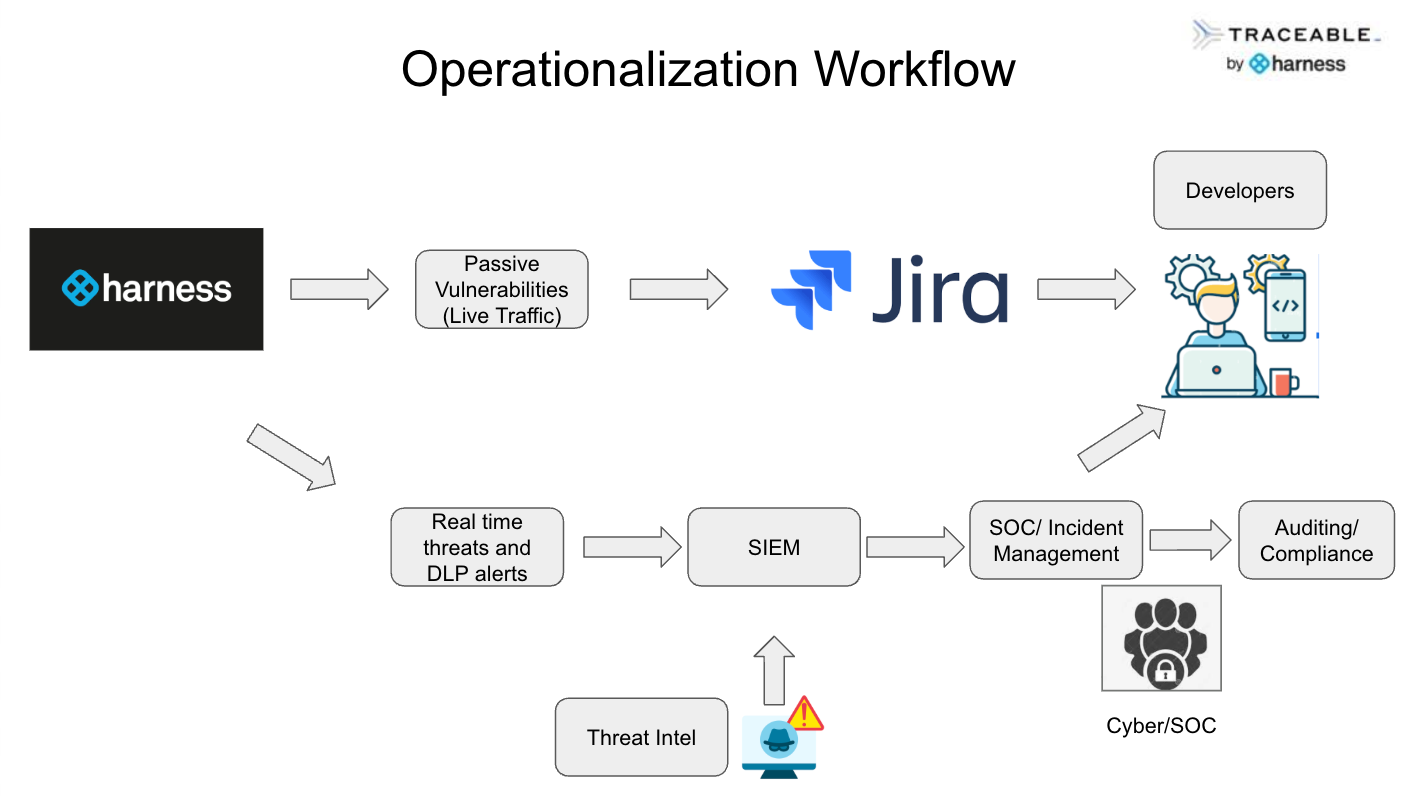
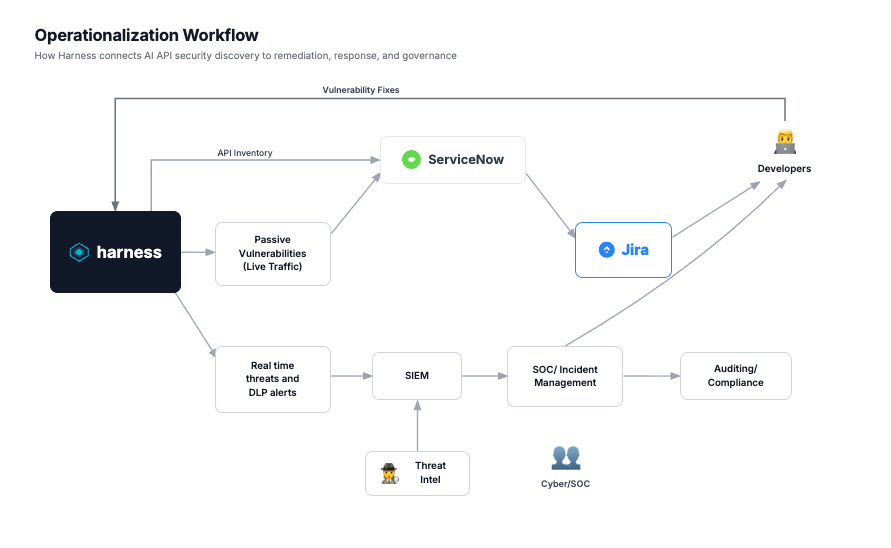
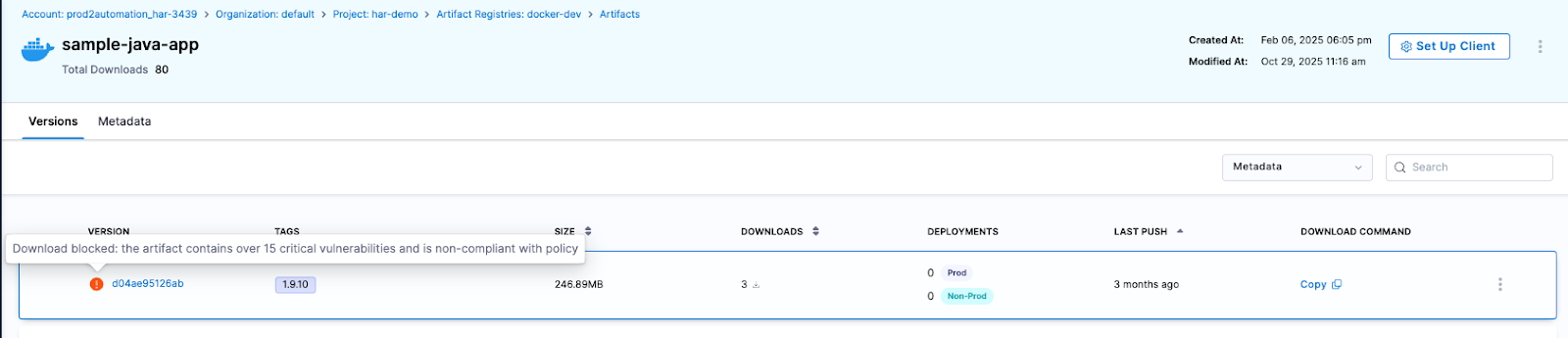
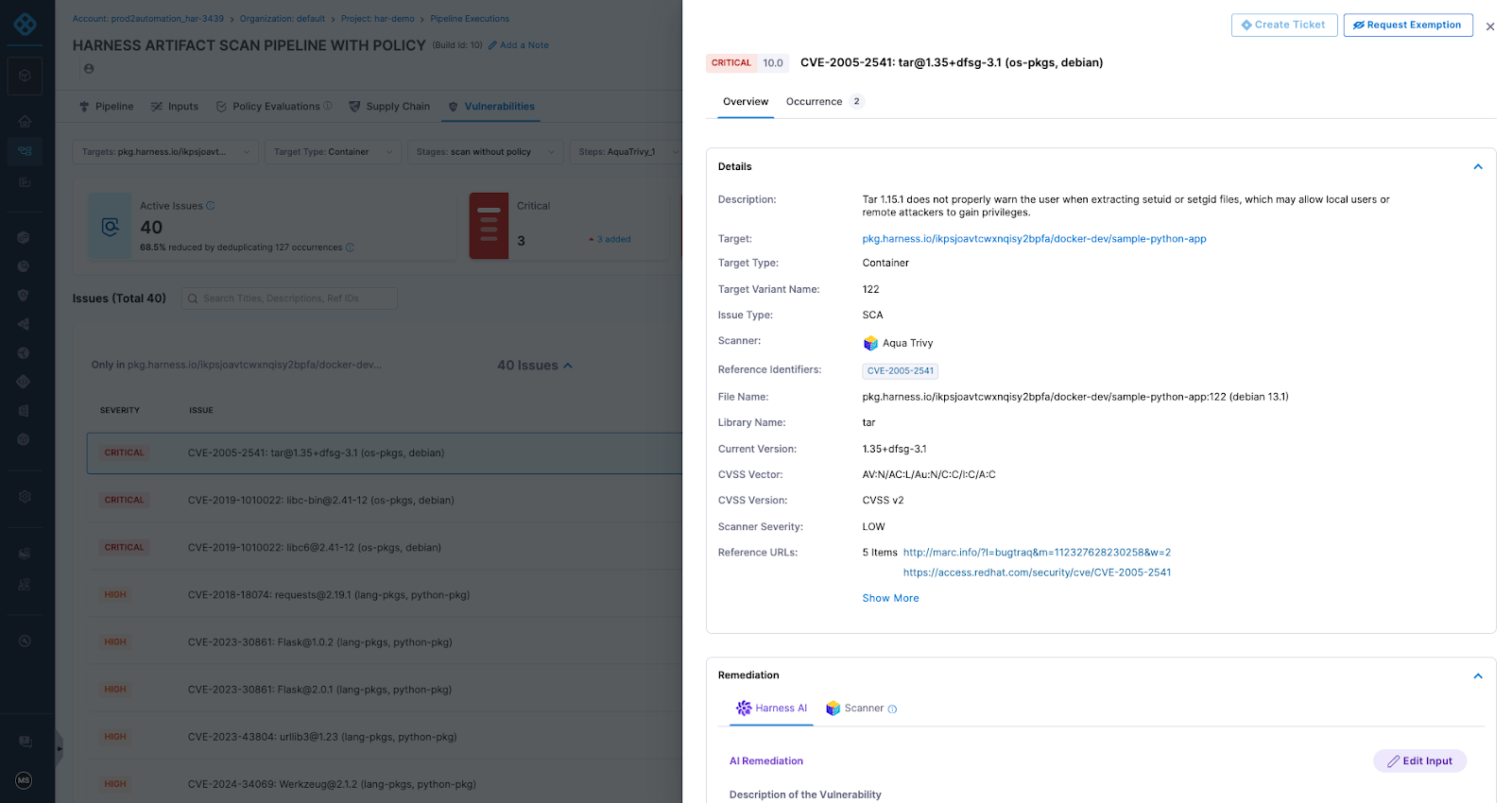
Featured Blogs

Key Takeaway: The Harness MCP Server is now in the official Claude Connectors Directory. Developers using Claude can now discover and connect to Harness, gaining structured, real-time access to their pipelines, deployments, approvals, and delivery workflows. What makes this different from a typical API integration is what's underneath: the Harness Software Delivery Knowledge Graph, which gives Claude the context it needs to make decisions that are accurate, fast, and safe.
AI agents are only as good as the context they operate in. That's not a design philosophy. It's a practical constraint. An AI agent that doesn't understand how the underlying software delivery entities relate to each other, or what the data actually means, will get things wrong. In