Harness Blog
Featured Blogs

Today, Harness is announcing the General Availability of Artifact Registry, a milestone that marks more than a new product release. It represents a deliberate shift in how artifact management should work in secure software delivery.
For years, teams have accepted a strange reality: you build in one system, deploy in another, and manage artifacts somewhere else entirely. CI/CD pipelines run in one place, artifacts live in a third-party registry, and security scans happen downstream. When developers need to publish, pull, or debug an artifact, they leave their pipelines, log into another tool, and return to finish their work.
It works, but it’s fragmented, expensive, and increasingly difficult to govern and secure.
At Harness, we believe artifact management belongs inside the platform where software is built and delivered. That belief led to Harness Artifact Registry.
A Startup Inside Harness
Artifact Registry started as a small, high-ownership bet inside Harness and a dedicated team with a clear thesis: artifact management shouldn’t be a separate system developers have to leave their pipelines to use. We treated it like a seed startup inside the company, moving fast with direct customer feedback and a single-threaded leader driving the vision.The message from enterprise teams was consistent: they didn’t want to stitch together separate tools for artifact storage, open source dependency security, and vulnerability scanning.
So we built it that way.
In just over a year, Artifact Registry moved from concept to core product. What started with a single design partner expanded to double digit enterprise customers pre-GA – the kind of pull-through adoption that signals we've identified a critical gap in the DevOps toolchain.
Today, Artifact Registry supports a broad range of container formats, package ecosystems, and AI artifacts, including Docker, Helm (OCI), Python, npm, Go, NuGet, Dart, Conda, and more, with additional support on the way. Enterprise teams are standardizing on it across CI pipelines, reducing registry sprawl, and eliminating the friction of managing diverse artifacts outside their delivery workflows.
One early enterprise customer, Drax Group, consolidated multiple container and package types into Harness Artifact Registry and achieved 100 percent adoption across teams after standardizing on the platform.
As their Head of Software Engineering put it:
"Harness is helping us achieve a single source of truth for all artifact types containerized and non-containerized alike making sure every piece of software is verified before it reaches production." - Jasper van Rijn
Why This Matters: The Registry as a Control Point
In modern DevSecOps environments, artifacts sit at the center of delivery. Builds generate them, deployments promote them, rollbacks depend on them, and governance decisions attach to them. Yet registries have traditionally operated as external storage systems, disconnected from CI/CD orchestration and policy enforcement.
That separation no longer holds up against today’s threat landscape.
Software supply chain attacks are more frequent and more sophisticated. The SolarWinds breach showed how malicious code embedded in trusted update binaries can infiltrate thousands of organizations. More recently, the Shai-Hulud 2.0 campaign compromised hundreds of npm packages and spread automatically across tens of thousands of downstream repositories.
These incidents reveal an important business reality: risk often enters early in the software lifecycle, embedded in third-party components and artifacts long before a product reaches customers.When artifact storage, open source governance, and security scanning are managed in separate systems, oversight becomes fragmented. Controls are applied after the fact, visibility is incomplete, and teams operate in silos. The result is slower response times, higher operational costs, and increased exposure.
We saw an opportunity to simplify and strengthen this model.

By embedding artifact management directly into the Harness platform, the registry becomes a built-in control point within the delivery lifecycle. RBAC, audit logging, replication, quotas, scanning, and policy enforcement operate inside the same platform where pipelines run. Instead of stitching together siloed systems, teams manage artifacts alongside builds, deployments, and security workflows. The outcome is streamlined operations, clearer accountability, and proactive risk management applied at the earliest possible stage rather than after issues surface.
Introducing Dependency Firewall: Blocking Risk at Ingest
Security is one of the clearest examples of why registry-native governance matters.
Artifact Registry delivers this through Dependency Firewall, a registry-level enforcement control applied at dependency ingest. Rather than relying on downstream CI scans after a package has already entered a build, Dependency Firewall evaluates dependency requests in real time as artifacts enter the registry. Policies can automatically block components with known CVEs, license violations, excessive severity thresholds, or untrusted upstream sources before they are cached or consumed by pipelines.
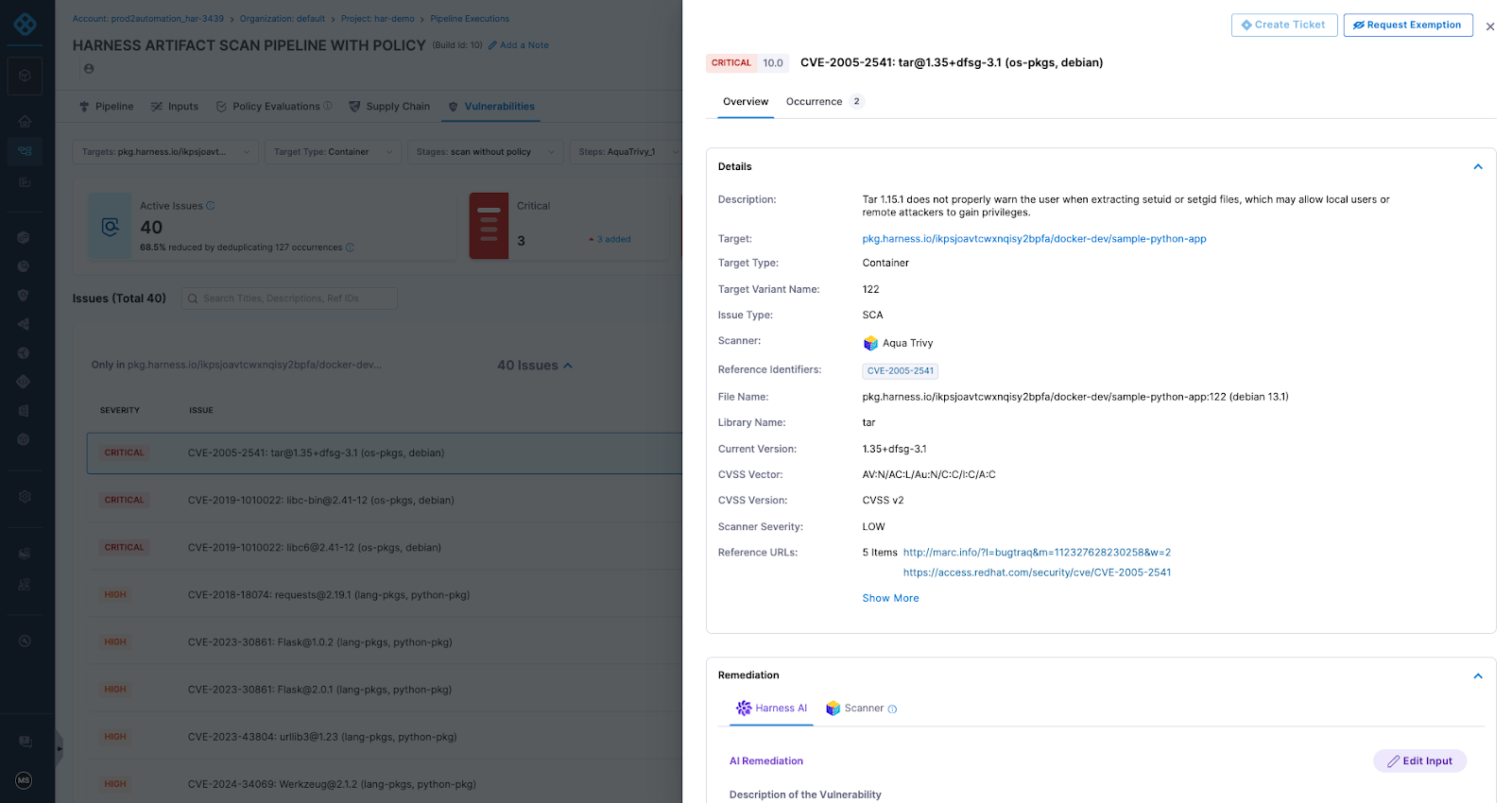
Artifact quarantine extends this model by automatically isolating artifacts that fail vulnerability or compliance checks. If an artifact does not meet defined policy requirements, it cannot be downloaded, promoted, or deployed until the issue is addressed. All quarantine and release actions are governed by role-based access controls and fully auditable, ensuring transparency and accountability. Built-in scanning powered by Aqua Trivy, combined with integrations across more than 40 security tools in Harness, feeds results directly into policy evaluation. This allows organizations to automate release or quarantine decisions in real time, reducing manual intervention while strengthening control at the artifact boundary.
The result is a registry that functions as an active supply chain control point, enforcing governance at the artifact boundary and reducing risk before it propagates downstream.
The Future of Artifact Management is here
General Availability signals that Artifact Registry is now a core pillar of the Harness platform. Over the past year, we’ve hardened performance, expanded artifact format support, scaled multi-region replication, and refined enterprise-grade controls. Customers are running high-throughput CI pipelines against it in production environments, and internal Harness teams rely on it daily.
We’re continuing to invest in:
- Expanded package ecosystem support
- Advanced lifecycle management, immutability, and auditing
- Deeper integration with Harness Security and the Internal Developer Portal
- AI-powered agents for OSS governance, lifecycle automation, and artifact intelligence
Modern software delivery demands clear control over how software is built, secured, and distributed. As supply chain threats increase and delivery velocity accelerates, organizations need earlier visibility and enforcement without introducing new friction or operational complexity.
We invite you to sign up for a demo and see firsthand how Harness Artifact Registry delivers high-performance artifact distribution with built-in security and governance at scale.

TLDR: We have rolled out Project Movement: the ability to transfer entire Harness projects between Organizations with a few clicks. It's been our most-requested Platform feature for a reason. Your pipelines, configurations, and rest come along for the ride.
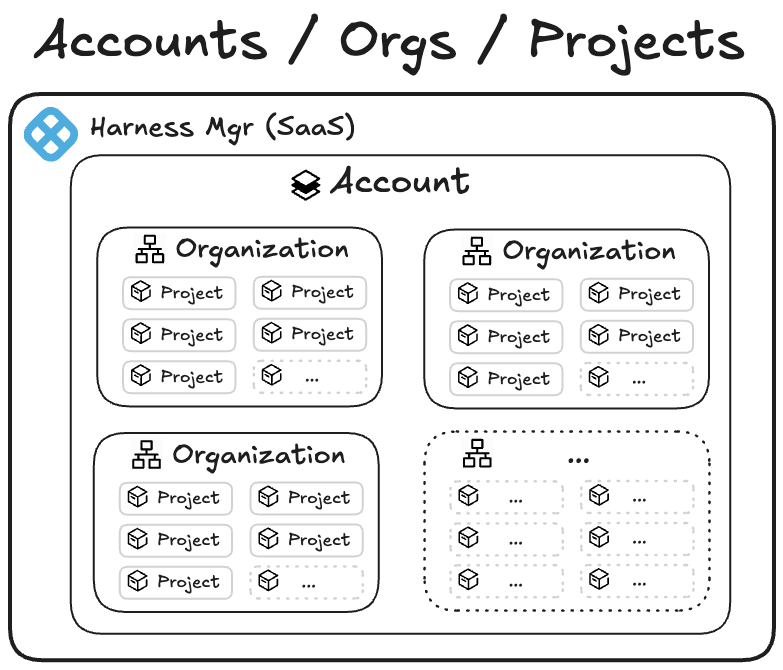
What are Projects and Organizations?
In Harness, an Account is the highest-scoped entity. It contains organizations and projects. An organization is the space that represents your business unit or team and helps you manage users, access, and shared settings in one place. Within an organization, a project is where your teams do their day-to-day work, such as building pipelines, managing services, and tracking deployments. Projects keep related resources grouped together, making it easier to collaborate, control permissions, and scale across teams.
The main benefit of keeping organizations and projects separate is strong isolation and predictability. By not allowing projects to move between organizations, you can ensure that each organization serves as a rigid boundary for security, RBAC, governance, billing, and integrations. Customers could trust that once a project was created within an org, all its permissions, secrets, connectors, audit history, and compliance settings would remain stable and wouldn’t be accidentally inherited or lost during a move. This reduced the risk of misconfiguration, privilege escalation, broken pipelines, or compliance violations — especially for large enterprises with multiple business units or regulated environments.
However, imagine this scenario: last quarter, your company reorganized around customer segments. This quarter, two teams merged. Next quarter, who knows—but your software delivery shouldn't grind to a halt every time someone redraws the org chart.
We've heard this story from dozens of customers: the experimental project that became critical, the team consolidation that changed ownership, the restructure that reshuffled which team owns what. And until now, moving a Harness project from one Organization to another meant one thing: start from scratch.
Not anymore.
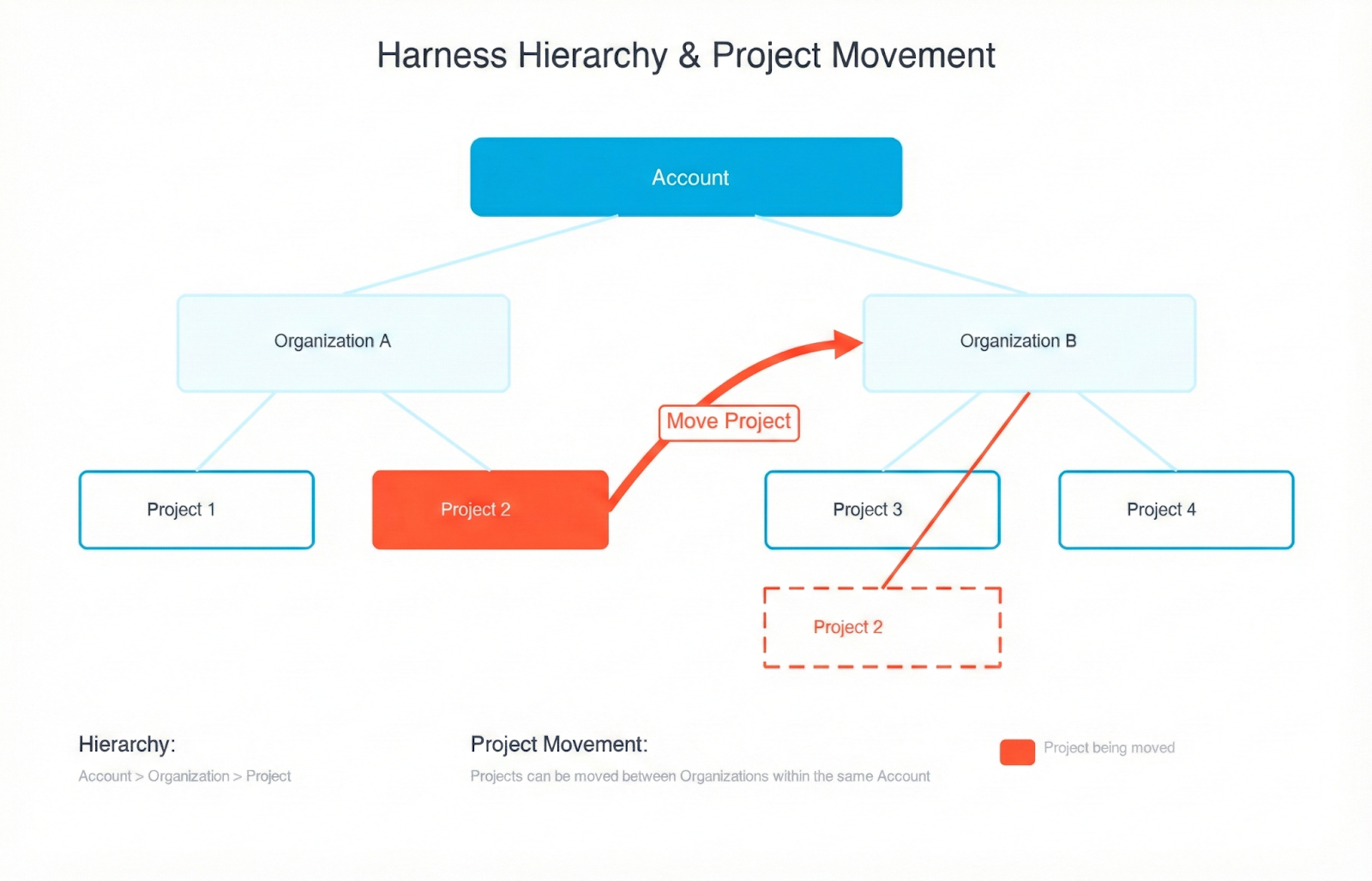
That’s why we have rolled out Project Movement—the ability to transfer entire Harness projects between Organizations with a few clicks. It's been our most-requested Platform feature for a reason. Your pipelines, configurations, and rest come along for the ride.
What Moving a Project Actually Feels Like
You're looking at 47 pipelines, 200+ deployment executions, a dozen services, and countless hours of configuration work. The company's org chart says this project now belongs to a different team. Deep breath.
Click the menu. Select "Move Project." Pick your destination Organization.
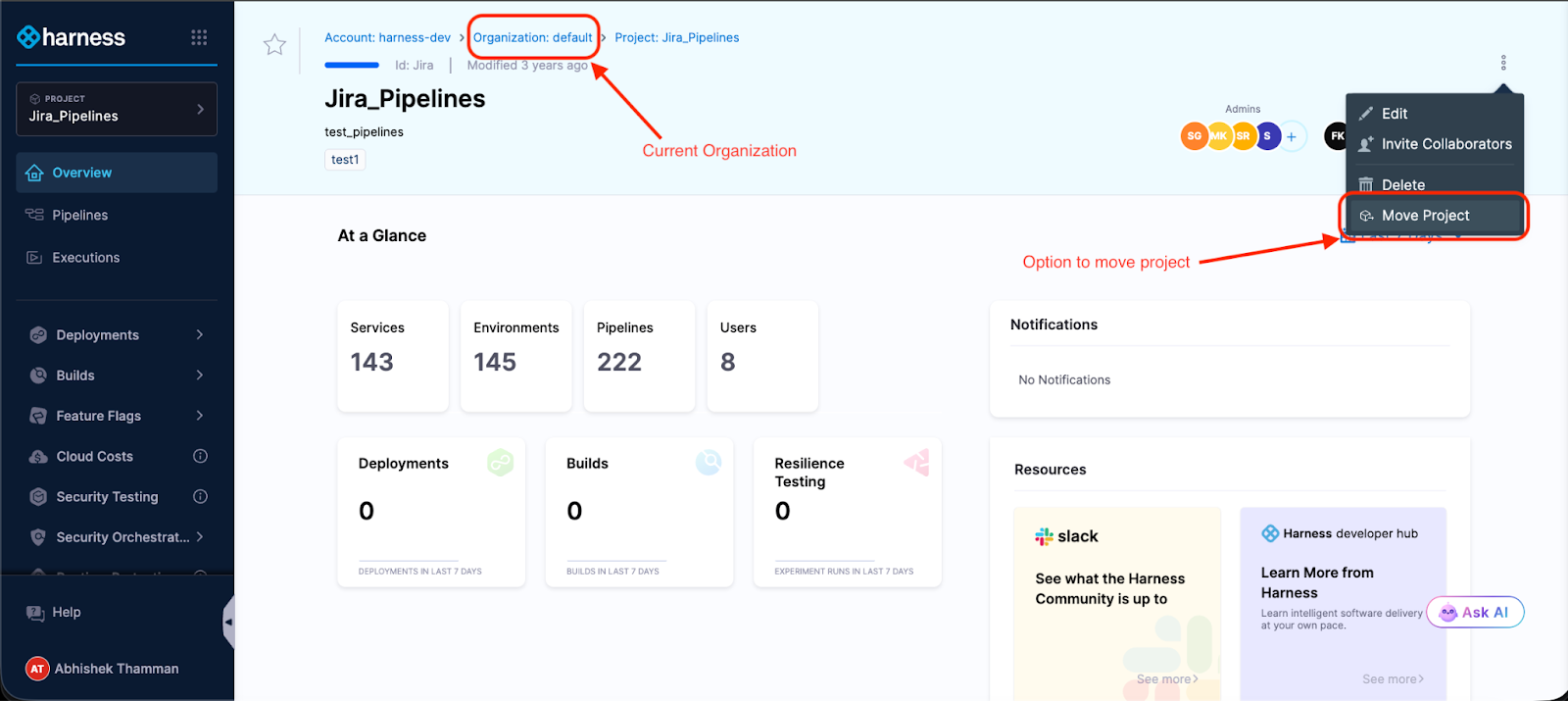
The modal shows you what might break—Organization-level connectors, secrets, and templates that the project references. Not an exhaustive list, but enough to know what you're getting into.

