
Harness's Cloud Cost Management platform enables businesses to optimize Kubernetes workloads and clusters through programmatic recommendations, leading to significant cost savings and increased operational efficiency. By leveraging the Recommendations API, organizations can automate the analysis and implementation of cost-saving measures, ensuring optimal resource utilization and density.
Harness’s Cloud Cost Management (CCM) platform is a robust platform designed to save you costs in the public cloud. Cloud cost optimization is essential, and rightsizing and eventually bin-packing resources is key to increasing density and reducing costs. Keeping track of the usage over time and understanding trends can be an exercise in math and keeping track of a high fidelity of metrics. Harness CCM Recommendations allow for the hard work to be taken away with prudent recommendations being made around Kubernetes workloads.
With the introduction of the Recommendations API, there are now programmatic ways to gather the insights and recommendations that Harness CCM provides. With a GraphQL query, you can retrieve the results of every Kubernetes cluster CCM is observing.
Kubernetes Recommendations by API
Implementing your first recommendation, gathering insights provided by CCM can benefit every workload CCM observes. The Recommendations API is a great way of garnering insights across Kubernetes clusters and scaling cost savings across the enterprise.
Leveraging the API Explorer by going to Setup -> Harness API Explorer, you can execute the needed GraphQL queries. When formulating the query, you will need to decide on what percentile of the sampling you would like to receive back in the query, then filtering the appropriate results as the query variables.
If you are unfamiliar with how the sampling is taken, samplings use actual CPU and memory utilization and are analyzed with a histogram method. Digging into the Recommendations UI can help visualize what sampling percentile you would like to receive back from the Recommendation API.
By adjusting the utilization sampling, you’re able to tune a recommendation to lean more heavily into a cost-optimized workload, or a performance-optimized workload. In this way, you’re not just trusting a rightsizing recommendation, you’re defining yourself what data goes into the recommendation and saving time and effort doing data validation and proposing alternative recommendations.
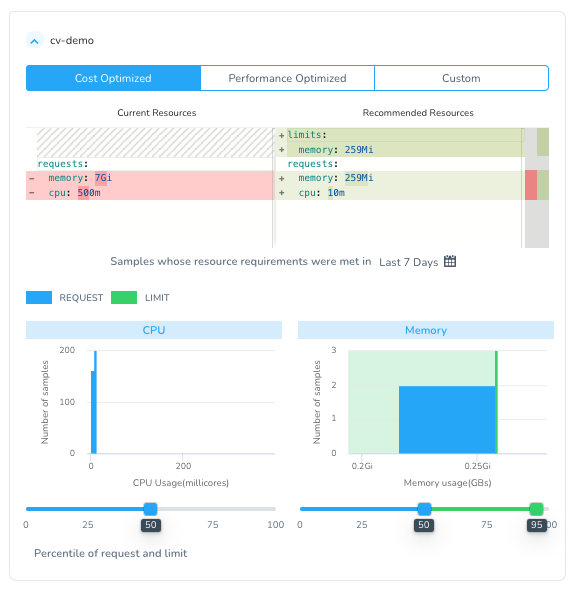
The Recommendations UI showing percentiles.
Executing Your First Recommendation API Query
The Harness Documentation has an excellent GraphQL query to get you underway. The only two parts to tune would be the percentile of sampling in the query and what data to filter down in the query variables.
The percent “ p50 ” element can be changed to another sampling percent.

Query:
query ($filters: [WorkloadFilter], $limit: Int!) {
k8sWorkloadRecommendations(filters: $filters, limit: $limit) {
nodes {
estimatedSavings
namespace
workloadName
clusterName
workloadType
containerRecommendations {
containerName
current {
requests {
name
quantity
}
limits {
name
quantity
}
}
recommended {
requests {
name
quantity
}
limits {
name
quantity
}
}
p50 {
requests {
name
quantity
}
limits {
name
quantity
}
}
}
}
}
}
With the query variables, you can add/remove/modify the filters to show more or fewer results. In this example, removing the filters for specific clusters so all clusters with Deployments into the default Namespace. Could easily remove the Namespace filter so all Deployments across all clusters would be presented.