software delivery, wrong looks like a botched deployment, a misread failure, or an approval granted when it shouldn't have been, which directly affects your users.
Today, we're announcing that the Harness MCP Server is in the official Claude Connectors Directory, making Harness discoverable and connectable for every team using Claude. But the announcement isn't really about the directory listing. It's about what Harness + Claude can actually do in your delivery system.
What You Can Do with Claude and Harness
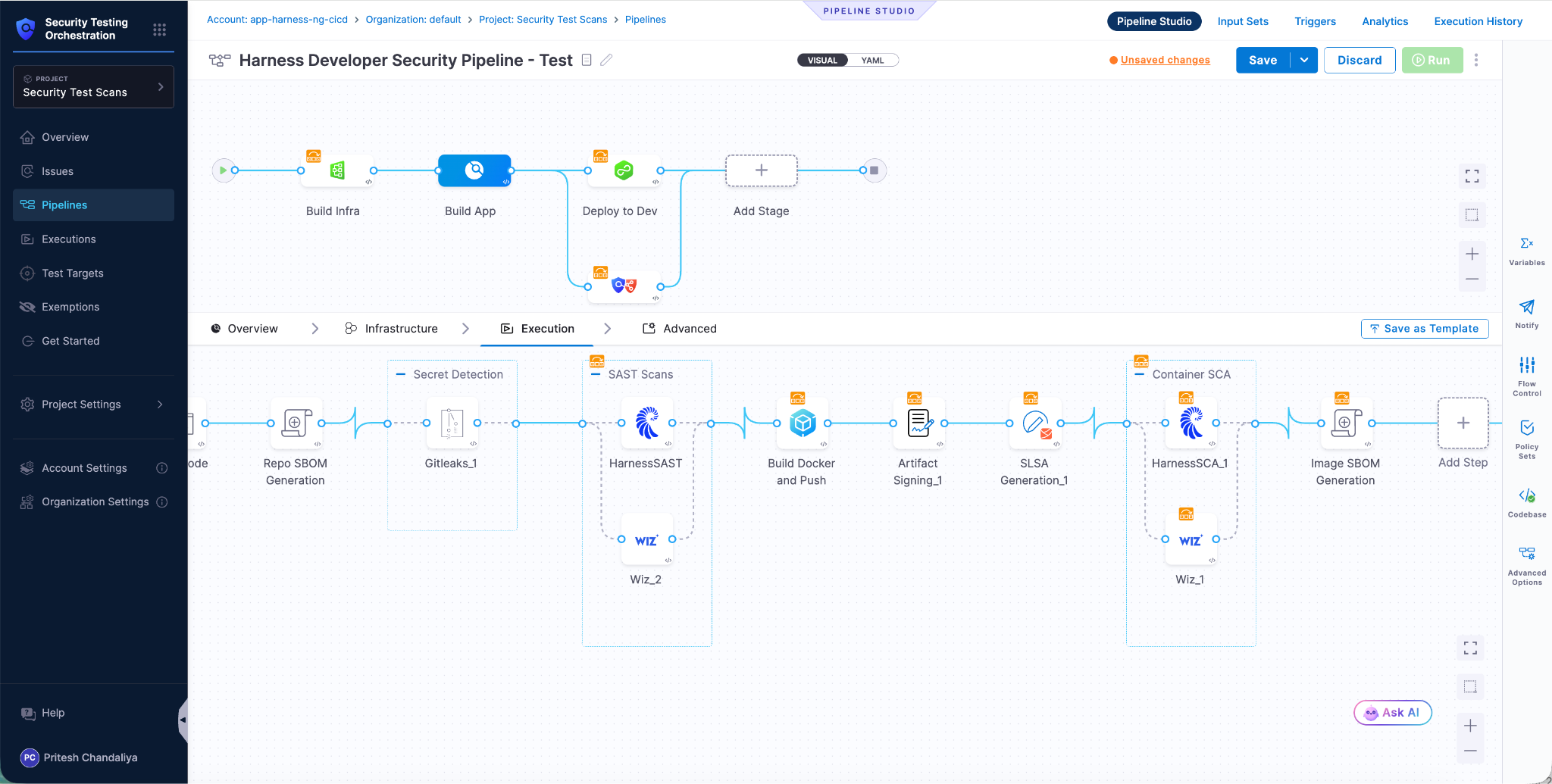
Claude can work across the full Harness delivery platform:
All of it is grounded in the Knowledge Graph, not raw API responses, but a structured model of your delivery system that Claude can reason over precisely.
The Problem With Giving AI Agents Raw API Access