Type the project identifier to confirm.
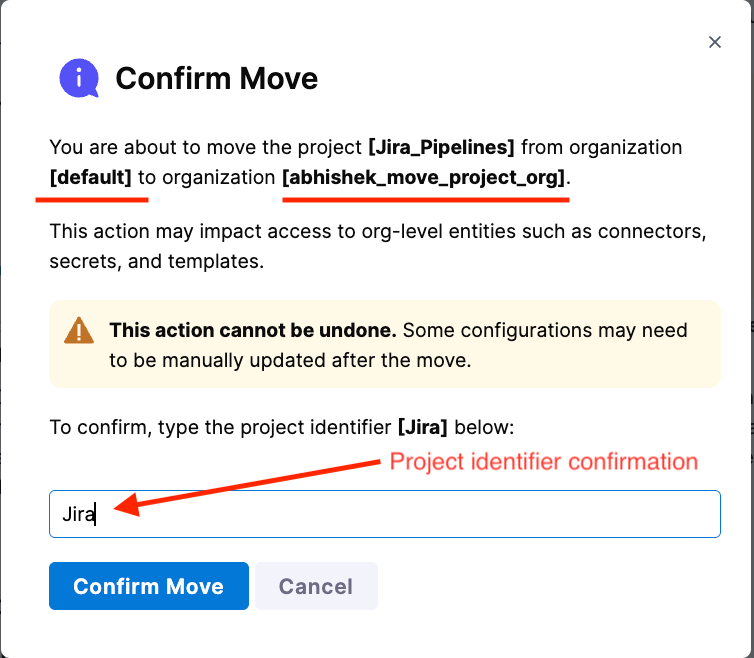
Done.
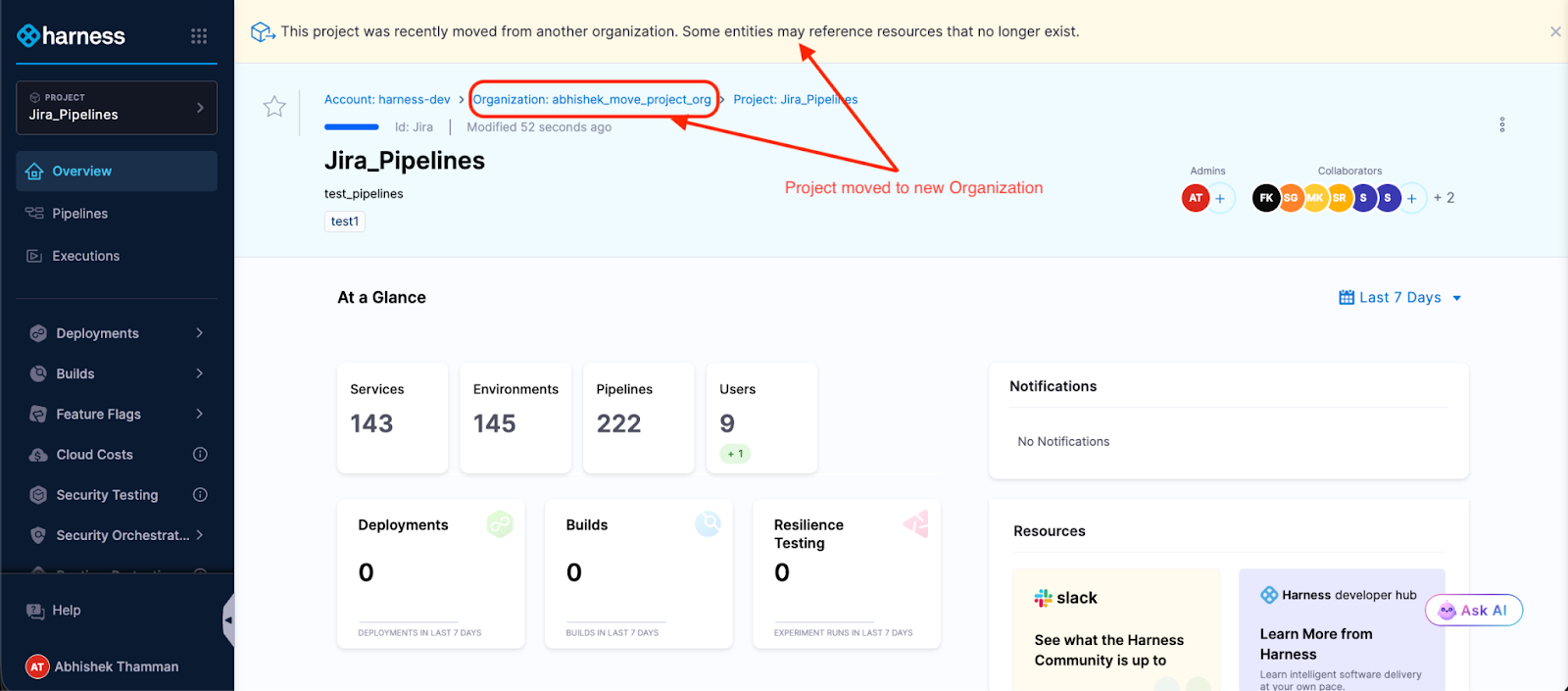
Your project is now in its new Organization. Pipelines intact. Execution history preserved. Templates, secrets, connectors—all right where you left them. The access control migration happens in the background while you grab coffee.
What used to take days of YAML wrangling and "did we remember to migrate X?" conversations now takes minutes.
To summarize:
To move a Harness project between organizations:
1. Open the project menu and select “Move Project.”
2. Choose the destination organization.
3. Review impacted organization-level resources.
4. Confirm by typing the project identifier.
5. Monitor access control migration while pipelines remain intact.
What Moves with Projects
Here's what transfers automatically when you move a project:
- Platform - Your pipelines with their full execution history, all triggers and input sets, services and environments, project-scoped connectors, secrets, templates, delegates, and webhooks.
- Continuous Delivery (CD) - All your deployment workflows, service definitions, and infrastructure configurations. If you built it for continuous delivery, it moves.
- Continuous Integration (CI) - Build configurations, test intelligence settings, and the whole CI setup.
- Internal Developer Portal (IDP) - Service catalog entries and scorecards.
- Security Test Orchestration (STO) - Scan configurations and security testing workflows.
- Code Repository - Repository settings, configurations, and more.
- Database DevOps - Database schema management configurations and more.
Access control follows along too: role bindings, service accounts, user groups, and resource groups. This happens asynchronously, so the move doesn't block, but you can track progress in real-time.
The project becomes immediately usable in its new Organization. No downtime, no placeholder period, no "check back tomorrow."
What doesn’t Move with Projects?
Let's talk about what happens to Organization-level resources and where you'll spend some time post-move.
Organization-scoped resources don't move—and that makes sense when you think about it. That GitHub connector at the Organization level? It's shared across multiple projects. We can't just yank it to the new Organization. So after moving, you'll update references that pointed to:
- Organization-level connectors (GitHub, Docker Hub, cloud providers)
- Organization-level secrets (API keys, credentials)
- Organization-level templates (shared pipeline components)
- User groups inherited from the source Organization
After the move, you'll update these references in your pipelines and configurations. Click the resource field, select a replacement from the new Organization or create a new one, and save. Rinse and repeat. The pre-move and post-move guide walks through the process.
A few CD features aren't supported yet, but on the roadmap: GitOps entities, and Continuous Verification don't move with the project. If your pipelines use these, you'll need to manually reconfigure them in the new Organization after the move. The documentation has specific guidance on supported modules and entities.
Security Boundaries Stay Intact
The Harness hierarchical model, Account > Organization > Project, exists for strong isolation and predictable security boundaries. Moving projects doesn't compromise that architecture. Here's why: Organization-level resources stay put. Your GitHub connectors, cloud credentials, and secrets remain scoped to their Organizations. When a project moves, it doesn't drag sensitive org-wide resources along; it references new ones in the destination. This means your security boundaries stay intact, RBAC policies remain predictable, and teams can't accidentally leak credentials across organizational boundaries. The project moves. The isolation doesn't.
An Example of Moving Projects
A platform engineering team had a familiar problem: three different product teams each had their own Harness Organization with isolated projects. Made sense when the teams were autonomous. But as the products matured and started sharing infrastructure, the separation became friction.
The platform team wanted to consolidate everything under a single "Platform Services" Organization for consistent governance and easier management. Before project movement, that meant weeks of work—export configurations, recreate pipelines, remap every connector and secret, test everything, hope nothing broke.
With project movement, they knocked it out in an afternoon. Move the projects. Update references to Organization-level resources. Standardize secrets across the consolidated projects. Test a few deployments. Done.
The product teams kept shipping. The platform team got its unified structure. Nobody lost weeks to migration work.
Try It (With Smart Guardrails)
Moving a project requires two permissions: Move on the source project and Create Project in the destination Organization. Both sides of the transfer need to agree—you can't accidentally move critical projects out of an Organization or surprise a team with unwanted projects.
When you trigger a move, you'll type the project identifier to confirm.
A banner sticks around for 7 days post-move, reminding you to check for broken references. Use that week to methodically verify everything, especially if you're moving a production project.
Our recommendation: Try it with a non-production project first. Get a feel for what moves smoothly and what needs attention. Then tackle the production stuff with confidence.
Why This Took Time (A Peek Behind the Scenes)
On the surface, moving a project sounds simple-just change where it lives, and you’re done. But in reality, a Harness project is a deeply connected system.
Your pipelines, execution history, connectors, secrets, and audit logs are all tied together behind the scenes. Historically, Harness identified these components using their specific "address" in the hierarchy. That meant if a project moved, every connected entity would need its address updated across multiple services at the same time. Doing that safely without breaking history or runtime behavior was incredibly risky.
To solve this, we re-architected the foundation.
We stopped tying components to their location and introduced stable internal identifiers. Now, every entity has a unique ID that travels with it, regardless of where it lives. When you move a project, we simply update its parent relationship. The thousands of connected components inside don’t even realize they’ve moved.
This architectural shift is what allows us to preserve your execution history and audit trails while keeping project moves fast and reliable.
What's Coming
This is version one. The foundations are solid: projects move, access control migrates, pipelines keep running. But we're not done.
We're listening. If you use this feature and hit rough edges, we want to hear about it.
The Bottom Line
Organizational change is inevitable. The weeks of cleanup work afterward don't have to be.
Project Movement means your Harness setup can adapt as fast as your org chart does. When teams move, when projects change ownership, when you consolidate for efficiency, your software delivery follows without the migration overhead.
No more lost history. No more recreated pipelines. No more week-long "let's just rebuild everything in the new Organization" projects.
Ready to try it? Check out the step-by-step guide or jump into your Harness account and look for "Move Project" in the project menu.

At Harness, our story has always been about change — helping teams ship faster, deploy safer, and control the blast radius of every modification to production. Deployments, feature flags, pipelines, and governance are all expressions of how organizations evolve their software.
Today, the pace of change is accelerating. As AI-assisted development becomes the norm, more code reaches production faster, often without a clear link to the engineer who wrote it. Now, Day 2 isn’t just supporting the unknown – it’s supporting software shaped by changes that may not have a clear human owner.
And as every SRE and on-call engineer knows, even rigorous change hygiene doesn’t prevent incidents because real-world systems don’t fail neatly. They fail under load, at the edges, in the unpredictable ways software meets traffic patterns, caches, databases, user behavior, and everything in between.
When that happens, teams fall back on what they’ve always relied on: Human conversation and deep understanding of what changed.
That’s why today we’re excited to introduce the Harness Human-Aware Change Agent — the first AI system designed to treat human insight as operational data and use it to drive automated, change-centric investigation during incidents.
Not transcription plus RCA. One unified intelligence engine grounded in how incidents actually unfold.
📞 A Quick Look at Harness AI SRE
The Human-Aware Change Agent is part of Harness AI SRE — a unified incident response system built to help teams resolve incidents faster without scaling headcount. AI SRE brings together the critical parts of response: capturing context, coordinating action, and operationalizing investigation.
At the center is the AI Scribe, because the earliest and most important clues in an incident often surface in conversation before they appear in dashboards. Scribe listens across an organization’s tools with awareness of the incident itself – filtering out unrelated chatter and capturing only the decisions, actions, and timestamps that matter. The challenge isn’t producing a transcript; it’s isolating the human signals responders actually use.
Those signals feed directly into the Human-Aware Change Agent, which drives change-centric investigation during incidents.
And once that context exists, AI SRE helps teams act on it: Automation Runbooks standardize first response and remediation, while On-Call and Escalations ensure incidents reach the right owner immediately.
AI SRE also fits into the tools teams already run — with native integrations and flexible webhooks that connect observability, alerting, ticketing, and chat across systems like Datadog, PagerDuty, Jira, ServiceNow, Slack, and Teams.
🌐 Why We Built a Human-Aware Change Agent
Most AI approaches to SRE assume incidents can be solved entirely through machine signals — logs, metrics, traces, dashboards, anomaly detectors. But if you’ve ever been on an incident bridge, you know that’s not how reality works.
Some of the most important clues come from humans:
- “The customer said the checkout button froze right after they updated their cart.”
- “Service X felt slow an hour before this started.”
- “Didn’t we flip a flag for the recommender earlier today?”
- “This only happens in the US-East cluster.”
These early observations shape the investigation long before anyone pulls up a dashboard.
Yet most AI tools never hear any of that.
The Harness Human-Aware Change Agent changes this. It listens to the same conversations your engineers are having — in Slack, Teams, Zoom bridges — and transforms the human story of the incident into actionable intelligence that guides automated change investigation.
It is the first AI system that understands both what your team is saying and what your systems have changed — and connects them in real time.
🔍 How the Human-Aware Change Agent Works
1. It listens and understands human context.
Using AI Scribe as its conversational interface, the agent captures operational signals from a team’s natural dialogue – impacted services, dependencies, customer-reported symptoms, emerging theories or contradictions, and key sequence-of-events clues (“right before…”).
The value is in recognizing human-discovered clues, and converting them into signals that guide next steps.
2. It investigates changes based on those clues.
The agent then uses these human signals to direct investigation across your full change graph including deployments, feature flags or config changes, infrastructure updates, and ITSM change records – triangulating what engineers are seeing with what is actually changing in your production environment.
3. It surfaces evidence-backed hypotheses.
Instead of throwing guesses at the team, it produces clear, explainable insights:
“A deployment to checkout-service completed 12 minutes before the incident began. That deploy introduced a new retry configuration for the payment adapter. Immediately afterward, request latency started climbing and downstream timeouts increased.”
Each hypothesis comes with supporting data and reasoning, allowing teams to quickly validate or discard theories.
4. It helps teams act faster and safer
By uniting human observations with machine-driven change intelligence, the agent dramatically shortens the path from:
What are we seeing? → What changed? → What should we do?
Teams quickly gain clarity on where to focus, what’s most suspicious, and which rollback or mitigation actions exist and are safest.
🌅 A New Era of Incident Response
With this release, Harness is redefining what AI for incident management looks like.
Not a detached assistant. Not a dashboard summarizer. But a teammate that understands what responders are saying, investigates what systems have changed, connects the dots, and helps teams get to truth faster.
Because the future of incident response isn’t AI working alone. It’s AI working alongside engineers — understanding humans and systems in equal measure.
Book a demo of Harness AI SRE to see how human insight and change intelligence come together during real incidents.
Blog Library