Query Variables:
{
"filters": [
{
"namespace": {
"operator": "EQUALS",
"values": ["default"]
},
"workloadType": {
"operator": "IN",
"values": ["Deployment"]
}
}
],
"limit": 1000
}
Can execute the query and query variables in the API Explorer.
Setup -> Harness API Explorer.
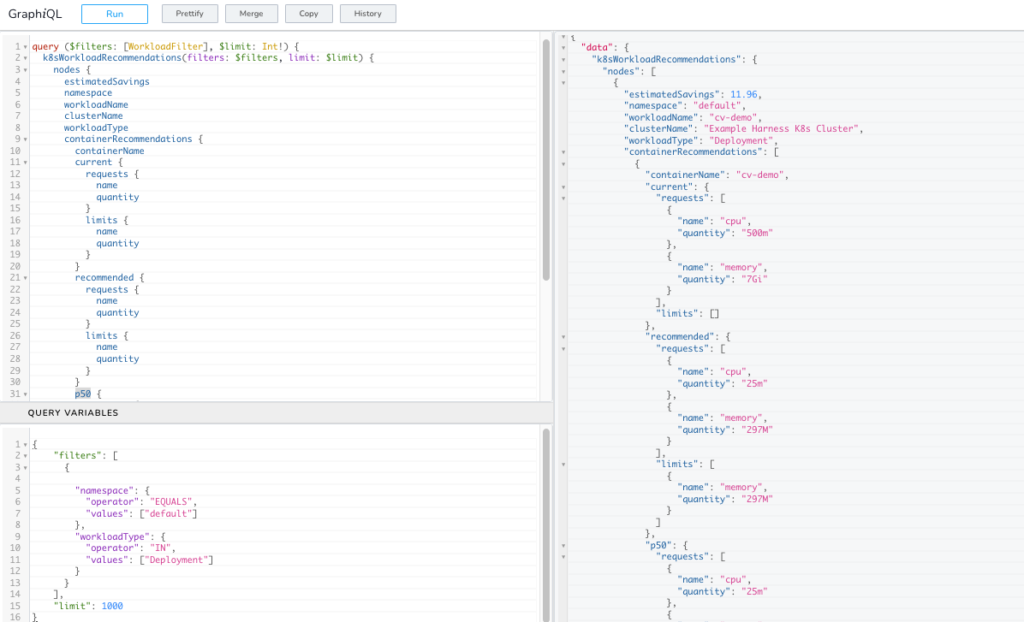
Executing the Recommendation GraphQL Query.
With the recommendations returned, you can see the recommendations in different sampling percentiles.
Result:
{
"data": {
"k8sWorkloadRecommendations": {
"nodes": [
{
"estimatedSavings": 11.96,
"namespace": "default",
"workloadName": "cv-demo",
"clusterName": "Example Harness K8s Cluster",
"workloadType": "Deployment",
"containerRecommendations": [
{
"containerName": "cv-demo",
"current": {
"requests": [
{
"name": "cpu",
"quantity": "500m"
},
{
"name": "memory",
"quantity": "7Gi"
}
],
"limits": []
},
"recommended": {
"requests": [
{
"name": "cpu",
"quantity": "25m"
},
{
"name": "memory",
"quantity": "297M"
}
],
"limits": [
{
"name": "memory",
"quantity": "297M"
}
]
},
"p50": {
"requests": [
{
"name": "cpu",
"quantity": "25m"
},
{
"name": "memory",
"quantity": "258M"
}
],
"limits": [
{
"name": "cpu",
"quantity": "25m"
},
{
"name": "memory",
"quantity": "258M"
}
]
}
}
]
},
{
"estimatedSavings": null,
"namespace": "default",
"workloadName": "harness-example-deployment",
"clusterName": "Example Harness K8s Cluster",
"workloadType": "Deployment",
"containerRecommendations": [
{
"containerName": "harness-example",
"current": {
"requests": [],
"limits": []
},
"recommended": {
"requests": [
{
"name": "cpu",
"quantity": "25m"
},
{
"name": "memory",
"quantity": "250M"
}
],
"limits": [
{
"name": "memory",
"quantity": "250M"
}
]
},
"p50": {
"requests": [
{
"name": "cpu",
"quantity": "25m"
},
{
"name": "memory",
"quantity": "250M"
}
],
"limits": [
{
"name": "cpu",
"quantity": "25m"
},
{
"name": "memory",
"quantity": "250M"
}
]
}
}
]
}
]
}
}
}
The next step would be to take action against the workload.
