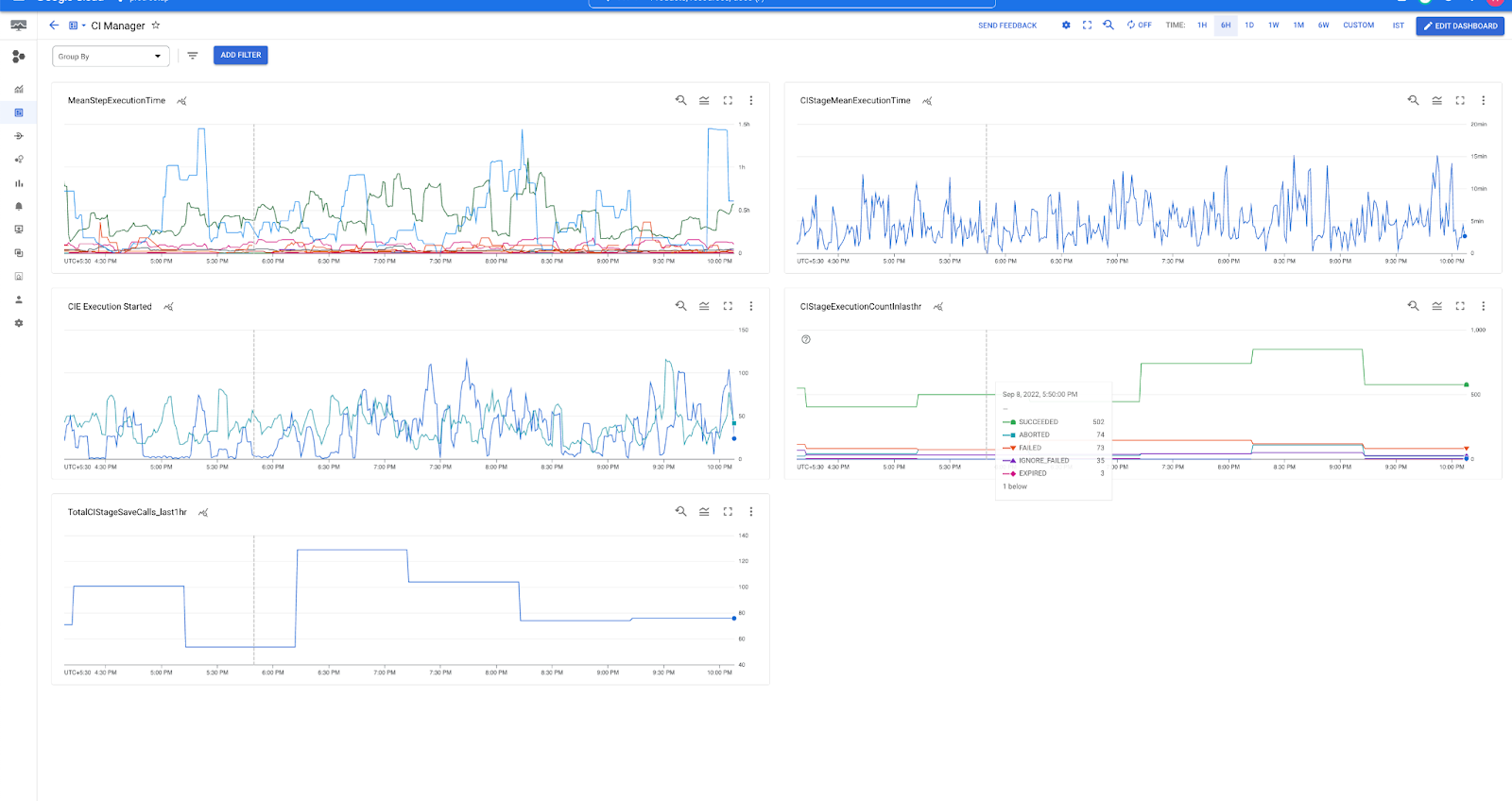
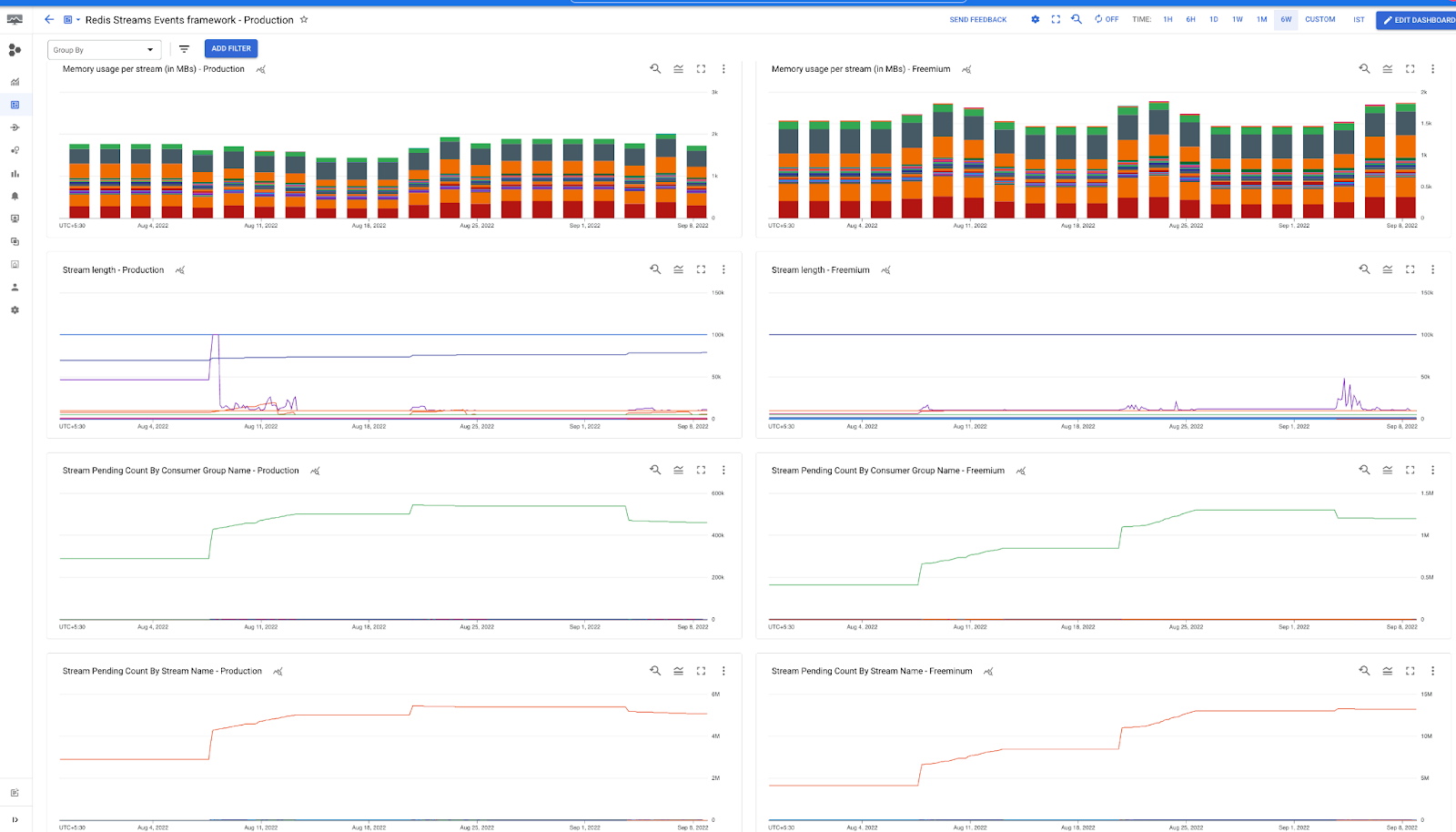
Stackdriver to run queries on logs and to monitor metrics published by open census. Below is the screenshot for pipeline service health metrics which monitors pipeline execution status along with average step, stage execution time and status. It also alerts in case failure count breaches configured threshold.