MCP lets AI models call external tools by reading API descriptions and deciding which to invoke. That flexibility is useful. But when you're building an agent that needs to reason across an entire software delivery lifecycle, CI, CD, security scans, approvals, feature flags, cost signals, and environments, raw API access creates a deep reliability problem.
Consider a question a platform engineering lead might ask:
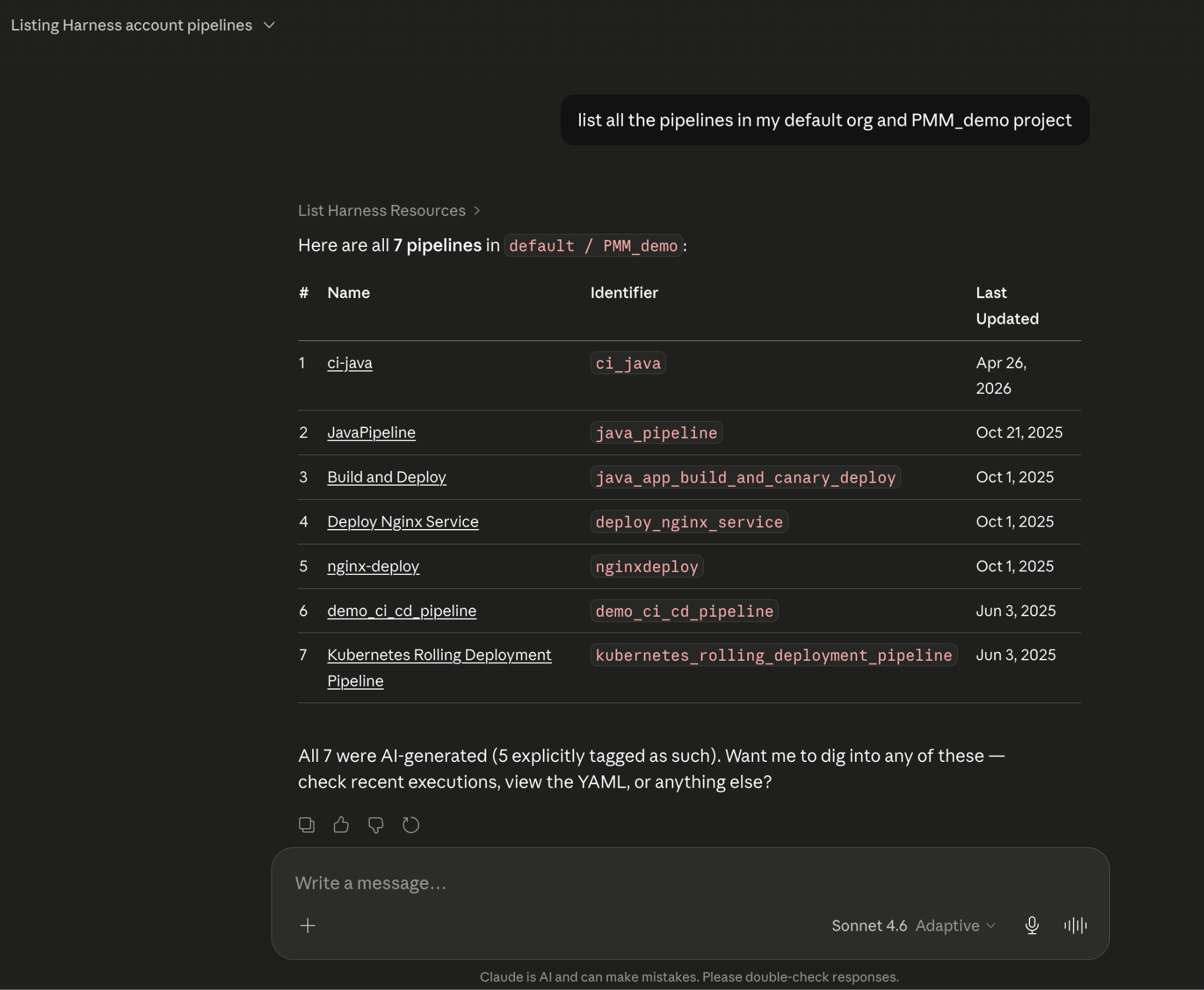
"Show me the pipelines with the highest failure rate over the last 30 days, and for each one, tell me which services they deploy and whether any of those services have open critical vulnerabilities."
That question spans four domains: pipeline execution history, service-to-pipeline relationships, environment state, and security scan results. An agent working off raw APIs has to discover which APIs exist across each domain, call them in the right order, paginate correctly, infer how field names correspond across systems, and synthesize the results without misinterpreting nested objects or guessing at relationships.