How to Rightsize a K8s Workload
With the Recommendations returned, simply tuning the workload’s resource limits and requests can be achieved with Harness. We have a detailed blog outlying the steps of implementing cloud cost savings. Though would be as simply modifying the manifests with the updated resource limits/requests and redeploying via Harness.
Before:

After:
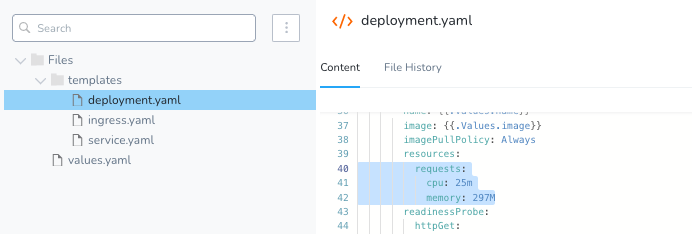
With the workloads tuned, the next step would be to tune and optimize the Kubernetes clusters themselves.
How to Rightsize a K8s Cluster
Looking across all of the insights, imagine if the next step would be to rightsize clusters when they get recreated.
For example, if using AWS EKS, the node machine type (e.g. what AWS EC2 instance types) is a crucial piece. For this example, I typically use a t3.xlarge which has 4 CPUs and 16 gigs of memory.
Though your operating system and Kubernetes have overhead. Assuming that the worker node has access to all 4 CPU shares and all 16 gigs of memory are actually not the case.
How Much Overhead does K8s Take?
The Kubernetes worker node has a few pieces of overhead that run. Each pod you run has overhead and there is a sunk Daemon cost on each node. Looking at a baseline with no workload on a worker node, you can see the amount of available resources if Kubernetes has access to 100% of the available resources after overhead.
SSHing into an empty worker node, by running free -m:
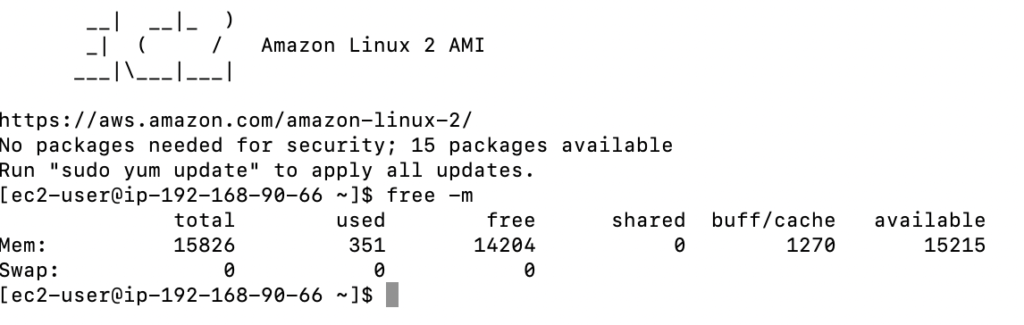
As you can see, this node only has 14.2 GB of free memory. If you had two pods with 8 GB of resources each, only one could get placed here.
Running Top on the empty worker node:
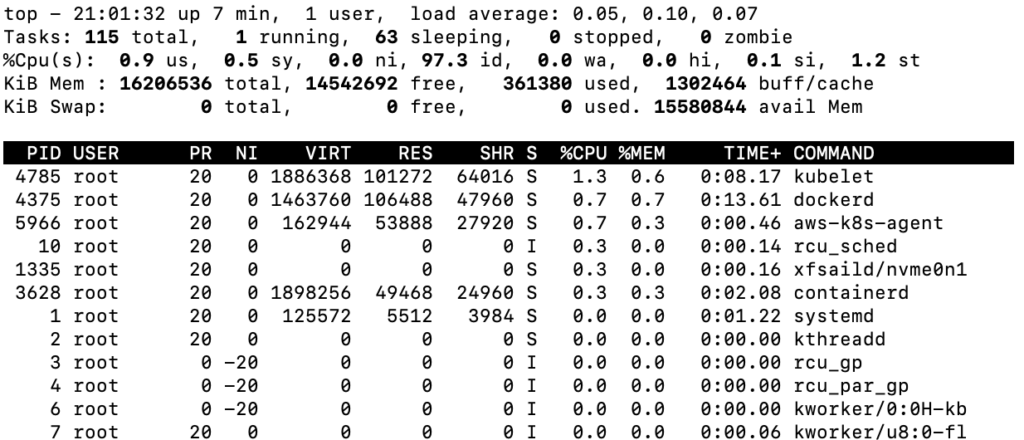
At any given time at idle that 1-3% of the CPU is being taken up between the kubelet (node agent), and the docker/container daemons.