When Faster Code Starts to Break the Delivery System
Over the last few years, something fundamental has changed in software development.
If the early 2020s were about adopting AI coding assistants, the next phase is about what happens after those tools accelerate development. Teams are producing code faster than ever. But what I’m hearing from engineering leaders is a different question:
What’s going to break next?
That question is exactly what led us to commission our latest research, State of DevOps Modernization 2026. The results reveal a pattern that many practitioners already sense intuitively: faster code generation is exposing weaknesses across the rest of the software delivery lifecycle.
In other words, AI is multiplying development velocity, but it’s also revealing the limits of the systems we built to ship that code safely.
The Emerging “Velocity Paradox”
One of the most striking findings in the research is something we’ve started calling the AI Velocity Paradox - a term we coined in our 2025 State of Software Engineering Report.
Teams using AI coding tools most heavily are shipping code significantly faster. In fact, 45% of developers who use AI coding tools multiple times per day deploy to production daily or faster, compared to 32% of daily users and just 15% of weekly users.
At first glance, that sounds like a huge success story. Faster iteration cycles are exactly what modern software teams want.
But the data tells a more complicated story.
Among those same heavy AI users:
- 69% report frequent deployment problems when AI-generated code is involved
- Incident recovery times average 7.6 hours, longer than for teams using AI less frequently
- 47% say manual downstream work, QA, validation, remediation has become more problematic
What this tells me is simple: AI is speeding up the front of the delivery pipeline, but the rest of the system isn’t scaling with it. It’s like we are running trains faster than the tracks they are built for. Friction builds, the ride is bumpy, and it seems we could be on the edge of disaster.

The result is friction downstream, more incidents, more manual work, and more operational stress on engineering teams.
Why the Delivery System Is Straining
To understand why this is happening, you have to step back and look at how most DevOps systems actually evolved.
Over the past 15 years, delivery pipelines have grown incrementally. Teams added tools to solve specific problems: CI servers, artifact repositories, security scanners, deployment automation, and feature management. Each step made sense at the time.
But the overall system was rarely designed as a coherent whole.
In many organizations today, quality gates, verification steps, and incident recovery still rely heavily on human coordination and manual work. In fact, 77% say teams often have to wait on other teams for routine delivery tasks.
That model worked when release cycles were slower.
It doesn’t work as well when AI dramatically increases the number of code changes moving through the system.
Think of it this way: If AI doubles the number of changes engineers can produce, your pipelines must either:
- cut the risk of each change in half, or
- detect and resolve failures much faster.
Otherwise, the system begins to crack under pressure. The burden often falls directly on developers to help deploy services safely, certify compliance checks, and keep rollouts continuously progressing. When failures happen, they have to jump in and remediate at whatever hour.
These manual tasks, naturally, inhibit innovation and cause developer burnout. That’s exactly what the research shows.
Across respondents, developers report spending roughly 36% of their time on repetitive manual tasks like chasing approvals, rerunning failed jobs, or copy-pasting configuration.
As delivery speed increases, the operational load increases. That burden often falls directly on developers.
What Organizations Should Do Next
The good news is that this problem isn’t mysterious. It’s a systems problem. And systems problems can be solved.
From our experience working with engineering organizations, we've identified a few principles that consistently help teams scale AI-driven development safely.
1. Standardize delivery foundations
When every team builds pipelines differently, scaling delivery becomes difficult.
Standardized templates (or “golden paths”) make it easier to deploy services safely and consistently. They also dramatically reduce the cognitive load for developers.
2. Automate quality and security checks earlier
Speed only works when feedback is fast.
Automating security, compliance, and quality checks earlier in the lifecycle ensures problems are caught before they reach production. That keeps pipelines moving without sacrificing safety.
3. Build guardrails into the release process
Feature flags, automated rollbacks, and progressive rollouts allow teams to decouple deployment from release. That flexibility reduces the blast radius of new changes and makes experimentation safer.
It also allows teams to move faster without increasing production risk.
4. Remember measurement, not just automation
Automation alone doesn’t solve the problem. What matters is creating a feedback loop: deploy → observe → measure → iterate.
When teams can measure the real-world impact of changes, they can learn faster and improve continuously.
The Next Phase of AI in Software Delivery
AI is already changing how software gets written. The next challenge is changing how software gets delivered.
Coding assistants have increased development teams' capacity to innovate. But to capture the full benefit, the delivery systems behind them must evolve as well.
The organizations that succeed in this new environment will be the ones that treat software delivery as a coherent system, not just a collection of tools.
Because the real goal isn’t just writing code faster. It’s learning faster, delivering safer, and turning engineering velocity into better outcomes for the business.
And that requires modernizing the entire pipeline, not just the part where code is written.

Harness Artifact Registry: Your Unified OCI-Compliant Gateway for Secure Artifact Management
If you've worked with builds and deployments, then you already know how central Docker images, dependencies, and containers are to modern software delivery. The introduction of Docker revolutionised how we package and run software, while the Open Container Initiative (OCI) brought much-needed standardisation to container formats and distribution. Docker made containers mainstream; OCI made them universal.
Even though Docker Hub and private registries have served us well, they often introduce challenges at scale:
- Limited governance and control — OCI defines standards, but managing how standardised images are used, updated, and secured across environments is often left to manual processes.
- Security at the edge instead of by design — vulnerability scans and policy checks typically happen after the fact, leaving pipelines exposed to build failures or compromised dependencies.
- Exposure to supply chain risks — even perfectly built artifacts can fall victim to typosquatting or malicious dependency injection, quietly introducing malware into trusted environments.
And even after every dependency and sanity check passes, one question remains:
How effectively can you integrate and deploy artifacts through your CI/CD supply chain, without risking credential leaks or losing end-to-end visibility?
The Problems Are Clear — So Is the Solution
This is exactly where Harness Artifact Registry comes in.
Harness Artifact Registry is a cloud-native, secure artifact storage and management platform built for the future. Unlike traditional Docker registries or basic container registries, it's designed not just to store your Docker images and artifacts but also to actively secure and govern them. It's fully OCI-compliant, supporting Docker containers and other container formats natively, whilst integrating directly with CI/CD pipelines, policy engines, and vulnerability scanners.
Let me walk you through the complete journey of how an artifact moves through Harness Artifact Registry, from the moment you build it to when it's deployed in production.
The OCI-Compliant Artifact Journey
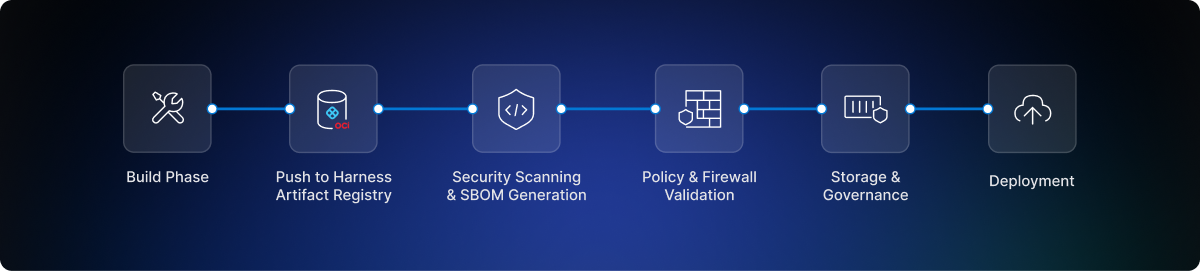
Docker Registry Client Setup
It all begins with the very first step after you build your Docker image on your system: storing it in a secure artifact storage layer through your container registry. Harness Artifact Registry supports more than 16 registry types and is fully OCI-compliant. You can simply use Docker to push the artifacts into the registry or even use the Harness CLI for it.
It is as simple as pushing to Docker Hub. Once you've authenticated with your Harness Artifact Registry, you can use standard Docker commands to push Docker images:
# Step 1: Tag the existing image (using its digest) with a new tag
docker tag <REGISTRY_URL>/<REPOSITORY>/<IMAGE_NAME>@<DIGEST> <REGISTRY_URL>/<REPOSITORY>/<IMAGE_NAME>:<NEW_TAG>
# Step 2: Push the newly tagged image to the registry
docker push <REGISTRY_URL>/<REPOSITORY>/<IMAGE_NAME>:<NEW_TAG>
Because Harness Artifact Registry is fully OCI-compliant, it works seamlessly with any OCI-compatible client. This means you don't need to learn new tools or change your existing Docker workflows. Whether you're migrating from Google Artifact Registry, Azure Container Registry, AWS ECR, or Docker Hub, the experience remains consistent.
Pulling from External Resources
We understand that a build requires many dependencies and versioning, with some even pulling from open-source repositories. These sources can vary significantly for enterprises. That's why we've made it easy to integrate custom registries so you can cache artifacts via a proxy.
Harness Artifact Registry allows you to configure upstream registries as remote repositories. This means you can:
- Cache dependencies locally to reduce external network calls and improve build times
- Control access to external Docker registries and artifact repositories through a single point of entry
- Scan external artifacts before they enter your environment
Apart from Docker Hub, Google Artifact Registry, and AWS ECR, you can set up custom registries with just a Remote Registry URL and basic authentication using a username and password. This proxy capability ensures that even when your teams pull Docker images from public registries, everything flows through Harness Artifact Registry first, giving you complete visibility, governance, and unified artifact storage control.
Security by Design
This is where Harness Artifact Registry truly shines. Rather than treating security as an afterthought, it's baked into every layer of the artifact lifecycle.
Built-in Container Scanners
Container vulnerability scanners detect security issues in your Docker images and container images before they can cause problems. Harness Artifact Registry integrates with industry-leading scanners like Aqua Trivy and Snyk, allowing you to automatically scan every artifact that enters your registry.
Here's what makes this powerful: when a Docker image is pushed, Harness automatically triggers a security pipeline that scans the artifact and generates a complete Software Bill of Materials (SBOM) along with detailed vulnerability reports. You get immediate visibility into:
- Known CVEs (Common Vulnerabilities and Exposures) with severity ratings
- All packages and libraries included in the Docker image
- Outdated dependencies and their versions
- Licence compliance issues
- Configuration vulnerabilities
The SBOM and vulnerability details are displayed directly in the Harness interface, giving you complete transparency into what's inside your containers and their security posture. This level of container security goes beyond what traditional Docker registries offer.
Dependency Firewall
When you're pulling dependencies from external sources through the upstream proxy, the Dependency Firewall actively blocks risky or unapproved packages before they even enter your registry. You can configure it to either block suspicious dependencies outright or set it to warn mode for your team to review. This means malicious dependencies are stopped at the gate, not discovered later in your pipeline.
Policy Sets
Beyond vulnerability scanning, you can assign policy sets to be evaluated against each artifact. These policies act as automated gatekeepers, enforcing your organisation's security and compliance requirements.
For example, you might create policies that:
- Block Docker images with critical vulnerabilities from being deployed
- Require all container images to be signed
- Enforce naming conventions for artifacts
- Mandate specific base images for Docker containers
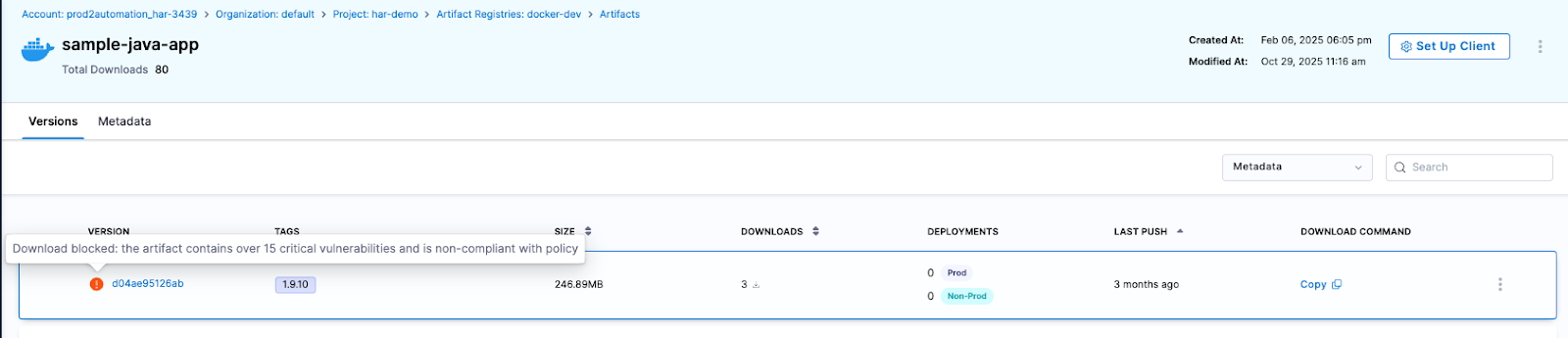
Policies are evaluated automatically, and non-compliant artifacts can be quarantined or blocked entirely.
Quarantine
When an artifact fails a security scan or violates a policy, it can be automatically quarantined. This prevents it from being used in deployments whilst still allowing your team to investigate and remediate the issues. This proactive approach significantly reduces your attack surface and ensures only verified artifacts make it to production.
Integrating with Harness CI/CD Pipelines
Your artifact is now ready, fully scanned for vulnerabilities, and stored securely in your container registry. This is where everything comes together for developers and platform engineers alike. The seamless integration between Harness Artifact Registry and Harness CI/CD pipelines means you can build Docker images, store artifacts, and deploy without context switching or managing complex credentials across multiple registry systems.

Building and Publishing with Harness CI
Harness CI is all about getting your code built, tested, and packaged efficiently. Harness Artifact Registry fits naturally into this workflow by providing native steps that eliminate the complexity of managing Docker registry credentials and connections.
Build and Push to Docker: This native CI step allows you to build your Docker images and push them directly to Harness Artifact Registry without any external connectors. The platform handles Docker registry authentication automatically, so you can focus on your build logic rather than credential management.
Upload artifacts: Beyond Docker images, you can publish Maven artifacts, npm packages, Helm charts, or generic files directly to Harness Artifact Registry. This unified artifact management approach means all your build outputs live in one place, with consistent vulnerability scanning and policy enforcement across every artifact type.
The essence here is simplicity: your CI pipeline produces artifacts and Docker containers, and they're automatically stored, scanned, and made available for deployment, all within the same platform.
Deploying with Harness CD
Every deployment needs an artifact. Whether you're deploying Docker containers to Kubernetes, AWS ECS, Google Cloud Run, or traditional VMs, your deployment pipeline needs to know which version of your application to deploy and where to get it from.
This is where Harness Artifact Registry becomes invaluable. Because it's natively integrated with Harness CD, your deployment pipelines can pull Docker images and artifacts directly without managing external Docker registry credentials or complex authentication flows.
Harness CD supports numerous deployment types (often called CD swimlanes), and Harness Artifact Registry works seamlessly with all of them. When you configure a CD service, you simply select Harness Artifact Registry as your artifact source, specify which container registry and artifact to use, and define your version selection criteria.
From there, the deployment pipeline handles everything: authenticating with the registry, pulling the correct Docker image version, verifying it's passed vulnerability scans and security checks, and deploying it to your target environment. You can deploy to production with strict version pinning for stability, or to non-production environments with dynamic version selection for testing. The choice is yours, and it's all configured through the same intuitive interface.
The real power lies in the traceability. Every deployment is logged with complete details: which artifact version was deployed, when, by whom, and to which environment. If you need to roll back, the previous Docker image versions are right there, ready to be redeployed.
Why This Matters
From the moment you build a Docker image to when it's running in production, Harness Artifact Registry provides a complete, secure, and governed artifact lifecycle. You get container security that prevents issues before they occur, complete visibility through SBOM generation and audit logs, and native CI/CD integration that eliminates the complexity of managing multiple Docker registries and credentials.
This isn't just about storing Docker images. It's about building confidence in your software supply chain with a secure, OCI-compliant container registry.
In a world where supply chain attacks are increasingly common and compliance requirements continue to grow, having a robust artifact management and container registry strategy is essential. Harness Artifact Registry delivers that strategy through a platform that's both powerful and intuitive.
Whether you're a developer pushing your first Docker image, a platform engineer managing deployment pipelines, or a security professional ensuring compliance, Harness Artifact Registry provides the tools you need to move fast without compromising on security.
Ready to experience a fully OCI-compliant Docker registry with built-in vulnerability scanning, dependency firewall, and seamless CI/CD integration? Explore Harness Artifact Registry and see how it transforms your software delivery pipeline with secure artifact management.