The result is 5+ sequential LLM calls, hundreds of thousands of input tokens, high latency, and an agent that had to guess at every join. Guessing is where hallucinations happen.
What the Harness + Claude Integration Changes
The Harness Software Delivery Knowledge Graph is a purpose-built model of everything that happens after code is written: builds, test runs, deployments, approvals, security scans, environment states, feature flags, infrastructure changes, cost signals, and rollbacks. Not as raw data but as a connected, typed, semantically annotated graph of entities and relationships.
Every field in the graph carries metadata that tells an agent exactly how to use it: whether a value is a number or a string, whether it can be aggregated or only filtered, what its unit is, and how it joins to related entities. Cross-module relationships, between a pipeline and the services it deploys, between a deployment and the security scan results for that artifact, between an environment change and the cost anomaly that followed, are explicitly declared, not inferred.
This is the difference between an agent that can access your delivery system and one that understands it.
When Claude connects to Harness via MCP, it doesn't receive a set of API endpoints. It's getting access to a structured model of your entire delivery organization, one where the relationships are known, the data types are enforced, and the agent can construct precise queries rather than guessing at field semantics.
The practical effect with Harness + Claude: that same cross-domain question above becomes 2–3 structured queries against a known schema. The agent selects the right entity types from the graph, generates queries with exact fields and declared relationships, and returns a deterministic answer. No guesswork. No hallucinated field names. No silent wrong answers.
