How Harness Gets Ship Done With Zero Downtime and CD

Harness achieved zero downtime deployments by supporting multiple active versions of its Manager and Delegates, ensuring compatibility and seamless upgrades without disrupting ongoing customer executions. This approach, akin to Blue-Green deployment but more flexible, allows for instant rollback and daily production deployments, with rollbacks utilized twice in the last four weeks.
This is an engineer’s perspective on how we have achieved zero downtime, zero impact deployments. Let’s start with a simplified architecture overview of Harness workflow engine which is relevant to this topic.
Overview
Harness has a key component called Manager which is responsible for orchestrating pipeline and workflow executions. Manager is a scaled out, multi-tenant service which coordinates with Delegates for execution of workflow steps.
Delegates are Harness managed processes running on the customers’ premises. This is a critical piece of Harness architecture which enables Harness to orchestrate complex workflows in customers’ environments without the need to have access to customers’ resources (only customer delegates need to have access to customer resources).
The following is a sample pipeline execution:

Each box in this diagram represents a State. For States which interact with customer resources, execution requires communication between Manager and customer delegates. Since only delegates have access to customer resources, they are the one doing the actual work.
The following block diagram illustrates one such State’s execution flow. Block M represent Manager process and Block D represent Delegate process.

- Execution/Notify Event is Queued
- Event is dequeued and processed by a Manager
- [If needed] Manager Creates a Task [to be executed on a Delegate]
- Task is processed by a Manager
- Task is assigned to a Delegate. Delegate begins execution.
- Delegate reports status of task to Manager
Flow goes back to Step 1 if State Machine is not in terminal state.
Key Challenges
Manager is a multi-tenant service which runs in a Kubernetes Cluster. Delegates are standalone processes which run at customers’ premises. There may be thousands of delegate processes (multiple delegates per customer) and this will increase by an order of magnitude as we grow. The delegates sit on customers’ premises in diverse environments and varying quality of network connectivity. While Manager, being a central service, can upgrade more reliably and much quicker, the upgrade process of delegates takes a variable amount of time to converge. This creates a unique challenge for our upgrade process.
For reliable execution, it is required that all the processes involved in an execution are compatible with each other.
The following two diagrams show cases where incompatible versions are involved in an execution (color represents a particular version of service):

The above diagram depicts a scenario where Delegates are on a different version than Manager.

The above diagram depicts a scenario where one Manager instance is on a different version than other.
Additionally, for Harness SaaS, at any given time there are many customer executions of workflows in progress. There is never a good time to upgrade Harness where customers would not have ongoing activity. We need to make sure these executions are unaffected as we upgrade Harness itself.
Our Approach: Support Multiple Active Versions
To achieve seamless upgrades we went with approach to support multiple active versions. All the entities involved in an Execution are aware of their version; and only compatible versions do participate in an execution.
The following diagram illustrates this. Note that colored entities are version aware. Calls from Manager to Delegate are versioned (using HTTP Headers), and Queue and Task entities are versioned such that only compatible Manager processes work on them.

Let’s zoom in to Manager side implementation. The following diagram depicts the Traffic flow for Manager, which is a Kubernetes deployment. It has a Load Balancer, Ingress Controller, Kubernetes Service, and Manager Pods.

We create a version specific Deployment, Service, and Ingress object for every Manager version we deploy. Traffic from a Delegate comes to the same version of Manager pod due to HTTP header-based Ingress rules. In addition we have a Primary Service, which points to a particular version of Manager pods at a time. All customer traffic goes to the primary service.
When a new version needs to be deployed, we keep the old versions running and in parallel bring up the new version (shown in green in above diagram), both at manager and delegate side (this is akin to Blue-Green but more flexible as it can have more than two versions active).
All existing executions keep progressing on the previous version without disruption. No customer request hits the new version yet since the Primary Service still points to the older version. This gives delegates ample opportunity to bring up processes with the new version and register themselves with the new Manager.
When the verification is completed the new version is primed and ready to serve customer requests with all Delegate connectivity up. At this time Primary Service is updated to point to the new version and new calls from users start going to the new version. See the following diagram.

Note that we keep old version of Manager and Delegates for an extended period of time. The executions which started on the old version continue to make progress on the same version. These executions could take hours to finish (e.g. long pipelines with verifications, triggering Jenkins jobs, and waiting for them to complete).
Keeping the old version gives us additional capability of instant rollback. Since all the delegates of the old version are still up and connected to the old version of Manager, rollback simply requires flipping Primary Service back to the old version of Manager. This saves us warmup time to bring up the delegate processes discussed earlier.
On the delegate side, we have a similar capability of running multiple versions in parallel. An agent [called watcher] on the delegate box takes a goal state of desired versions and makes sure those versions are up and running on the delegate box. Each of these delegate processes connect to their corresponding version of Managers using HTTP header-based routing.
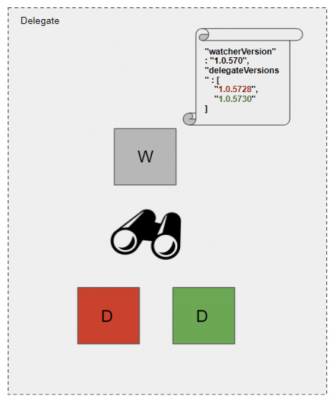
Though we have a mechanism for keeping multiple versions active at a time, for operational simplicity, it’s kept at two versions at any given time (n+1 version rollout tears down n-1).
Of course we use Harness for deploying Harness, and the following shows an execution of our own deployment:

The deployment steps are:
- Teardown n-1 version of Manager / Delegate
- Deploy n+1 version
- Verify the service health on n+1
- Switch Primary to n+1
This mechanism enables us to achieve zero downtime, anytime upgrades of Harness. Our production deployment happens once per day. Rollback mechanism has been used twice in last 4 weeks.
We are constantly evolving our system, and happy to share our knowledge as we do.
Puneet & Brett.

Next-generation CI/CD For Dummies
Stop struggling with tools—master modern CI/CD and turn deployment headaches into smooth, automated workflows.