Database Governance with OPA in Harness DB DevOps
Database systems store some of the most sensitive data of an organization such as PII, financial records, and intellectual property, making strong database governance non-negotiable. As regulations tighten and audit expectations increase, teams need governance that scales without slowing delivery.
Harness Database DevOps addresses this by applying policy-driven governance using Open Policy Agent (OPA). With OPA policies embedded directly into database pipelines, teams can automatically enforce rules, capture audit trails, and stay aligned with compliance requirements. This blog outlines how to use OPA in Harness to turn database compliance from a manual checkpoint into a built-in, scalable part of your DevOps workflow.
The Challenges of Database Compliance
Organizations face multiple challenges when navigating database compliance:
- Complex Regulatory Requirements: Standards such as GDPR, HIPAA, PCI-DSS, and SOX impose strict controls on data access, consent, storage, and processing. Compliance requires both preventative controls (e.g., access restrictions) and demonstrable evidence of effective enforcement.
- Lack of Visibility: Traditional database operations often lack centralized oversight, making it difficult to answer questions like “Who accessed data?”, “Which change was deployed?” or “Were controls enforced consistently?” without expensive, manual processes.
- Manual Processes and Human Error: Manual access approvals, change reviews, or ad-hoc scripting introduce risks, from privilege creep to inconsistent documentation that can lead to compliance gaps.
These challenges highlight the necessity of embedding governance directly into database development and deployment pipelines, rather than treating compliance as a reactive checklist.
Governance at Scale with Harness Database DevOps
Harness Database DevOps is designed to offer a comprehensive solution to database governance - one that aligns automation with compliance needs. It enables teams to adopt policy-driven controls on database change workflows by integrating the Open Policy Agent (OPA) engine into the core of database DevOps practices.
What is OPA and Policy as Code?
Open Policy Agent (OPA) is an open-source, general-purpose policy engine that decouples policy decisions from enforcement logic, enabling centralized governance across infrastructures and workflows. Policies in OPA are written in the Rego declarative language, allowing precise expression of rules governing actions, access, and configurations.
Harness implements Policy as Code through OPA, enabling teams to store, test, and enforce governance rules directly within the database DevOps lifecycle. This model ensures that compliance controls are consistent, auditable, and automatically evaluated before changes reach production.
Building a Governance Framework Using OPA Policies
Here’s a structured approach to implementing database governance with OPA in Harness:
1. Define Compliance and Governance Objectives
Start by cataloging your regulatory obligations and internal governance policies. Examples include:
- Restricting access to sensitive tables based on roles or departments.
- Prohibiting destructive schema changes (e.g., DROP TABLE) in production.
- Enforcing least privilege by limiting modify rights only to authorized service accounts.
- Requiring reviews and approvals for schema migrations above a threshold.
Translate these requirements into quantifiable rules that can be expressed in Rego.
2. Author OPA Policies in Harness
Within the Harness Policy Editor, define OPA policies that codify governance rules. For example, a policy might block any migrations containing operations that remove columns in production environments without explicit DBA approval.
Harness policies are modular and reusable, you can import and extend them as part of broader governance packages. This allows cross-team reuse and centralized management of rules. Key aspects include:
- Policy Modules: Group related rules into packages for clarity.
- Policy Severity: Optionally set enforcement thresholds (e.g., error vs. warning).
- Testing and Simulation: Harness provides testing tools to validate policies against real or sample inputs before activation.
By expressing governance as code, you ensure consistency and remove ambiguity in policy enforcement.
3. Integrate Policies with CI/CD Pipelines
Policies can be linked to specific triggers within your database deployment workflow, for instance, evaluating rules before a migration is applied or before a pipeline advances to production. This integration ensures that non-compliant changes are automatically blocked, while compliant changes proceed seamlessly, maintaining the balance between speed and control.
Operationalizing Database Compliance
Automated Enforcement
Harness evaluates OPA policies at defined decision points in your pipeline, such as pre-deployment checks. This prevents risky actions, enforces access controls, and aligns every deployment with governance objectives without manual intervention.
Audit Trails and Traceability
Every policy evaluation is logged, creating an auditable trail of who changed what, when, and why. These logs serve as critical evidence during compliance audits or internal reviews, reducing the overhead and risk associated with traditional documentation practices.
Role-Based Controls and Least Privilege
By enforcing the principle of least privilege, policies ensure that users and applications possess only the necessary permissions for their specific roles. This restriction on access is crucial for minimizing the potential attack surface and maintaining compliance with regulatory requirements for data access governance.
Best Practices for Policy-Driven Governance
- Start with High-Impact Policies: Prioritize controls around sensitive data and production environments.
- Leverage Policy Libraries: Use reusable policy templates as a starting point and customize them for your organizational context.
- Iterate with Continuous Feedback: Use audit results and pipeline failures as feedback loops to refine policies.
- Align with Compliance Frameworks: Map OPA policies to specific regulatory requirements (e.g., GDPR’s principle of accountability) to demonstrate traceability during audits.
- Educate Teams: Ensure developers and DBAs understand the governance policies and the reasons behind them to reduce friction.
Conclusion
Database governance is an essential pillar of enterprise compliance strategies. By embedding OPA-based policy enforcement within Harness Database DevOps, organizations can automate compliance controls, minimize risk, and maintain developer productivity. Policy as Code provides a scalable, auditable, and consistent framework that aligns with both regulatory obligations and the need for agile delivery.
Transforming database governance from a manual compliance burden into an automated, integrated practice empowers teams to innovate securely, confidently, and at scale - ensuring that every change respects the policies that protect your data, your customers, and your brand.

Measuring Developer Productivity: Prove Impact
Your developer productivity initiative didn't collapse because the data was wrong. It stalled because it couldn't answer the business question.
Leadership asked, "So what?"
You presented improved cycle time, higher deployment frequency, lower change failure rate. The dashboards were polished and the trends were moving in the right direction. And still, the room was unconvinced, because the real question was never about operational motion. It was whether engineering was driving measurable business impact.
The best engineering organizations stopped treating productivity as an internal reporting exercise a long time ago. They don't measure to validate effort. They measure to demonstrate outcomes, treating productivity as a strategic capability rather than a compliance artifact. That framing shift is the difference between a dashboard that gets ignored and a measurement system that actually influences investment decisions.
Developer Productivity Metrics That Actually Mean Something
Most engineering productivity programs fail at the measurement selection stage. Teams track what is easy to instrument instead of what influences strategic outcomes: lines of code shipped, tickets closed, pull requests merged. These are activity signals. They describe motion, not value creation.
Even widely respected metrics become vanity indicators when stripped of context. Deployment frequency sounds impressive until you ask what those deployments actually delivered. Lead time looks strong until you realize the shipped features didn't move adoption or revenue. Change failure rate improves, but customer experience stays flat. The numbers go up and the business question remains unanswered.
What's needed is a translation layer between technical execution and business impact. This doesn't mean abandoning quantitative rigor. It means recognizing that metrics only matter when they're connected to outcomes. Deployment frequency is not the goal; sustainable value delivery is. Lead time is not the strategy; responsiveness to market demand is. The difference is subtle, but it's decisive.
High-performing teams measure how engineering execution influences customer value, product velocity, operational risk, and strategic alignment. They treat metrics as decision inputs, not performance theater.
Why Engineering Intelligence Fails Without Workflow Context
Data without workflow context creates false conclusions. A pull request sitting in review for three days may look like inefficiency, but the cause matters enormously. Is it architectural complexity? Reviewer overload? Cross-timezone coordination? A critical design discussion that needed to happen? Without workflow visibility, metrics flatten nuance into noise and teams start optimizing the wrong bottlenecks.
Consider two teams. One deploys ten times per week with frequent rollbacks. Another deploys five times per week with zero incidents. Raw deployment frequency rewards the first team. Risk-adjusted delivery performance favors the second. Without context, your metrics are quietly incentivizing the wrong behavior, rewarding operational debt over operational discipline.
Developer productivity measurement at scale means connecting commits to pipelines, pipelines to releases, releases to incidents, and incidents back to customer impact. Only then can you distinguish between healthy experimentation and accumulating debt, between intentional technical debt reduction and systemic inefficiency. If review time improves but deployment frequency stays flat, you didn't accelerate delivery. You shifted the bottleneck. True engineering intelligence exposes those dynamics instead of hiding them behind aggregate scores.
Measuring Developer Productivity Across Team Boundaries
Most organizations measure productivity within team silos and then wonder why platform investments underperform. A backend team increasing throughput doesn't create value if frontend teams can't integrate efficiently. An infrastructure team reducing pipeline time doesn't accelerate delivery if governance constraints slow application releases downstream. A platform investment only matters if it compounds velocity across the teams that depend on it.
Engineering productivity is systemic. High-functioning organizations measure it that way, instrumenting handoffs between systems rather than just activity within them. They track how long work waits between functions, analyze how architectural decisions in one domain impact velocity in another, and measure whether platform capabilities are translating into application-level acceleration.
This is where productivity measurement shifts from operational reporting to strategic intelligence. The question stops being whether individual teams are busy and starts being whether the organization is aligned. Whether platform investments are landing. Whether architectural decisions are compounding velocity or quietly constraining it. Those answers don't come from point-in-time dashboards. They emerge from trend analysis across repositories, pipelines, and organizational boundaries.
When DORA Metrics and SPACE Framework Converge
DORA metrics provide a delivery health baseline: deployment frequency, lead time for changes, change failure rate, and time to restore service. Think of them as the vital signs of your software delivery operation, answering whether the delivery engine is healthy enough to support strategic execution.
But delivery health alone doesn't guarantee sustainable performance. The SPACE framework extends that baseline by capturing satisfaction, performance, activity, communication, and efficiency. It acknowledges what throughput metrics often miss: that sustainable velocity requires healthy teams, manageable cognitive load, and real alignment between effort and impact.
The warning signs are predictable once you know how to read them. High DORA scores alongside declining satisfaction is a burnout signal. Strong activity metrics with weak communication indicators point to silo formation. Efficient deployment paired with persistent incident volume suggests fragility hiding beneath a healthy-looking surface.
The most effective engineering organizations don't choose between DORA and SPACE. They integrate them. DORA confirms the delivery engine is functioning. SPACE confirms that function is sustainable and human. Together, they create a multi-dimensional view of engineering effectiveness that balances speed, quality, resilience, and team health, transforming productivity measurement from throughput tracking into something closer to strategic foresight.
Harness SEI: Engineering Intelligence with Context
Most engineering intelligence platforms prioritize visibility without context. They surface metrics but fail to connect them to workflow realities or business outcomes, and that's exactly where they fall short.
Harness SEI treats measuring developer productivity as a strategic capability. By integrating with source control systems, CI/CD pipelines, and issue tracking platforms, it creates a unified view of delivery performance across the engineering ecosystem, connecting commits to execution, execution to release, and release to reliability.
The more important distinction is what the platform doesn't do. It doesn't reduce productivity to individual surveillance or flatten team performance into leaderboard comparisons. A team showing slower cycle times because they're paying down technical debt is not underperforming. A platform team with lower deployment frequency because they're building foundational infrastructure is not failing. In isolation, those signals look negative. In context, they're strategic. Harness SEI is built to surface that context, giving engineering leaders visibility into whether platform improvements are compounding velocity, whether architectural investments are reducing friction, and whether delivery health is genuinely supporting strategic goals.
Proving Impact Instead of Measuring Motion
The best engineering organizations don't measure productivity to justify headcount. They measure it to demonstrate value creation, and that shift changes the entire conversation.
When your developer productivity measurement framework connects technical activity to strategic results, you stop defending engineering costs and start demonstrating engineering value. You show that faster deployments enabled a faster market response. That reduced change failure rates lowered operational costs. That improved cycle times allowed the team to deliver more customer value with the same resources.
The common thread across DORA, SPACE, and platforms like Harness SEI is the same principle: context matters more than raw numbers. Optimizing for faster deployments in isolation is tactical. Optimizing for sustainable, risk-adjusted, business-aligned delivery is strategic.
The next time leadership asks whether engineering is productive, you won't reach for activity charts. You'll respond with impact evidence: trend lines tied to business outcomes, insights grounded in workflow context, metrics that influence decision-making rather than just filling reporting cycles.
That is the difference between tracking productivity and understanding it. Between measuring motion and proving impact.
Explore Harness SEI or review implementation details. For teams evaluating long-term fit, review the SEI roadmap.

Database Schema Evolution: Designing for Continuous Change
There was a time when database design was an event. It happened once, early in a project, often before the first line of application code was written. Architects would gather with domain experts, sketch entities and relationships, debate normalization levels, and arrive after weeks of discussion, at what was believed to be the schema. Once approved, that schema was treated as immutable.
This mindset assumed that the future was predictable. But it rarely is. Modern database design is no longer about defining a perfect schema upfront, but about enabling safe, continuous evolution as systems and requirements change.
Database Design Is Not a One-Time Event
At the beginning, requirements are usually clear and limited. The schema reflects the system’s first understanding of the domain.
CREATE TABLE users (
id SERIAL PRIMARY KEY,
email VARCHAR(255) NOT NULL UNIQUE,
created_at TIMESTAMP NOT NULL DEFAULT NOW()
);This design is clean, minimal, and correct, for now. It models what the system knows today: users exist, they have an email, and they were created at a specific time.
At this stage, the schema feels complete, although it never is.
When Reality Adds Context
As the product matures, new questions emerge. The business wants to personalize communication. Support wants to address users by name. Marketing wants segmentation. The schema evolves, not because it was poorly designed, but because the system learned something new.
ALTER TABLE users
ADD COLUMN first_name VARCHAR(100),
ADD COLUMN last_name VARCHAR(100);
This change is small, additive, and safe. No existing behavior breaks. No data is lost. The schema now captures richer context without invalidating earlier assumptions.
This is evolutionary design in its simplest form: adapting without disruption.
Managing Database Schema Changes Without Breaking Production
As usage grows, teams discover new workflows. Users can now deactivate their accounts. Regulatory requirements demand traceability.
Instead of redefining the table, the schema evolves to support new behavior.
ALTER TABLE users
ADD COLUMN status VARCHAR(20) NOT NULL DEFAULT 'ACTIVE',
ADD COLUMN deactivated_at TIMESTAMP;
Importantly, this change preserves backward compatibility. Existing queries continue to work. New logic can gradually adopt the new fields. This approach reflects database schema evolution best practices, where changes are incremental, backward-compatible, and safely deployable through CI/CD pipelines. Evolutionary design favors extension over replacement.
Performance Pressures and Structural Refinement
With scale comes performance pressure. Queries that once ran instantly now struggle. Reporting workloads introduce new access patterns.
Rather than redesigning everything, the schema evolves structurally to meet new demands.
CREATE INDEX idx_users_status ON users (status);This change does not alter the data model conceptually, but it reflects a deeper understanding of how the system is used. Design evolves not just for correctness, but for operational reality.
Database design is no longer theoretical, it is informed by production behavior.
When the Original Model No Longer Fits
Eventually, teams outgrow early assumptions. A single user’s table can no longer represent multiple user roles, tenants, or identity providers. The model needs refinement. Evolutionary design handles this carefully, through parallel structures and gradual migration.
CREATE TABLE user_profiles (
user_id INT PRIMARY KEY REFERENCES users(id),
display_name VARCHAR(150),
preferences JSONB,
updated_at TIMESTAMP NOT NULL DEFAULT NOW()
);
Instead of overloading the original table, the design evolves by extracting responsibility. Existing functionality remains stable while new capabilities move forward. At no point was a “big rewrite” required.
The Operational Risks of Unmanaged Database Schema Changes
As changes accumulate, complexity shifts from design to operations. Teams struggle to answer basic questions:
- Which version of the schema is running in production?
- What changes are pending in staging?
- Can this migration be safely rolled back?
This is where evolutionary design demands discipline. Small changes only remain safe when they are visible, validated, and governed.
Why Database DevOps Matters for Schema Evolution?
Modern database design extends beyond tables and columns. It includes how changes are reviewed, tested, approved, and promoted. As applications adopt CI/CD and ship continuously, databases often remain the slowest and riskiest part of the release. Manual migrations, limited visibility, and fear of rollbacks turn schema changes into operational bottlenecks.
Database DevOps addresses this gap by applying software delivery discipline to database changes:
- Schema changes are versioned and traceable
- Migrations are validated before production
- Rollbacks are tested, not improvised
- Audit trails are automatic, preventing high-risk changes from reaching production
By embedding database schema evolution into CI/CD pipelines, teams reduce deployment risk while increasing delivery velocity. Platforms like Harness Database DevOps enable this by combining state awareness, controlled execution, and auditability, making database changes predictable, repeatable, and safe.
The Database as a Record of Learning
Each SQL change tells a story:
- What the system learned
- What assumptions changed
- What scale revealed
- What compliance required
A database is not a monument to early decisions. It is a living artifact that reflects the system’s understanding of its domain at every point in time.
Conclusion: Evolution is the Design
Database design evolution is not a failure of planning, it is evidence of adaptation.
The most resilient systems are not those with perfect initial schemas, but those designed to evolve safely and continuously. By embracing incremental change, versioned history, and automated governance, teams align database design with the realities of modern software delivery.
In a world where applications never stop shipping, database design cannot remain static. They must evolve, with confidence, control, and clarity, supported by Database DevOps practices and platforms such as Harness Database DevOps.
Because in the end, the schema is not the design. The ability to evolve it safely is.