What This Looks Like in Practice
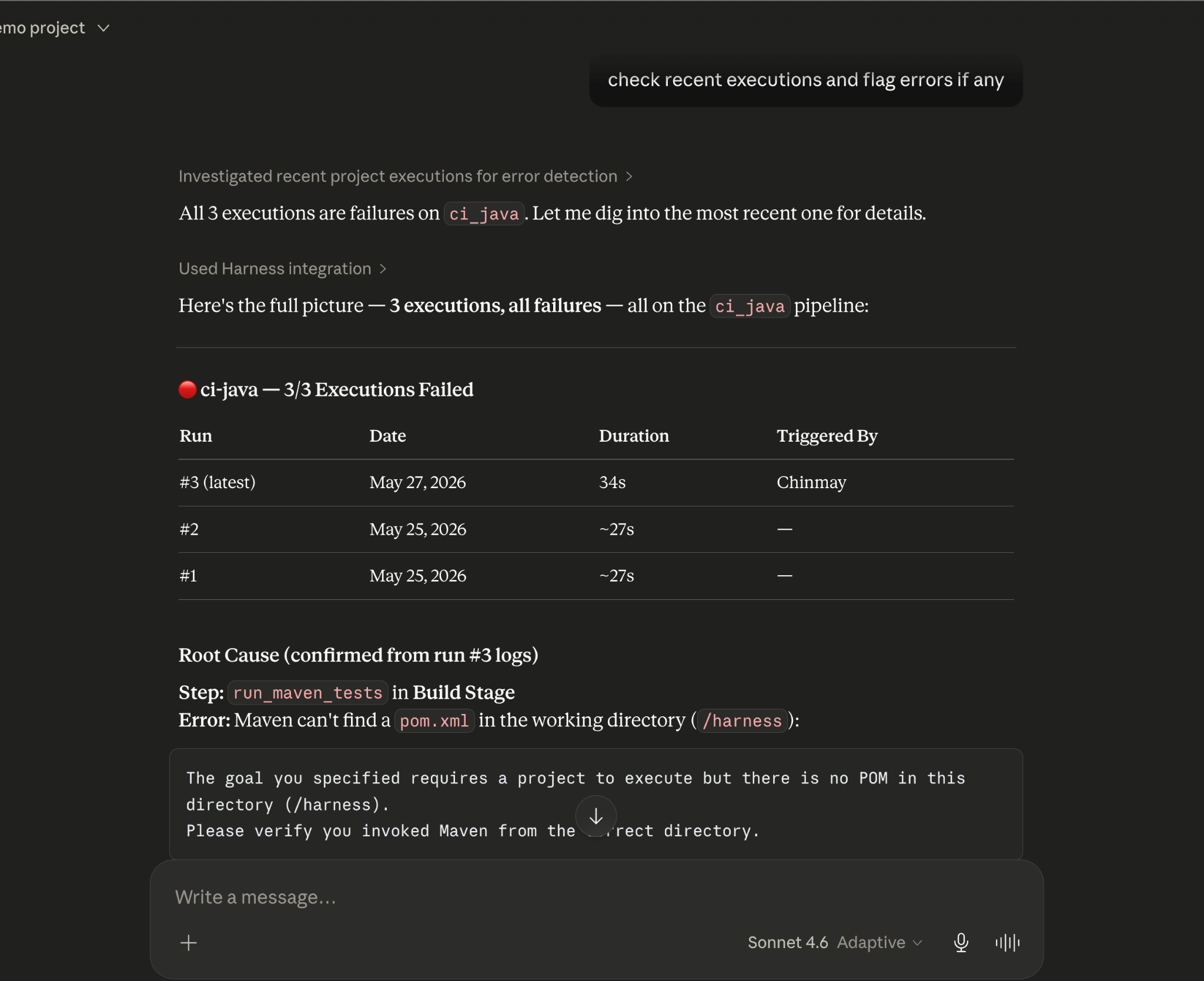
Debugging a failed pipeline without context switching
A build has failed. Normally, you'd open the Harness UI, navigate to the execution, copy the relevant logs, paste them into a conversation, and wait for analysis. The AI reasons over whatever you managed to capture.
With the Harness MCP connection active in Claude, you ask what failed. Claude doesn't just pull logs; it queries the Knowledge Graph to understand the structure of that pipeline, which stage failed, what services were involved, whether similar failures have occurred before, and what changed since the last successful run. The answer it surfaces reflects the full delivery context, not just the stack trace you happened to copy.
Promoting a deployment through governed gates
Your team is ready to move a service from staging to production. Claude checks the current environment state, verifies that required approval gates have been satisfied, confirms the security scan passed for the artifact version you're promoting, and initiates the deployment — with every action running through your existing RBAC policies and logged for audit.
The agent isn't guessing about whether conditions are met. It's querying a graph where those conditions are modeled as typed relationships with known states. The answer is deterministic because the data is structured to make it so.
This Is Not AI Without Guardrails
The natural question when Claude can trigger pipelines and manage deployments: what stops it from doing something it shouldn't?
The same controls that govern everything else in Harness. Every action taken through the MCP server runs through your existing RBAC permissions, OPA policy enforcement, approval gates, and audit logging. Claude operates with exactly the permissions you have, nothing more. Every action is tracked. Nothing bypasses the governance layer.
The Knowledge Graph reinforces this: because Harness AI understands your delivery system structurally, it also understands the constraints within it. Approval gates aren't just optional steps the agent might skip; they're modeled as typed relationships with state. The agent can't promote past a gate that hasn't cleared because the graph reflects that clearly.