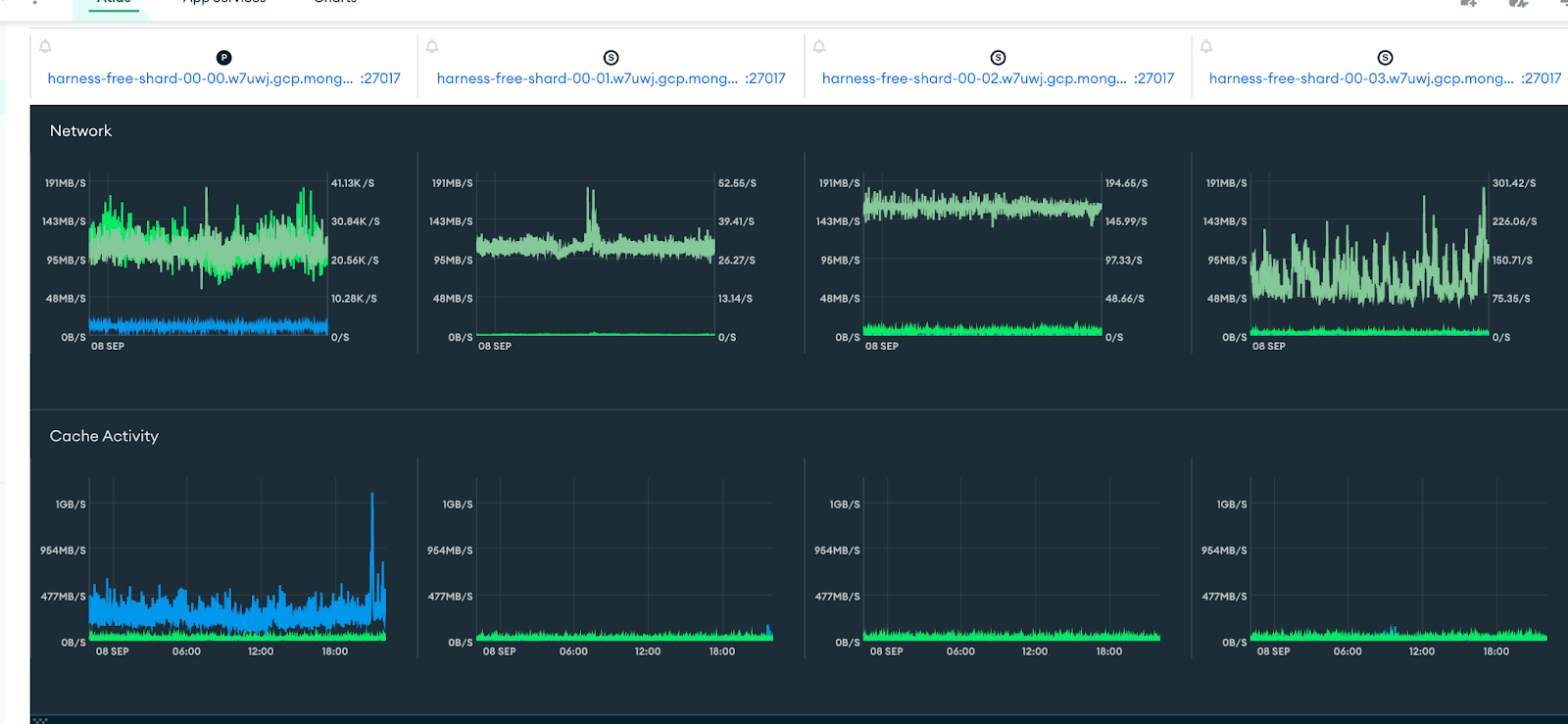
MongoDBandRedismetrics provided for the fully managed enterprise account. It also alerts in case read/write latency increases beyond defined threshold.
Conclusion
We were able to scale to a million builds per day in our last round of scalability testing on a weekday on our main production environment. Our services and build infra were able to scale seamlessly to handle the surge load without impacting any customer execution.
We’ve come a long way in a year by launching multiple modules, and we still have a number of interesting things on the horizon. Our architecture will keep evolving however, we will keep laser focused on providing top notch reliability, scalability and resilience along with a world class user experience.
.svg)






.png)