Hot Takes: What the AI Hype Gets Wrong About Software Engineering Excellence
Matthew Skelton is the CEO & CTO of Conflux and a featured speaker at this year’s DevOps Modernization Summit. Ahead of our annual summit, Matthew has shared his hot takes on AI, DORA, and the key to successful automation. We’ve summarized his thoughts below – or watch for yourself.
Hot Take #1: You're Using AI Backwards
The AI gold rush is in full swing. Every engineering leader is under pressure to adopt it, measure it, and show ROI on it. But here's the uncomfortable truth most people aren't saying out loud: AI is having a massive impact on software engineering — and it's still not delivering real value. Most engineering teams start with the tool, then hunt for a use case. That's exactly wrong.
"It's really important for us to come back to the idea of starting with the outcomes first, then working back towards understanding how we'd use AI to empower teams to be effective stewards of value, to reduce cognitive load, to shorten time to do things that are not value add," Matthew shares.
Until you flip that equation — outcomes first, tools second — AI is just expensive noise. Know what problem you're solving before you touch the tooling.
Hot Take #2: AI-Generated Code Is Creating More Work, Not Less
Here's one nobody wants to admit at the all-hands: spinning up AI to generate mountains of code isn't always a productivity win. Sometimes it's just a liability transfer.
"We're not going to use AI to generate mountains of code that then has to be retested and where we find all the security bugs. But we can use it to aid teams to focus on their mission more effectively," according to Matthew.
More code means more review, more vulnerabilities, more cognitive load on already-stretched developers, creating a velocity paradox. The teams winning with AI aren't using it to ship more — they're using it to do less of what doesn't matter.
Hot Take #3: Chasing DORA Metrics Is a Trap
DORA metrics are everywhere. Deployment frequency. Lead time. MTTR. Change failure rate. And they're being misused by almost everyone who tracks them.
"DORA metrics are output metrics. We shouldn't be trying to drive them directly. We need to be looking at the fundamental capabilities — improving our capabilities and expect to see the DORA metrics change,” he says.
Optimizing for the metric instead of the capability is how you get teams gaming numbers while software quality quietly deteriorates. DORA metrics are a thermometer — not a treatment plan.
And there's another inconvenient truth: "The context for using DORA metrics is quite specific — it's teams that have end-to-end responsibility for value flow. And lots of organizations are not in that place."
If your teams don't own the full value stream, DORA might just be the wrong measuring stick entirely.
Hot Take #4: Most Engineering Metrics Aren't Safe to Optimize
The metrics you push on need to be "safe to optimize." Choosing the wrong metrics doesn't just give you bad data — it actively drives behavior you don't want.
"The specific metrics you want to choose very much depend on the context that you're talking about. We need people with a high degree of awareness of the operating context to select the right metrics to empower leaders to be able to push those levers," he states.
Cookie-cutter metric frameworks applied without context are how you end up with fast deployments of broken software. Context is everything.
Hot Take #5: Manual Compliance Is Already Dead — You Just Haven't Admitted It Yet
The pace of change in technology, regulation, and market conditions has blown past what any team can manage through manual inspection.
"The rate of change of technology, of regulatory requirements, of market and economic trading relationships — the rate of change of all these things is too fast for us to have manual inspection of things like security compliance and regulatory compliance," Matthew says.
If your compliance and security processes still depend on humans checking boxes at the end of a release cycle, you're not managing risk — you're manufacturing it. Compliance has to be baked into the platform. Full stop.
Hot Take #6: Automating Compliance Without Building Trust Will Backfire
Here's the nuance that gets lost when teams rush to automate compliance into their delivery platforms: the technology is the easy part.
According to Matthew: "This has to be baked in. But it has to be baked in in a way which builds trust with the people who are, in some cases, on the hook for things like security compliance and regulatory compliance — particularly in financial services."
"In addition to baking compliance into a platform, we need to have a social dynamic inside the organization that builds that trust so that people feel confident that what the platform is doing and controlling is what's needed."
You can automate every security gate in your CI/CD pipeline, but if the compliance team doesn't trust the platform, they'll route around it. Governance is a people problem as much as a technology problem. Build the trust, or the automation won't stick.
The Bottom Line
Engineering excellence in 2026 doesn't go to the team with the most AI tools or the prettiest DORA dashboard. It goes to the teams who are ruthlessly honest about where they're generating real value — and brave enough to act on what the data is actually telling them.
Start with outcomes. Pick metrics that are safe to optimize. Automate compliance with trust baked in alongside it. And stop using AI to generate problems you'll have to fix later.
Want more hot takes? Join this year’s DevOps Modernization Summit and hear straight from industry leaders.

How to Build AI-Native Security Resilience (And Finally Get Developers And Security On The Same Team)
Developers and security professionals have struggled to get on the same page for what seems like forever and AI is only making that divide larger, according to results from our State of AI-Native Application Security 2025 research report.
AI applications are spreading through organizations at a fast rate, in many cases becoming the new “shadow IT” - 62% of our survey takers said they can’t identify where the LLMs are in their organizations, with 75% saying they’re potentially creating much greater risks than ever before. All told, 61% of those surveyed said two-third of their organizations' newly built applications are being designed with AI components.
But are those apps secure? Likely not: 62% of respondents believe AI apps are more vulnerable to cybercriminals than traditional IT applications and over two-thirds of survey takers report already experiencing an attack on an AI application.
And, unfortunately, dev and sec teams aren’t facing this problem together, at least according to our findings. Survey takers said:
- Developers lack time and training: 62% say devs are too busy to implement comprehensive AI-native security, and the same percentage say they lack the necessary expertise.
- Speed and security are mismatched: 75% believe AI applications evolve faster than security can keep up.
- Collaboration breakdowns are widening the gap: Only 34% of developers notify security before starting AI projects, and just 53% before going live.
- Perception remains a barrier: 74% of security leaders say developers view security as a blocker to AI innovation.
But, organizations can unlock the value of their AI investments *and* make them more secure at the same time, while, (bonus!), bringing security pros and developers together - if they commit to building AI-native security resilience. This is a mindset and culture shift, perhaps of monumental proportions, but we promise the payoff is worth it. Here’s how to get started:
Lay the groundwork with shared governance
Manual reviews are tedious, prone to human error, and can double or triple the wait times for approval. To break that cycle, opt for Policy as Code rather than manual reviews, building something that engineering and security agree upon beforehand. That could look like security defining policies that devs embed into CI/CD pipelines and violations that trigger automated feedback rather than blocking progress.
This is a great place to start - or stress - a true “shift left” mentality.
Make AI components discoverable
AI components can’t be secure if they’re not seen. Teams need to monitor and log all AI components, of course, but the organization needs to make it as easy as possible to use safe and sanctioned AI tools. Shadow AI only gets worse when the “official tools” are difficult to use.
Detect anomalies by tracking AI implementations in real-time
Normal rules won’t apply here, so instead teams need to look at model behavior (sudden spikes or abnormal token usage), security signals (prompt injection patterns or hidden tool calls), and operational (cost anomalies or context window size spikes). Also consider building real-time guardrails with policy automation that can throttle model calls or downgrade agent permissions.
Test dynamically against AI-specific threats
Up your testing game with specific threat catalogs including OWASP Top 10 for LLM Apps and MITRE ATLAS and don’t forget the TEVV concepts. A dedicated security test harness can be particularly helpful here, as can adversarial “prompt fuzzing.”
Don’t forget to protect what’s already in production
In the immortal words of Fox Mulder “trust no one,” or in this case, don’t trust *any* of the AI inputs and outputs. Enforce data classification and context boundaries, secure the model interaction layer, and make sure to monitor the behavior and not just the infrastructure.
FAQs on AI-Native Security Resilience
What does "AI-native security resilience" actually mean in practice?
AI-native security resilience means security isn't a gate at the end of the pipeline — it's woven into every stage of delivery. Harness uses contextual insights and agentic workflows to detect and mitigate risks from build to post-deployment, covering everything from application and API discovery to AI-powered threat prevention.
How does Harness help security and developer teams work from the same playbook?
The merger of Harness and Traceable enables software teams to seamlessly develop, deploy, and secure applications, ensuring security is embedded at every stage of the software lifecycle. By unifying DevOps and AppSec in a single platform, both teams operate with the same pipeline context — eliminating the handoff friction that traditionally breaks collaboration.
How does Harness reduce the burden on developers when it comes to fixing vulnerabilities?
Harness AI streamlines the process of fixing vulnerabilities, enabling developers and security personnel to manage security backlogs, address critical issues promptly, and generate code suggestions and pull requests to remediate issues directly from the security testing orchestration (STO) module.
With shadow AI becoming a major enterprise risk, how does Harness help organizations stay in control?
Harness addresses AI visibility through the Software Delivery Knowledge Graph — a contextual layer that maps a company's security policies, compliance requirements, infrastructure, and development practices — so AI agents can enforce guardrails automatically, rather than relying on developers to remember them.

Cloud Cost Optimization: Why Your Approach Is Broken
If cloud cost optimization feels like a never-ending game of whack-a-mole—new recommendations every 30 days, the same debates with engineering, another set of dashboards no one trusts—you’re not alone.
But what if your cloud cost optimization strategy is the reason your AWS bill keeps climbing?
Not the lack of one.
Not poor execution.
The strategy itself.
We've seen this pattern dozens of times: teams implement tagging standards, build dashboards, schedule monthly FinOps reviews, and still watch costs spiral. The infrastructure is tagged. The metrics exist. The meetings happen. Yet every quarter, the CFO asks the same uncomfortable question:
“Why are we spending this much?”
The problem usually isn’t the idea of optimization. It’s the approach: too reactive, too late in the lifecycle, and too disconnected from how software is actually built and shipped.
And in high-velocity engineering environments, that gap between deployment and optimization review is exactly where runaway spend lives.
Why Traditional Cloud Cost Optimization Strategies Fail at Scale
Most organizations adopt a cloud cost management approach that sounds reasonable:
Deploy infrastructure → monitor spend → identify anomalies → remediate issues → repeat.
This is the classic “observe and optimize” model, borrowed from decades of on-premises capacity planning.
It breaks in the cloud.
In traditional datacenters, provisioning took weeks. Infrastructure decisions went through multiple approval layers. The natural friction slowed spend.
In cloud environments, engineers can provision thousands of dollars of compute in minutes. The speed that makes cloud infrastructure powerful also makes reactive cost optimization dangerously slow.
The Monthly Treadmill Problem
A huge reason teams feel like they’re starting over every month is that the default workflow looks like this:
Spend happens
A report shows waste
FinOps sends recommendations
Engineering says “not now”
Repeat next month
Even if your team is doing all the “right” things—rightsizing, commitments, idle cleanup, non-prod shutdown—you’re still reacting to what already happened.
And if your cloud spending optimization depends on sporadic human follow-through, you’ll keep reliving the same cycle.
The Reporting Trap
The most common failure mode we encounter is what we call “the reporting trap.”
Organizations invest heavily in cost visibility dashboards, allocation reports, and trend analysis, then wonder why costs don't improve.
The reports show what happened.
They rarely prevent what’s about to happen.
Consider a typical scenario: an engineering team deploys a new microservice on Friday. It includes an RDS instance sized for anticipated peak load, plus a few EC2 instances running 24/7 for background processing.
The deployment succeeds. The service works.
Two weeks later, someone notices the RDS instance costs $3,000/month and runs at 12% utilization. By the time this surfaces in a cost review, you’ve burned $6,000.
Reporting-based infrastructure cost optimization identifies problems. It doesn’t prevent them.
And in CI/CD environments shipping multiple times per day, prevention matters far more than detection.
The Allocation Illusion
Another common broken strategy: obsess over cost allocation and chargeback models.
Get the tagging right.
Assign every dollar to a team.
Generate showback reports.
Declare victory.
Allocation solves an accounting problem. It doesn’t solve an engineering problem.
Knowing which team caused overspend doesn’t stop the next deployment from repeating the same mistake. It creates visibility into financial responsibility without creating controls that prevent waste.
Effective cloud cost governance requires allocation and guardrails. You need to know who’s spending—but you also need mechanisms that stop obviously wasteful configurations from ever reaching production.
FinOps Best Practices: Finance + DevOps (And That’s the Point)
A lot of cloud cost optimization strategies fail because they treat FinOps as:
- a tool
- a tagging project
- a finance initiative
- a savings sprint
- “finance trying to cut engineering’s budget”
But mature FinOps best practices are built around collaboration:
Finance, engineering, infrastructure/platform teams, and business owners operating from the same data and goals—even if their priorities differ.
- Finance wants predictability and accountability
- Engineering wants velocity and reliability
- Platform teams want consistency and governance
- Business owners want clear unit economics and value delivery
When those groups operate in silos, cloud bills become a mystery, optimization becomes political, and waste becomes “the cost of doing business.”
A mature cloud cost optimization strategy flips that. It makes spend a shared responsibility—with shared context.
What Cloud Cost Optimization Should Actually Look Like
A working cost optimization framework starts from a different premise:
Cost decisions should happen at the same place and time as infrastructure decisions.
Not in a dashboard two weeks later.
Not in a quarterly business review.
In the pull request.
In the Terraform plan.
In the CI/CD pipeline before deployment.
Shift Cost Controls Left (Shift-Left FinOps)
The biggest step-change happens when you stop treating cloud cost reduction strategy work as an operational clean-up task—and start treating cost governance as a software delivery design constraint.
That’s what “shift left” means in a cost context: bringing optimization upstream into the provisioning and deployment workflow before overspend becomes production reality.
Because engineers don’t overprovision out of malice. They do it because their job is reliability:
- “Let’s size for the spike.”
- “Let’s pick the robust instance.”
- “Let’s over-allocate just in case.”
And then utilization never reaches what was provisioned.
Shift-left changes the default by putting guardrails and approved patterns into the path engineers already use to ship software—so cost control doesn’t require constant cost review meetings.
Think Roads, Not Speeding Tickets
A useful mental model is roads and cars:
Applications are the cars.
Infrastructure is the road system.
Roads set the rules—speed limits, exits, lanes—not the cars.
When your platform and provisioning workflows define the safe, optimized options, you reduce chaos and make the right choice the easy choice.
That’s what scalable cloud cost governance actually looks like.
“Zero Drift”: Don’t Just Set Guardrails—Keep Them
Once you shift left, the next question is:
How do you prevent teams from gradually drifting away from the intended standard?
That’s where the concept of zero drift comes in.
Zero drift is the idea that the desired state (cost-aware, governed, optimized) is continuously enforced through automation—so you aren’t babysitting optimization forever.
Humans shouldn’t be the control plane.
In practice, zero drift means:
- provisioning is standardized and policy-driven
- instance/cluster choices are constrained to approved configurations
- optimization actions (like rightsizing) can be automated with confidence
- anomalies are monitored, investigated, and resolved without breaking the system
Instead of monthly restarts, you get continuous alignment.
This is the difference between a cloud cost management approach that scales and one that collapses under velocity.
Tagging: Necessary, Painful… and Still a Common Failure Mode
Let’s address the elephant in the room: visibility.
If you can’t reliably answer “who is spending what, and why?” you can’t run FinOps at scale.
And yet, even in large organizations, tagging quality is frequently the weak link. Many companies can’t attribute the vast majority of spend with high confidence.
That’s not just an administrative issue—it’s a blocker for automation.
You can’t automate decisions against spend you can’t confidently attribute.
The takeaway is simple:
Treat attribution as foundational, but don’t stop there. Mature FinOps doesn’t end at “better tags.” It moves toward system-enforced governance and workload-level controls that reduce dependence on perfect tagging for every single decision.
The Pivot: From Savings to Unit Economics (and Business Value)
Most teams eventually hit diminishing returns on classic savings levers:
- Reserved instances / savings plans
- basic rightsizing
- cleaning up idle resources
- non-prod stopping
- commitment discounts
At some point, you’ve harvested the low-hanging fruit.
The next question becomes:
How do we define—and improve—the value of every cloud dollar going forward?
That’s where unit economics comes in.
Instead of asking “How much did we save?” you ask:
- What does it cost per customer?
- Per transaction?
- Per workload?
- Per feature, environment, or product line?
This reframes cloud cost reduction strategy work from “cost cutting” to “value engineering.”
And it’s one of the clearest signals that your cloud cost optimization strategy has matured.
How Harness Cloud Cost Management Approaches This Problem
Harness Cloud Cost Management is built around the premise that cost optimization happens in the engineering workflow, not after it.
Instead of treating cost management as a separate finance function, it integrates cost visibility and governance directly into CI/CD pipelines, infrastructure provisioning workflows, and day-to-day development processes.
Cost Visibility Across Your Entire Cloud Estate
Harness provides unified cost visibility across AWS, Azure, GCP, and Kubernetes clusters, with automatic allocation by team, service, environment, and business unit.
You get real-time dashboards showing exactly where spend is happening, down to individual workloads and namespaces.
Cost anomaly detection highlights unexpected changes automatically, with alerts routed directly to responsible engineering teams.
This supports both showback and chargeback models—without creating manual reporting overhead. Teams see their spend in real time, not weeks after the invoice closes.
In-Workflow Cost Governance
Where Harness differs from traditional tools is how governance works.
Cost policies enforce directly in CI/CD pipelines and infrastructure-as-code workflows.
Before a Terraform plan applies, Harness evaluates estimated costs against defined budgets and thresholds. If a deployment would exceed limits, the pipeline fails with clear feedback on what needs to change.
This creates a natural feedback loop where engineers see cost impacts immediately—while they still have full context on the infrastructure decisions being made.
It prevents expensive mistakes from reaching production rather than identifying them later through reporting.
Harness also supports automated optimization recommendations, including:
- rightsizing suggestions
- idle resource cleanup
- non-prod stopping automation
- commitment-based discount opportunities
Teams can implement these recommendations directly through the same pipelines they use for regular infrastructure changes.
Built for Engineering-Led Cost Optimization
Harness treats cloud cost management as an engineering problem, not a finance problem.
The platform integrates with existing tools (GitHub, GitLab, Jira, Slack) and workflows (Terraform, CloudFormation, Kubernetes) rather than requiring separate processes.
Engineers interact with cost data in the same interfaces they already use for infrastructure management.
Policy enforcement is flexible but opinionated:
Default guardrails prevent common waste patterns (idle resources, oversized instances, untagged infrastructure) while allowing teams to define exceptions for legitimate use cases.
The goal is to make cost-efficient choices the path of least resistance—not to create approval bottlenecks.
For organizations managing cost at scale, Harness supports advanced workflows like:
- environment-based budgets (dev/staging/production)
- cost allocation hierarchies (business units, products, teams)
- integration with business metrics for cost-per-transaction analysis
Fixing Your Cloud Cost Optimization Approach
If your current cloud cost optimization strategy feels broken, you’re probably optimizing the wrong thing.
Cost visibility and allocation are necessary, but they’re not sufficient.
Real cost control happens when engineers see cost impacts before deployment, not when finance reviews invoices after.
A working cost optimization framework:
- embeds cost awareness directly into CI/CD and IaC workflows
- combines proactive guardrails with real-time visibility
- uses automation to prevent drift
- measures success by cost efficiency and unit economics—not just raw spend reduction
Reactive cloud spending optimization scales poorly in high-velocity engineering environments.
Proactive cloud cost governance scales effortlessly.
Ready to shift cost controls left? Start with Harness Cloud Cost Management and see what engineering-native cost optimization looks like in practice.
What To Go Deeper?
Watch our webinar, Cloud Cost Optimization Isn't Broken_The Approach is to learn more.
Learn more about how Harness Cloud Cost Management works or explore the CCM documentation.