Speed and governance aren't a tradeoff. They coexist by design.
Why the Claude Connectors Directory Matters
The Claude Connectors Directory is a curated, reviewed set of integrations. Anthropic evaluates each server before listing it. Being approved is a signal of trust that carries weight for enterprise teams deciding which AI integrations to enable.
It also means discoverability at scale: engineering teams using Claude for DevOps workflows will find Harness natively. One-click OAuth connection, no API key management, no manual configuration.
This fits a broader pattern. The Google Cloud partnership brought Harness into Google's AI ecosystem through Vertex AI and Gemini CLI. The Cursor plugin brought it into the IDE. The Claude Connectors Directory brings it into conversational AI. In each case, the goal is the same: wherever developers are doing their best thinking and wherever AI is being asked to help with software delivery, Harness should be present with the right context for that AI to act reliably.
Getting Started
If you're already a Harness customer:
- Open Claude and then the Connectors page
- Search for Harness in the MCP directory
- Authenticate with OAuth, no API keys, no manual configuration
- Start asking Claude about your pipelines, deployments, and delivery workflows
If you're new to Harness, sign up for free and connect from day one. Detailed steps are listed in the documentation.
The Harness Connector gives Claude the ability to act in your delivery system. The Knowledge Graph gives it the understanding to act well. Together, that's what reliable AI in software delivery actually looks like.

If 2024 was the year AI started quietly showing up in our workflows, 2025 was the year it kicked the door down.
AI-generated code and AI-powered workflows have become part of nearly every software team’s daily rhythm. Developers are moving faster than ever, automation is woven into every step, and new assistants seem to appear in the pipeline every week.
I’ve spent most of my career on both sides of the equation — first in security, then leading engineering teams — and I’ve seen plenty of “next big things” come and go. But this shift feels different. Developers are generating twice the code in half the time. It’s a massive leap forward — and a wake-up call for how we think about security.
The Question Everyone’s Asking
The question I hear most often is, “Has AI made coding less secure?”
Honestly, not really. The code itself isn’t necessarily worse — in fact, a lot of it’s surprisingly good. The real issue isn’t the quality of the code. It’s the sheer volume of it. More code means more surface area: more endpoints, more integrations, more places for something to go wrong.
Harness recently surveyed 500 security practitioners and decision makers responsible for securing AI-native applications from the United States, UK, Germany, and France to share findings on global security practices. In our latest report, The State of AI-Native Application Security 2025, 82% of security practitioners said AI-native applications are the new frontier for cybercriminals, and 63% believe these apps are more vulnerable than traditional ones.
It’s like a farmer suddenly planting five times more crops. The soil hasn’t changed, but now there’s five times more to water, tend, and protect from bugs. The same applies to software. Five times more code doesn’t just mean five times more innovation — it means five times more vulnerabilities to manage.
And the tools we’ve relied on for years weren’t built for this. Traditional security systems were designed for static codebases that changed every few months, not adaptive, learning models that evolve daily. They simply can’t keep pace.
And this is where visibility collapses.
The AI Visibility Problem
In our research, 63% of security practitioners said they have no visibility into where large language models are being used across their organizations. That’s the real crisis — not bad actors or broken tools, but the lack of understanding about what’s actually running and where AI is operating.
When a developer spins up a new AI assistant on their laptop or an analyst scripts a quick workflow in an unapproved tool, it’s not because they want to create risk. It’s because they want to move faster. The intent is good, but the oversight just isn’t there yet.
The problem is that our governance and visibility models haven’t caught up. Traditional security tools were built for systems we could fully map and predict. You can’t monitor a generative model the same way you monitor a server — it behaves differently, evolves differently, and requires a different kind of visibility.
Security Has to Move Closer to Engineering
Security has to live where engineering lives — inside the pipeline, not outside it.
That’s why we’re focused on everything after code: using AI to continuously test, validate, and secure applications after the code is written. Because asking humans to manually keep up with AI speed is a losing game.
If security stays at a checkpoint after development, we’ll always be behind. The future is continuous — continuous delivery, continuous validation, continuous visibility.
Developers Don’t Need to Slow Down — They Need Guardrails
In the same report, 74% of security leaders said developers view security as a barrier to innovation. I get it — security has a reputation for saying “no.” But the future of software delivery depends on us saying “yes, and safely.”
Developers shouldn’t have to slow down. They need guardrails that let them move quickly without losing control. That means automation that quietly scans for secrets, flags risky dependencies, and tests AI-generated code in real time — all without interrupting the creative flow.
AI isn’t replacing developers; it’s amplifying them. The teams that learn to work with it effectively will outpace everyone else.