Lots of Little Pods or a Few Large Pods
Understanding the actual availability of capacity for placement is key. Pod sizing is workload-dependent. Is there a benefit of having more smaller Pods vs fewer larger Pods? Depending on the workload if scaling and isolation is needed with smaller units, then having smaller Pods is a good idea. Though each Pod itself has overhead that takes away from the available capacity.
Kubernetes is certainly not set-and-forget when it comes to workload sizing and cluster sizing. Like any system and piece of software, optimization and tuning is an ongoing journey. The benefit of Kubernetes is the ability to recreate quicker, thus allowing for iteration.
Recreating Appropriate Sized Kubernetes Clusters
There is a two-way street when rightsizing Kubernetes clusters: Balancing the availability of cluster capacity for on-demand placement vs interrogating every workload and application owner over their usage.
Platform engineers are tasked with engineering efficiency and having sufficient capacity for Kubernetes clusters. Though the value proposition starts to diminish if there are stringent controls around workload placements and counterintuitive quotas placed, so the self-service capabilities that Kubernetes offers turn into the old virtual machine model.
Data and analysis are crucial when having a discussion and making tuning decisions. Harness CCM’s Recommendations can take the guesswork out of the actual usage over time.
By adding up the Recommendations across different workloads, recreating a Kubernetes cluster with a tool like EKSCTL, simply tuning the node-type and/or amount of nodes can result in cost savings.
#Create EKS Cluster
eksctl create cluster \
--name big-money-cluster \
--version 1.19 \
--region us-east-1 \
--nodegroup-name standard-workers \
--node-type t3.xlarge \
--nodes 2 \
--nodes-min 1 \
--nodes-max 3 \
--node-ami auto \
--ssh-access \
--ssh-public-key=some-ec2-key
With prudent tuning based on Harness CCM Recommendations, you are well on your way to increased density and cost savings.
Harness, Your Partner in Cloud Costs
At Harness, we are on a mission to democratize cloud spend and help disseminate valuable and prudent information as quickly as you consume cloud resources.
Not only limited to Kubernetes, but Harness CCM can help track and visualize public cloud spend across multiple resources which can also be extracted via API.
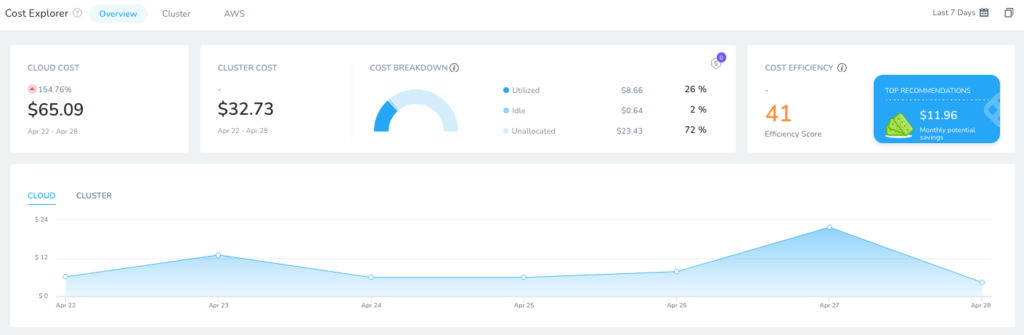
Harness CCM Dashboard.
Stay tuned and make sure to sign up for a demo of Cloud Cost Management today.
Cheers,
-Ravi

All this author’s posts
Ravi Lachhman builds the systems that help platforms scale.