Engineering Metrics Success: Communicate Speed, Quality, and Business Outcomes
Engineering organizations are waking up to something that used to be optional: measurement.
Not vanity dashboards. Not a quarterly “engineering metrics review” that no one prepares for. Real measurement that connects delivery speed, quality, and reliability to business outcomes and decision-making.
That shift is a good sign. It means engineering leaders are taking the craft seriously.
But there are two patterns I keep seeing across the industry that turn this good intention into a slow-motion failure. Both patterns look reasonable on paper. Both patterns are expensive. And both patterns lead to the same outcome: a metrics tool becomes shelfware, trust erodes, and leaders walk away thinking, “Metrics do not work here.”
Engineering metrics do work. But only when leaders use them the right way, for the right purpose, with the right operating rhythm.
Here are the two patterns, and how to address them.
Pattern #1: “We bought the tool, gave it to leaders, and expected behavior to change”
This is the silent killer.
An engineering executive buys a measurement platform and rolls it out to directors and managers with a message like: “Now you’ll have visibility. Use this to improve.”
Then the executive who sponsored the initiative rarely uses the tool themselves.
No consistent review cadence. No decisions being made with the data. No visible examples of metrics guiding priorities. No executive-level questions that force a new standard of clarity.
What happens next is predictable.
Managers and directors conclude that engineering metrics are optional. They might log in at first. They might explore the dashboards. But soon the tool becomes “another thing” competing with real work. And because leadership is not driving the behavior, the culture defaults to the old way: opinions, anecdotes, and local optimization.
If leaders are not driving direction with data, why would managers choose to?
This is not a tooling problem. It is a leadership ownership problem.
What to do instead: make metrics executive-owned, not manager-assigned
If measurement is important, the most senior leaders must model it.
That does not mean micromanaging teams through numbers. It means creating a clear expectation that engineering metrics are part of how the organization thinks, communicates, and makes decisions.
Here is what executive ownership looks like in practice:
- The executive sponsor uses the tool publicly. In staff meetings, in reviews, in planning, in post-incident discussions.
- Metrics show up in decision moments. Prioritization, investment tradeoffs, risk calls, capacity conversations.
- Leaders ask better questions because they have data. Not “Why are you slow?” but “What is slowing you down, and what would move it?”
- A consistent cadence exists. Not random dashboard reviews. A repeatable operating rhythm.
When executives do this, managers follow. Not because they are told to, but because the organization has made measurement real.
Pattern #2: “Buying a measurement tool will fix our engineering problems”
This is the other trap, and it is even more common.
There is a false belief that if an organization has DORA metrics, improvements in throughput and quality will automatically follow. Like measurement itself is the intervention.
But measurement does not create performance. It reveals performance.
A tool can tell you:
- how long changes take to reach production
- how often you deploy
- how frequently you experience failure
- how quickly you recover
Those are powerful signals. But they do not change anything on their own.
If the system that produces those numbers stays the same, the numbers stay the same.
This is why organizations buy tools, instrument everything, and still feel stuck. They measured the pain, but never built the discipline to diagnose and treat the cause.
What to do instead: treat engineering metrics as instrumentation, not transformation
If you want metrics to lead to improvement, you need two things:
- Clear definitions and shared understanding
- A metrics practice that turns numbers into decisions and experiments
Without definitions, metrics turn into arguments. Everyone interprets the same number differently, then stops trusting the system.
Without a practice, metrics turn into observation. You notice, you nod, then you go back to work.
The purpose of measurement is not to create pressure. It is to create clarity. Clarity about where the system is constrained, what tradeoffs you are making, and whether your interventions actually helped.
The real goal: measure change, not teams
Here is the shift that unlocks everything:
The goal is not to measure engineers.
The goal is to measure the system.
More specifically, the goal is to prove whether a change you made actually improved outcomes.
A change could be:
- a tooling change
- a process change
- a policy change
- a staffing or org change
- a reliability investment
- a platform improvement
- a CI/CD modernization effort
If you cannot measure movement after you make a change, you are operating on opinions and hope.
If you can measure movement, you can run engineering like a disciplined improvement engine.
This is where DORA metrics become extremely valuable, when they are used as confirmation and learning, not as a scoreboard.
Engineering metrics should confirm reality, not replace judgment
The best leaders I have worked with do not hand leadership over to dashboards. They use metrics as confirmation of what they already sense, and as a way to test assumptions.
- “We believe code reviews are a bottleneck. Do we see it in cycle time breakdowns?”
- “We believe flaky tests are slowing delivery. Do we see increased rework or longer lead time?”
- “We believe incident recovery is too manual. Do we see MTTR improve after automation?”
- “We believe our deployment process is too risky. Does change failure rate drop after we change release strategy?”
That is the role of measurement. It turns gut feel into validated understanding, then turns interventions into provable outcomes.
A practical operating model that works
If you want measurement to drive real improvement, here is a straightforward structure that scales.
1) Define what “good” means in your context
Use DORA as a baseline, but make definitions explicit:
- What counts as a deployment?
- What counts as a production failure?
- How do you define lead time?
- How do you define recovery?
This prevents endless debates and keeps the organization aligned.
2) Establish a simple cadence
You do not need a heavy process. You need consistency.
A strong starting point:
- Weekly: team-level review of flow and reliability signals, focused on removing friction
- Monthly: leadership review focused on trend movement, constraints, and investments
- Quarterly: strategic review to decide where to focus improvement efforts next
3) Pair every metric with a lever
A metric without a lever becomes a complaint.
Examples:
- If lead time is high, what levers do you pull?
- reduce batch size, improve trunk-based practices, improve test speed, remove manual approvals
- reduce batch size, improve trunk-based practices, improve test speed, remove manual approvals
- If change failure rate is high, what levers do you pull?
- improve testing strategy, release safety patterns, observability, rollback mechanisms
- improve testing strategy, release safety patterns, observability, rollback mechanisms
- If MTTR is high, what levers do you pull?
- better alerting, runbooks, ownership clarity, automated remediation, incident practices
- better alerting, runbooks, ownership clarity, automated remediation, incident practices
4) Run experiments and measure outcomes
This is the part most organizations skip.
Pick one change. Implement it. Measure before and after. Learn. Repeat.
Improvement becomes a system, not a motivational speech.
5) Make leaders the model
This brings us back to Pattern #1.
If executives use the tool and drive decisions with it, measurement becomes real. If they do not, the tool becomes optional, and optional always loses.
Where the best organizations land
The organizations that do this well eventually stop talking about “metrics adoption.” They talk about “how we run the business.”
Measurement becomes part of how engineering communicates with leadership, how priorities get set, how teams remove friction, and how investment decisions are made.
And the biggest shift is this:They stop expecting a measurement tool to fix problems.They use measurement to prove that the problems are being fixed.
That is the point. Not dashboards, not reporting, not performance theater: Clarity, decisions, experiments, and outcomes.
In the end, measurement is not the transformation. It is the instrument panel that tells you whether your transformation is working.

From Chaos Engineering to Resilience Testing: Why We’re Expanding How Teams Validate Reliability
At Harness, we’re committed to helping teams build and deliver software that doesn’t just work – it thrives under pressure, scales reliably, and recovers swiftly from the unexpected. Today, we’re taking the next step in that mission by evolving our Chaos Engineering module into Resilience Testing.
This evolution reflects how reliability is tested in practice today. While Chaos Engineering has long been a powerful way to proactively identify weaknesses through controlled fault injection, many teams – SREs, platform engineers, performance specialists, and DevOps leaders – are already validating resilience across the same workflows:
- How systems behave when dependencies fail
- How services perform under sustained load
- How infrastructure and applications recover during real outages
Resilience Testing brings these efforts together into a single, continuous approach.
Built On Open Source and Real Systems
My work in Chaos Engineering started with a simple goal: make resilience testing practical for real-world systems. Before that, I spent years building foundational cloud-native infrastructure at places like CloudByte and MayaData, and I kept coming back to the same lesson: you learn fastest when you build in the open and stay close to production users.
Before joining Harness, my team and I created LitmusChaos to help teams running Kubernetes understand how their systems actually behave under failure. What began as an open source project grew into one of the most widely adopted chaos engineering projects in the CNCF, used by organizations testing real production environments.
When Harness acquired Chaos Native in 2022, it was clear we shared the same belief: chaos engineering shouldn’t be a standalone activity. It belongs inside the software delivery lifecycle. We then donated LitmusChaos to the CNCF, and Harness continues to actively maintain and contribute to the project today.
That combination of open source leadership and enterprise integration has directly shaped how chaos engineering evolved inside Harness.
How Chaos Engineering Expanded in Practice
Over the past four years, teams using Chaos Engineering pushed beyond isolated experiments toward broader resilience workflows.
What mattered most wasn’t injecting failures – it was understanding what to test, when to test, and how to learn continuously. That led to deeper capabilities around service and dependency discovery, targeted risk testing, monitoring-driven validation, automated gamedays, and AI-assisted recommendations.
As software delivery has become more automated and increasingly AI-assisted, these same principles naturally extended beyond chaos engineering alone.
Introducing Resilience Testing
Today, we’re launching Resilience Testing, with new Load Testing and Disaster Recovery Testing capabilities built on top of our Chaos Engineering foundation.
Resilience Testing brings together three core areas:
- Chaos Engineering to validate failure handling and recovery
- Load Testing to understand behavior under scale and stress
- Disaster Recovery Testing to prove readiness for real outages
These capabilities are unified through automation and AI-driven insights, helping teams prioritize risk, improve coverage, and continuously validate resilience as systems evolve.
Chaos Eengineering gave us a strong foundation, and Resilience Testing is the broader practice teams have been building toward as systems and workflows evolve.
A Milestone Shaped By Community
This evolution follows years of collaboration with the broader resilience engineering community, including Chaos Carnival, now in its sixth year, which brings together thousands of engineers sharing real lessons from production systems.
As systems grow more dynamic and AI-driven, resilience testing must move beyond periodic checks toward continuous, intelligent validation. Resilience Testing is designed for that reality, and it reflects what we’ve learned building, operating, and scaling real systems over time.
Ready to expand beyond chaos experiments? Talk to your Harness representative to enable the new capabilities, or book a demo with our team to explore the right rollout for your environment.
.png)
Harness AI February 2026 Updates: Securing & Making the SDLC Reliable and Shipping Faster with Agents
February is all about making AI in software delivery secure and easier to operate at scale. This month’s updates span enterprise-grade application security, API security via MCP, SRE automation, and a major upgrade to the DevOps Agent.
Bring API Security Intelligence Directly into Your AI Workflows
Harness’s WAAP Public MCP Server is now Generally Available, enabling querying API security data with natural language in popular AI environments such as VS Code, Cursor, and Claude Desktop. Teams can pull in insights across API discovery, inventory, risk, vulnerabilities, remediation, and runtime protection, and then blend that data with internal sources inside custom AI workflows.
This brings API security context directly into daily developer and security workflows, rather than locking it behind dashboards. By putting WAAP data behind an MCP server, organizations can enable richer, real-time AI-driven security analysis and make API telemetry usable in the same AI agents and copilots developers already rely on.
Looking ahead, WAAP tools will also be integrated with Harness AI, enabling joint customers to access capabilities through the Harness MCP server. The goal is a unified MCP experience where security and delivery agents can reason over the same API security data without brittle, one-off integrations.
Shift-Left Security That Actually Prioritizes What Matters
Harness SAST and SCA are now Generally Available as native security scanners within Security Testing Orchestration (STO), delivering AI-powered static analysis and software composition analysis right where AI agents and coding copilots generate code—in your pipelines. In the era of agentic coding, where AI autonomously writes, iterates, and deploys code at unprecedented speed, SAST scans repositories for security issues, hard-coded secrets, and vulnerable open-source libraries, while SCA analyzes container images for vulnerable OS packages and libraries, all with static reachability-based prioritization to cut through AI-amplified noise.
Onboarding is intentionally minimal: Harness automatically detects repositories and manages scanner hosting and licensing, including a 45-day free trial for existing STO customers. Within pipelines, SAST and SCA are available as native steps with auto repo detection, generate SBOMs for application and container dependencies, and surface results centrally for security and dev teams.
What sets this release apart is reachability-based prioritization and AI-assisted remediation, perfectly tuned for AI-driven workflows. Vulnerabilities are ranked based on whether they’re actually reachable from application code, helping teams focus on truly exploitable issues instead of noisy findings from rapid AI code gen, and AI-generated fixes can automatically open pull requests to accelerate remediation.
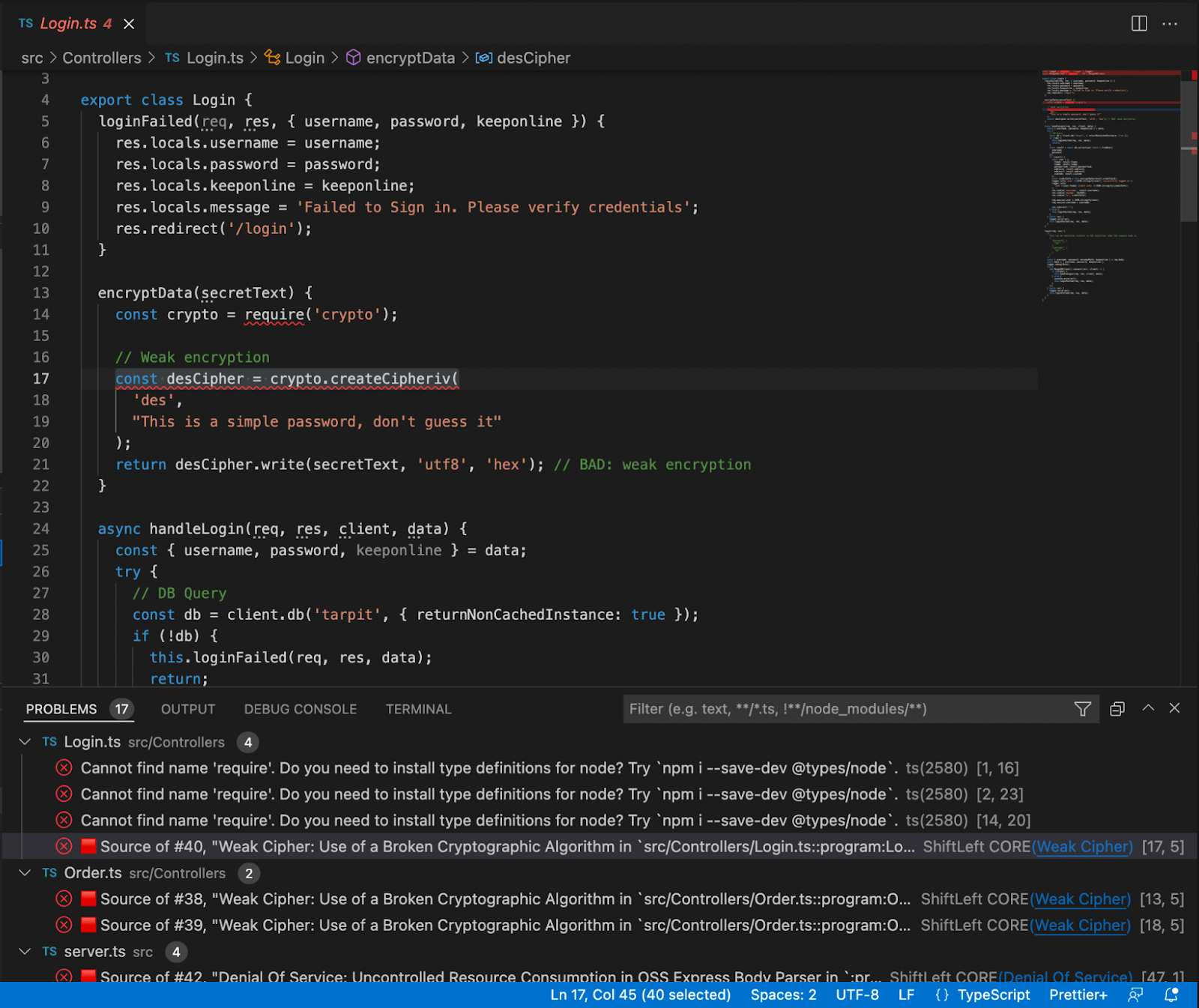
Incident Runbooks That Understand Your Jira Schema
In AI SRE, the Jira integration for runbooks has been rebuilt to support dynamic fields for both Create Jira Ticket and Update Jira Issue actions. When builders select a project and issue type, the runbook step now automatically loads the exact fields required by that Jira workflow, including custom fields, labels, and multi-select values.
This eliminates guesswork around field names and internal Jira schema details, and greatly reduces broken automations caused by missing or misconfigured required fields. For more advanced runbooks where the issue type is determined at runtime, a key-value mode lets builders set any Jira field directly while still benefiting from built-in validation that catches broken URLs and missing required fields before execution.
You can use the new Jira experience today by adding the updated Create or Update Jira actions to any AI SRE runbook. It’s particularly useful for complex incident workflows where different incident types must map cleanly to different Jira projects and issue types without manual rework.
A Smarter, Faster DevOps Agent for Enterprise-Scale Pipelines
The DevOps Agent has received a major upgrade and is now powered by an Opus 4.5 foundation model. From our internal testing, we found out that the new model improves speed, context retention, and overall pipeline generation accuracy, particularly for large, highly templated enterprise pipelines.
Teams will see faster response times, higher-quality YAML generation, and better handling of longer, more complex pipelines. This upgrade has been validated against complex pipelines. Enhanced template awareness also means the agent is better at reusing existing templates and making high-fidelity updates to existing pipelines, reducing the amount of manual cleanup after AI-generated changes.
The upgraded DevOps Agent is rolling out to our customers soon and will be available directly in the AI Chat experience, with no configuration changes required. This is especially impactful for large enterprises running deeply nested template hierarchies, where context management and accuracy are critical for safe automation.
Escaping the AI Velocity Paradox
These February updates directly tackle the AI Velocity Paradox: where AI coding tools accelerate code generation but create downstream bottlenecks in testing, security, deployment, and observability that erase those gains. By providing reachability-aware SAST/SCA to secure agentic code without slowing pipelines, MCP-powered API security for contextual risk analysis, smarter SRE runbooks for resilient operations, and an upgraded DevOps Agent for complex pipeline automation, Harness extends AI intelligence across the full software delivery lifecycle. The result? Teams ship faster, safer software without the fragility of fragmented tools or unproven hype, turning AI potential into measurable business velocity.
Reimagining Artifact Management for DevSecOps: Harness Artifact Registry GA
Today, Harness is announcing the General Availability of Artifact Registry, a milestone that marks more than a new product release. It represents a deliberate shift in how artifact management should work in secure software delivery.
For years, teams have accepted a strange reality: you build in one system, deploy in another, and manage artifacts somewhere else entirely. CI/CD pipelines run in one place, artifacts live in a third-party registry, and security scans happen downstream. When developers need to publish, pull, or debug an artifact, they leave their pipelines, log into another tool, and return to finish their work.
It works, but it’s fragmented, expensive, and increasingly difficult to govern and secure.
At Harness, we believe artifact management belongs inside the platform where software is built and delivered. That belief led to Harness Artifact Registry.
A Startup Inside Harness
Artifact Registry started as a small, high-ownership bet inside Harness and a dedicated team with a clear thesis: artifact management shouldn’t be a separate system developers have to leave their pipelines to use. We treated it like a seed startup inside the company, moving fast with direct customer feedback and a single-threaded leader driving the vision.The message from enterprise teams was consistent: they didn’t want to stitch together separate tools for artifact storage, open source dependency security, and vulnerability scanning.
So we built it that way.
In just over a year, Artifact Registry moved from concept to core product. What started with a single design partner expanded to double digit enterprise customers pre-GA – the kind of pull-through adoption that signals we've identified a critical gap in the DevOps toolchain.
Today, Artifact Registry supports a broad range of container formats, package ecosystems, and AI artifacts, including Docker, Helm (OCI), Python, npm, Go, NuGet, Dart, Conda, and more, with additional support on the way. Enterprise teams are standardizing on it across CI pipelines, reducing registry sprawl, and eliminating the friction of managing diverse artifacts outside their delivery workflows.
One early enterprise customer, Drax Group, consolidated multiple container and package types into Harness Artifact Registry and achieved 100 percent adoption across teams after standardizing on the platform.
As their Head of Software Engineering put it:
"Harness is helping us achieve a single source of truth for all artifact types containerized and non-containerized alike making sure every piece of software is verified before it reaches production." - Jasper van Rijn
Why This Matters: The Registry as a Control Point
In modern DevSecOps environments, artifacts sit at the center of delivery. Builds generate them, deployments promote them, rollbacks depend on them, and governance decisions attach to them. Yet registries have traditionally operated as external storage systems, disconnected from CI/CD orchestration and policy enforcement.
That separation no longer holds up against today’s threat landscape.
Software supply chain attacks are more frequent and more sophisticated. The SolarWinds breach showed how malicious code embedded in trusted update binaries can infiltrate thousands of organizations. More recently, the Shai-Hulud 2.0 campaign compromised hundreds of npm packages and spread automatically across tens of thousands of downstream repositories.
These incidents reveal an important business reality: risk often enters early in the software lifecycle, embedded in third-party components and artifacts long before a product reaches customers.When artifact storage, open source governance, and security scanning are managed in separate systems, oversight becomes fragmented. Controls are applied after the fact, visibility is incomplete, and teams operate in silos. The result is slower response times, higher operational costs, and increased exposure.
We saw an opportunity to simplify and strengthen this model.
By embedding artifact management directly into the Harness platform, the registry becomes a built-in control point within the delivery lifecycle. RBAC, audit logging, replication, quotas, scanning, and policy enforcement operate inside the same platform where pipelines run. Instead of stitching together siloed systems, teams manage artifacts alongside builds, deployments, and security workflows. The outcome is streamlined operations, clearer accountability, and proactive risk management applied at the earliest possible stage rather than after issues surface.
Introducing Dependency Firewall: Blocking Risk at Ingest
Security is one of the clearest examples of why registry-native governance matters.
Artifact Registry delivers this through Dependency Firewall, a registry-level enforcement control applied at dependency ingest. Rather than relying on downstream CI scans after a package has already entered a build, Dependency Firewall evaluates dependency requests in real time as artifacts enter the registry. Policies can automatically block components with known CVEs, license violations, excessive severity thresholds, or untrusted upstream sources before they are cached or consumed by pipelines.
Artifact quarantine extends this model by automatically isolating artifacts that fail vulnerability or compliance checks. If an artifact does not meet defined policy requirements, it cannot be downloaded, promoted, or deployed until the issue is addressed. All quarantine and release actions are governed by role-based access controls and fully auditable, ensuring transparency and accountability. Built-in scanning powered by Aqua Trivy, combined with integrations across more than 40 security tools in Harness, feeds results directly into policy evaluation. This allows organizations to automate release or quarantine decisions in real time, reducing manual intervention while strengthening control at the artifact boundary.
The result is a registry that functions as an active supply chain control point, enforcing governance at the artifact boundary and reducing risk before it propagates downstream.
The Future of Artifact Management is here
General Availability signals that Artifact Registry is now a core pillar of the Harness platform. Over the past year, we’ve hardened performance, expanded artifact format support, scaled multi-region replication, and refined enterprise-grade controls. Customers are running high-throughput CI pipelines against it in production environments, and internal Harness teams rely on it daily.
We’re continuing to invest in:
- Expanded package ecosystem support
- Advanced lifecycle management, immutability, and auditing
- Deeper integration with Harness Security and the Internal Developer Portal
- AI-powered agents for OSS governance, lifecycle automation, and artifact intelligence
Modern software delivery demands clear control over how software is built, secured, and distributed. As supply chain threats increase and delivery velocity accelerates, organizations need earlier visibility and enforcement without introducing new friction or operational complexity.
We invite you to sign up for a demo and see firsthand how Harness Artifact Registry delivers high-performance artifact distribution with built-in security and governance at scale.

From Chef to Chief Architect: Navigating the Intersection of AI and Data Security
Prefer to watch the video instead?
Managing a global army of 450+ developers, Devan has seen the "DevOps to DevSecOps to AI" evolution firsthand. Here are the core AI data security insights from his conversation on ShipTalk.
1. The Bedrock: Scaling to 450+ Developers
IBM’s internal "OnePipeline" isn't just a convenience; it’s a necessity. Built on Tekton (CI) and Argo CD, the platform has become the standard for both SaaS and on-prem deliveries.
- The "Speed vs. Value" Trade-off: During the migration from Travis CI to Tekton, build times initially jumped from 10 minutes to 30. However, the team realized this wasn't inefficiency—it was automated maturity. The extra time accounted for mandatory static, dynamic, and open source scanning.
- The Result: Audits for SOX, NIST, and ISO compliance changed from "scrambling for logs" to "pulling automated reports."
This transition highlights a growing industry trend: as code generation accelerates, the bottleneck shifts to delivery and security. This phenomenon, often called the AI Velocity Paradox, suggests that without downstream automation, upstream speed gains are often neutralized by manual security gates.
2. AI in the SDLC: "Bob" and the Rules of Engagement
IBM uses an internal AI coding agent called "Bob." But how do you ensure AI-generated code doesn't become technical debt?
"It’s not just about the code working; it’s about it being maintainable. If you don't provide context, the AI will build its own functions for JWT validation or encryption instead of using your existing, secure SDKs." — Devan Shah
To combat this, the team implements:
- Contextual Rules Files: Hard-coded guidelines that tell the AI which helper packages and security protocols to use.
- AI Code Reviews: Using LLMs to review PRs with specific guardrails, ensuring that "vibe coding" (quick POCs) is elevated to production-ready standards.
Quantifying the success of these initiatives is the next frontier. For organizations looking to move beyond "vibes" and toward hard data, the ebook Measuring the Impact of AI Development Tools offers a framework for tracking how these assistants actually affect cycle time and code quality.
3. AI Data Security: "Crown Jewels In, Crown Jewels Out"
We’ve all heard of "Garbage In, Garbage Out," but in the AI era, Devan warns of "Crown Jewels In, Crown Jewels Out." If you feed sensitive data or hard-coded secrets into an LLM training set, that model becomes a potential leak for attackers using sophisticated prompt injection.
The Rise of DSPM
Data Security Posture Management (DSPM) has emerged as a critical layer. It solves three major problems:
- Shadow Data Discovery: Finding where PII lives in unstructured formats (PDFs, logs, S3 buckets).
- Posture Verification: Identifying unencrypted buckets or public-facing databases.
- Data Flow Mapping: Detecting GDPR violations.
For a deeper technical look at how infrastructure must be architected to protect customer data in this environment, the Harness Data Security Whitepaper provides an excellent breakdown of security and privacy-by-design principles.
4. Architecting for the "Agentic" Future
We are moving beyond simple chatbots to Agentic Workflows—where AI agents talk to other agents and API endpoints.
- The Risk: An agent with "Full Admin" permissions could accidentally delete an entire cloud account if it misinterprets a prompt.
- The Solution: Architecting for Just-In-Time (JIT) token provisioning and Least Privilege access. Agents should only have the permissions they need for the exact second they are performing a task.
5. The "No Jail" Architectural Principle
When asked how to balance speed with security, Devan's philosophy is simple: Identify the "Bare Minimum 15." You don't need a list of 300 compliance checks to start, but you do need 10 to 15 non-negotiables:
- Automated CI/CD security gates: Ensuring every piece of code—AI or human—passes the same rigorous checks.
- An inventory of every AI model used: To prevent "Shadow AI."
- Pre-approved weight and training data reviews: For off-the-shelf models.
Final Thoughts
Whether you are a startup or a global giant like IBM, the goal of software delivery remains the same: Ship fast, but stay out of legal trouble. By integrating AI data security guardrails and robust data protection directly into the pipeline, security stops being a "speed bump" and starts being a foundational feature.
Want to dive deeper? Connect with Devan Shah on LinkedIn to follow his latest work, and subscribe to the ShipTalk podcast for more insights on using AI for everything after code.

Open Source Liquibase MongoDB Native Executor by Harness
Harness Database DevOps is introducing an open source native MongoDB executor for Liquibase Community Edition. The goal is simple: make MongoDB workflows easier, fully open, and accessible for teams already relying on Liquibase without forcing them into paid add-ons.
This launch focuses on removing friction for open source users, improving MongoDB success rates, and contributing meaningful functionality back to the community.
Why Does Liquibase MongoDB Support Matter for Open Source Users?
Teams using MongoDB often already maintain scripts, migrations, and operational workflows. However, running them reliably through Liquibase Community Edition has historically required workarounds, limited integrations, or commercial extensions.
This native executor changes that. It allows teams to:
- Run existing MongoDB scripts directly through Liquibase Community Edition.
- Avoid rewriting database workflows just to fit tooling limitations.
- Keep migrations versioned and automated alongside application CI/CD.
- Stay within a fully open source ecosystem.
This is important because MongoDB adoption continues to grow across developer platforms, fintech, eCommerce, and internal tooling. Teams want consistency: application code, infrastructure, and databases should all move through the same automation pipelines. The executor helps bring MongoDB into that standardised DevOps model.
It also reflects a broader philosophy: core database capabilities should not sit behind paywalls when the community depends on them. By open-sourcing the executor, Harness is enabling developers to move faster while keeping the ecosystem transparent and collaborative.
Liquibase MongoDB Native Executor: What It Enables In Community Edition
With the native MongoDB executor:
- Liquibase Community can execute MongoDB scripts natively
- Teams can reuse existing operational scripts
- Database changes become traceable and repeatable
- Migration workflows align with CI/CD practices
This improves the success rate for MongoDB users adopting Liquibase because the workflow becomes familiar rather than forced. Instead of adapting MongoDB to fit the tool, the tool now works with MongoDB.
How To Install The Liquibase MongoDB Extension (Step-By-Step)
1. Getting started is straightforward. The Liquibase MongoDB extension is hosted on HAR registry, which can be downloaded by using below command:
curl -L \
"https://us-maven.pkg.dev/gar-prod-setup/harness-maven-public/io/harness/liquibase-mongodb-dbops-extension/1.1.0-4.24.0/liquibase-mongodb-dbops-extension-1.1.0-4.24.0.jar" \
-o liquibase-mongodb-dbops-extension-1.1.0-4.24.0.jar
2. Add the extension to Liquibase: Place the downloaded JAR file into the Liquibase library directory, example path: "LIQUIBASE_HOME/lib/".
3. Configure Liquibase: Update the Liquibase configuration to point to the MongoDB connection and changelog files.
4. Run migrations: Use the "liquibase update" command and Liquibase Community will now execute MongoDB scripts using the native executor.
Generating MongoDB Changelogs From A Running Database
Migration adoption often stalls when teams lack a clean way to generate changelogs from an existing database. To address this, Harness is also sharing a Python utility that mirrors the behavior of "generate-changelog" for MongoDB environments.
The script:
- Connects to a live MongoDB instance
- Reads configuration and structure
- Produces a Liquibase-compatible changelog
- Helps teams transition from unmanaged MongoDB to versioned workflows
This reduces onboarding friction significantly. Instead of starting from scratch, teams can bootstrap changelogs directly from production-like environments. It bridges the gap between legacy MongoDB setups and modern database DevOps practices.
Why Is Harness Contributing This To Open Source?
The intent is not just to release a tool. The intent is to strengthen the open ecosystem.
Harness believes:
- Foundational database capabilities should remain accessible.
- Community users deserve production-ready tooling.
- Open contributions drive innovation faster than closed ecosystems.
By contributing a native MongoDB executor:
- Liquibase Community users gain real functionality.
- MongoDB adoption inside DevOps workflows becomes easier.
- The ecosystem remains open and collaborative.
- Higher success rate for MongoDB users adopting Liquibase Community.
This effort also reinforces Harness as an active open source contributor focused on solving real developer problems rather than monetizing basic functionality.
The Most Complete Open Source Liquibase MongoDB Integration Available Today
The native executor, combined with changelog generation support, provides:
- Script execution
- Migration automation
- Changelog creation from running environments
- CI/CD alignment
Together, these create one of the most functional open source MongoDB integrations available for Liquibase Community users. The objective is clear: make it the default path developers discover when searching for Liquibase MongoDB workflows.
Start Using and Contributing to Liquibase MongoDB Today
Discover the open-source MongoDB native executor. Teams can adopt it in their workflows, extend its capabilities, and contribute enhancements back to the project. Progress in database DevOps accelerates when the community collaborates and builds in the open.
Top Continuous Integration Metrics Every Platform Engineering Leader Should Track

Your developers complain about 20-minute builds while your cloud bill spirals out of control. Pipeline sprawl across teams creates security gaps you can't even see. These aren't separate problems. They're symptoms of a lack of actionable data on what actually drives velocity and cost.
The right CI metrics transform reactive firefighting into proactive optimization. With analytics data from Harness CI, platform engineering leaders can cut build times, control spend, and maintain governance without slowing teams down.
Why Do CI Metrics Matter for Platform Engineering Leaders?
Platform teams who track the right CI metrics can quantify exactly how much developer time they're saving, control cloud spending, and maintain security standards while preserving development velocity. The importance of tracking CI/CD metrics lies in connecting pipeline performance directly to measurable business outcomes.
Reclaim Hours Through Speed Metrics
Build time, queue time, and failure rates directly translate to developer hours saved or lost. Research shows that 78% of developers feel more productive with CI, and most want builds under 10 minutes. Tracking median build duration and 95th percentile outliers can reveal your productivity bottlenecks.
Harness CI delivers builds up to 8X faster than traditional tools, turning this insight into action.
Turn Compute Minutes Into Budget Predictability
Cost per build and compute minutes by pipeline eliminate the guesswork from cloud spending. AWS CodePipeline charges $0.002 per action-execution-minute, making monthly costs straightforward to calculate from your pipeline metrics.
Measuring across teams helps you spot expensive pipelines, optimize resource usage, and justify infrastructure investments with concrete ROI.
Measure Artifact Integrity at Scale
SBOM completeness, artifact integrity, and policy pass rates ensure your software supply chain meets security standards without creating development bottlenecks. NIST and related EO 14028 guidance emphasize on machine-readable SBOMs and automated hash verification for all artifacts.
However, measurement consistency remains challenging. A recent systematic review found that SBOM tooling variance creates significant detection gaps, with tools reporting between 43,553 and 309,022 vulnerabilities across the same 1,151 SBOMs.
Standardized metrics help you monitor SBOM generation rates and policy enforcement without manual oversight.
10 CI/CD Metrics That Move the Needle
Not all metrics deserve your attention. Platform engineering leaders managing 200+ developers need measurements that reveal where time, money, and reliability break down, and where to fix them first.
- Performance metrics show where developers wait instead of code. High-performing organizations achieve up to 440 times faster lead times and deploy 46 times more frequently by tracking the right speed indicators.
- Cost and resource indicators expose hidden optimization opportunities. Organizations using intelligent caching can reduce infrastructure costs by up to 76% while maintaining speed, turning pipeline data into budget predictability.
- Quality and governance metrics scale security without slowing delivery. With developers increasingly handling DevOps responsibilities, compliance and reliability measurements keep distributed teams moving fast without sacrificing standards.
So what does this look like in practice? Let's examine the specific metrics.
- Build Duration (p50/p95): Pinpointing Bottlenecks and Outliers
Build duration becomes most valuable when you track both median (p50) and 95th percentile (p95) times rather than simple averages. Research shows that timeout builds have a median duration of 19.7 minutes compared to 3.4 minutes for normal builds. That’s over five times longer.
While p50 reveals your typical developer experience, p95 exposes the worst-case delays that reduce productivity and impact developer flow. These outliers often signal deeper issues like resource constraints, flaky tests, or inefficient build steps that averages would mask. Tracking trends in both percentiles over time helps you catch regressions before they become widespread problems. Build analytics platforms can surface when your p50 increases gradually or when p95 spikes indicate new bottlenecks.
Keep builds under seven minutes to maintain developer engagement. Anything over 15 minutes triggers costly context switching. By monitoring both typical and tail performance, you optimize for consistent, fast feedback loops that keep developers in flow. Intelligent test selection reduces overall build durations by up to 80% by selecting and running only tests affected by the code changes, rather than running all tests.
An example of build durations dashboard (on Harness)
- Queue Time: Measuring Infrastructure Constraints
Queue time measures how long builds wait before execution begins. This is a direct indicator of insufficient build capacity. When developers push code, builds shouldn't sit idle while runners or compute resources are tied up. Research shows that heterogeneous infrastructure with mixed processing speeds creates excessive queue times, especially when job routing doesn't account for worker capabilities. Queue time reveals when your infrastructure can't handle developer demand.
Rising queue times signal it's time to scale infrastructure or optimize resource allocation. Per-job waiting time thresholds directly impact throughput and quality outcomes. Platform teams can reduce queue time by moving to Harness Cloud's isolated build machines, implementing intelligent caching, or adding parallel execution capacity. Analytics dashboards track queue time trends across repositories and teams, enabling data-driven infrastructure decisions that keep developers productive.
- Build Success Rate: Ensuring Pipeline Reliability
Build success rate measures the percentage of builds that complete successfully over time, revealing pipeline health and developer confidence levels. When teams consistently see success rates above 90% on their default branches, they trust their CI system to provide reliable feedback. Frequent failures signal deeper issues — flaky tests that pass and fail randomly, unstable build environments, or misconfigured pipeline steps that break under specific conditions.
Tracking success rate trends by branch, team, or service reveals where to focus improvement efforts. Slicing metrics by repository and pipeline helps you identify whether failures cluster around specific teams using legacy test frameworks or services with complex dependencies. This granular view separates legitimate experimental failures on feature branches from stability problems that undermine developer productivity and delivery confidence.
An example of Build Success/Failure Rate Dashboard (on Harness)
- Mean Time to Recovery (MTTR): Speeding Up Incident Response
Mean time to recovery measures how fast your team recovers from failed builds and broken pipelines, directly impacting developer productivity. Research shows organizations with mature CI/CD implementations see MTTR improvements of over 50% through automated detection and rollback mechanisms. When builds fail, developers experience context switching costs, feature delivery slows, and team velocity drops. The best-performing teams recover from incidents in under one hour, while others struggle with multi-hour outages that cascade across multiple teams.
Automated alerts and root cause analysis tools slash recovery time by eliminating manual troubleshooting, reducing MTTR from 20 minutes to under 3 minutes for common failures. Harness CI's AI-powered troubleshooting surfaces failure patterns and provides instant remediation suggestions when builds break.
- Flaky Test Rate: Eliminating Developer Frustration
Flaky tests pass or fail non-deterministically on the same code, creating false signals that undermine developer trust in CI results. Research shows 59% of developers experience flaky tests monthly, weekly, or daily, while 47% of restarted failing builds eventually passed. This creates a cycle where developers waste time investigating false failures, rerunning builds, and questioning legitimate test results.
Tracking flaky test rate helps teams identify which tests exhibit unstable pass/fail behavior, enabling targeted stabilization efforts. Harness CI automatically detects problematic tests through failure rate analysis, quarantines flaky tests to prevent false alarms, and provides visibility into which tests exhibit the highest failure rates. This reduces developer context switching and restores confidence in CI feedback loops.
- Cost Per Build: Controlling CI Infrastructure Spend
Cost per build divides your monthly CI infrastructure spend by the number of successful builds, revealing the true economic impact of your development velocity. CI/CD pipelines consume 15-40% of overall cloud infrastructure budgets, with per-run compute costs ranging from $0.40 to $4.20 depending on application complexity, instance type, region, and duration. This normalized metric helps platform teams compare costs across different services, identify expensive outliers, and justify infrastructure investments with concrete dollar amounts rather than abstract performance gains.
Automated caching and ephemeral infrastructure deliver the biggest cost reductions per build. Intelligent caching automatically stores dependencies and Docker layers. This cuts repeated download and compilation time that drives up compute costs.
Ephemeral build machines eliminate idle resource waste. They spin up fresh instances only when the queue builds, then terminate immediately after completion. Combine these approaches with right-sized compute types to reduce infrastructure costs by 32-43% compared to oversized instances.
- Cache Hit Rate: Accelerating Builds With Smart Caching
Cache hit rate measures what percentage of build tasks can reuse previously cached results instead of rebuilding from scratch. When teams achieve high cache hit rates, they see dramatic build time reductions. Docker builds can drop from five to seven minutes to under 90 seconds with effective layer caching. Smart caching of dependencies like node_modules, Docker layers, and build artifacts creates these improvements by avoiding expensive regeneration of unchanged components.
Harness Build and Cache Intelligence eliminates the manual configuration overhead that traditionally plagues cache management. It handles dependency caching and Docker layer reuse automatically. No complex cache keys or storage management required.
Measure cache effectiveness by comparing clean builds against fully cached runs. Track hit rates over time to justify infrastructure investments and detect performance regressions.
- Test Cycle Time: Optimizing Feedback Loops
Test cycle time measures how long it takes to run your complete test suite from start to finish. This directly impacts developer productivity because longer test cycles mean developers wait longer for feedback on their code changes. When test cycles stretch beyond 10-15 minutes, developers often switch context to other tasks, losing focus and momentum. Recent research shows that optimized test selection can accelerate pipelines by 5.6x while maintaining high failure detection rates.
Smart test selection optimizes these feedback loops by running only tests relevant to code changes. Harness CI Test Intelligence can slash test cycle time by up to 80% using AI to identify which tests actually need to run. This eliminates the waste of running thousands of irrelevant tests while preserving confidence in your CI deployments.
- Pipeline Failure Cause Distribution: Prioritizing Remediation
Categorizing pipeline issues into domains like code problems, infrastructure incidents, and dependency conflicts transforms chaotic build logs into actionable insights. Harness CI's AI-powered troubleshooting provides root cause analysis and remediation suggestions for build failures. This helps platform engineers focus remediation efforts on root causes that impact the most builds rather than chasing one-off incidents.
Visualizing issue distribution reveals whether problems are systemic or isolated events. Organizations using aggregated monitoring can distinguish between infrastructure spikes and persistent issues like flaky tests. Harness CI's analytics surface which pipelines and repositories have the highest failure rates. Platform teams can reduce overall pipeline issues by 20-30%.
- Artifact Integrity Coverage: Securing the Software Supply Chain
Artifact integrity coverage measures the percentage of builds that produce signed, traceable artifacts with complete provenance documentation. This tracks whether each build generates Software Bills of Materials (SBOMs), digital signatures, and documentation proving where artifacts came from. While most organizations sign final software products, fewer than 20% deliver provenance data and only 3% consume SBOMs for dependency management. This makes the metric a leading indicator of supply chain security maturity.
Harness CI automatically generates SBOMs and attestations for every build, ensuring 100% coverage without developer intervention. The platform's SLSA L3 compliance capabilities generate verifiable provenance and sign artifacts using industry-standard frameworks. This eliminates the manual processes and key management challenges that prevent consistent artifact signing across CI pipelines.
Steps to Track CI/CD Metrics and Turn Insights Into Action
Tracking CI metrics effectively requires moving from raw data to measurable improvements. The most successful platform engineering teams build a systematic approach that transforms metrics into velocity gains, cost reductions, and reliable pipelines.
Step 1: Standardize Pipeline Metadata Across Teams
Tag every pipeline with service name, team identifier, repository, and cost center. This standardization creates the foundation for reliable aggregation across your entire CI infrastructure. Without consistent tags, you can't identify which teams drive the highest costs or longest build times.
Implement naming conventions that support automated analysis. Use structured formats like team-service-environment for pipeline names and standardize branch naming patterns. Centralize this metadata using automated tag enforcement to ensure organization-wide visibility.
Step 2: Automate Metric Collection and Visualization
Modern CI platforms eliminate manual metric tracking overhead. Harness CI provides dashboards that automatically surface build success rates, duration trends, and failure patterns in real-time. Teams can also integrate with monitoring stacks like Prometheus and Grafana for live visualization across multiple tools.
Configure threshold-based alerts for build duration spikes or failure rate increases. This shifts you from fixing issues after they happen to preventing them entirely.
Step 3: Analyze Metrics and Identify Optimization Opportunities
Focus on p95 and p99 percentiles rather than averages to identify critical performance outliers. Drill into failure causes and flaky tests to prioritize fixes with maximum developer impact. Categorize pipeline failures by root cause — environment issues, dependency problems, or test instability — then target the most frequent culprits first.
Benchmark cost per build and cache hit rates to uncover infrastructure savings. Optimized caching and build intelligence can reduce build times by 30-40% while cutting cloud expenses.
Step 4: Operationalize Improvements With Governance and Automation
Standardize CI pipelines using centralized templates and policy enforcement to eliminate pipeline sprawl. Store reusable templates in a central repository and require teams to extend from approved templates. This reduces maintenance overhead while ensuring consistent security scanning and artifact signing.
Establish Service Level Objectives (SLOs) for your most impactful metrics: build duration, queue time, and success rate. Set measurable targets like "95% of builds complete within 10 minutes" to drive accountability. Automate remediation wherever possible — auto-retry for transient failures, automated cache invalidation, and intelligent test selection to skip irrelevant tests.
Make Your CI Metrics Work
The difference between successful platform teams and those drowning in dashboards comes down to focus. Elite performers track build duration, queue time, flaky test rates, and cost per build because these metrics directly impact developer productivity and infrastructure spend.
Start with the measurements covered in this guide, establish baselines, and implement governance that prevents pipeline sprawl. Focus on the metrics that reveal bottlenecks, control costs, and maintain reliability — then use that data to optimize continuously.
Ready to transform your CI metrics from vanity to velocity? Experience how Harness CI accelerates builds while cutting infrastructure costs.
Continuous Integration Metrics FAQ
Platform engineering leaders often struggle with knowing which metrics actually move the needle versus creating metric overload. These answers focus on metrics that drive measurable improvements in developer velocity, cost control, and pipeline reliability.
What separates actionable CI metrics from vanity metrics?
Actionable metrics directly connect to developer experience and business outcomes. Build duration affects daily workflow, while deployment frequency impacts feature delivery speed. Vanity metrics look impressive, but don't guide decisions. Focus on measurements that help teams optimize specific bottlenecks rather than general health scores.
Which CI metrics have the biggest impact on developer productivity?
Build duration, queue time, and flaky test rate directly affect how fast developers get feedback. While coverage monitoring dominates current practices, build health and time-to-fix-broken-builds offer the highest productivity gains. Focus on metrics that reduce context switching and waiting.
How do CI metrics help reduce infrastructure costs without sacrificing quality?
Cost per build and cache hit rate reveal optimization opportunities that maintain quality while cutting spend. Intelligent caching and optimized test selection can significantly reduce both build times and infrastructure costs. Running only relevant tests instead of entire suites cuts waste without compromising coverage.
What's the most effective way to start tracking CI metrics across different tools?
Begin with pipeline metadata standardization using consistent tags for service, team, and cost center. Most CI platforms provide basic metrics through built-in dashboards. Start with DORA metrics, then add build-specific measurements as your monitoring matures.
How often should teams review CI metrics and take action?
Daily monitoring of build success rates and queue times enables immediate issue response. Weekly reviews of build duration trends and monthly cost analysis drive strategic improvements. Automated alerts for threshold breaches prevent small problems from becoming productivity killers.
The Modern Software Delivery Platform®
Need more info? Contact Sales