Seeing What Matters
We’re generating more innovation than ever before, but if we can’t see where AI is working or what it’s touching, we’re flying blind.
Visibility is the foundation:
- Map where AI exists across your workflows, models, and pipelines.
- Automate validation so issues are caught continuously, not just at release time.
- Embed governance early, not as an afterthought.
- Align security and development around shared goals and shared ownership.
AI isn’t creating chaos — it’s revealing the chaos that was already there. And that’s an opportunity. Once you can see it, you can fix it.
You can read the full State of AI-Native Application Security 2025 report here.

Incident Date: March 14th, 2024 (discovered)
CVE: CVE-2025-30066
Updates on the incident
This section will be updated regularly based on available information, and analysis related to the incident. Following the report on the tj-actions/changed-files supply chain attack, new findings from Wiz Research reveal that the compromise may have originated from a separate attack on reviewdog/actions-setup@v1. This newly discovered breach likely led to the compromise of the tj-actions-bot's GitHub Personal Access Token (PAT), enabling attackers to modify the tj-actions/changed-files repository and cause widespread secret leaks. The attack involved injecting a base64-encoded payload directly into the install.sh script, impacting CI workflows across multiple repositories.
Given that reviewdog/actions-setup@v1 was compromised before the tj-actions incident and later stealthily reverted, there is a significant risk of recurrence. Security teams should take immediate action by identifying affected repositories, removing references to impacted actions, rotating any potentially exposed credentials, and enforcing stricter security practices such as pinning GitHub Actions to specific commit hashes. Wiz has disclosed these findings to reviewdog and GitHub, and we continue to monitor developments to prevent further supply chain threats.
Overview
On March 14, 2025, a major supply chain attack compromised the tj-actions/changed-files GitHub Action, widely used across 23,000+ repositories. The attackers modified the action’s code and updated multiple version tags to a malicious commit, causing workflows to execute a script that leaked sensitive CI/CD secrets through workflow logs.The compromise is also being tracked as a vulnerability, and has been assigned CVE-2025-30066.
Breaking Down the Attack
The attackers injected malicious code by spoofing the commit with a Node.js function including base64-encoded payloads, which were added to the GitHub Action tags. The payload, once decoded, revealed a script that downloaded additional malicious Python code from a GitHub Gist. The Python script then scanned the memory of the GitHub Runner’s "Runner.worker" process for sensitive credentials using regular expressions. Finally, the extracted secrets were printed in the workflow logs, exposing them to unauthorized access.
.png)
Immediate Measures to Control the Impact
To mitigate the risks associated with this attack, consider the following immediate actions:
- Allow-List GitHub Actions: Use GitHub’s allow-list to block compromised actions and keep it updated with trusted ones.
- Pin GitHub Actions to Specific Commit SHAs: Avoid using floating tags (@v35, @latest); always pin to a specific SHA for security.
- Rotate Secrets: Monitor logs for suspicious activity and immediately rotate any compromised secrets.
- Manage Workflow Logs: Delete affected logs after analysis to remove traces of exposed secrets.
How can Harness SCS help?
Harness Supply Chain Security (SCS) proactively secures your software supply chain by identifying and mitigating risks within your workflows. It scans for unverified dependencies, unpinned GitHub Actions, and critical security misconfigurations, ensuring vulnerabilities are detected and addressed before they can be exploited. Harness also enforces supply chain benchmarks, performs comprehensive security checks, and implements proactive measures to prevent future attacks.

1. Identify Unpinned Actions: Harness SCS detects unpinned actions in the pipeline workflow. Unpinned GitHub Actions can be modified, allowing attackers to inject malicious code into pipelines, potentially exposing secrets or altering source code.
2. Restrict Action Permissions: Running unverified GitHub Actions without restrictions increases the risk of executing malicious code from compromised or hijacked actions. Enforcing minimal permissions helps limit potential damage and enhance security.
3. Minimal Token Permissions: Use Harness SCS to find and apply minimal token permissions for GitHub Actions, reducing exposure and ensuring adherence to the principle of least privilege.

The SCS module provide additional rules to minimize the blast radius of supply chain risks or attacks, limiting the attack surface and strengthening security.
Integrating Harness SCS Runtime Analysis with Traceable - Coming Soon!
.png)
The Traceable eBPF agent is set to offer several features that will significantly enhance runtime protection for both GitHub Actions and Harness CI in the future:
- Detect Leaked Secrets: By integrating with GitHub’s log API, it will be able to detect sensitive secrets exposed in logs, helping to mitigate the risk of data leakage.
- Monitor External URLs: The agent will be capable of spotting unusual GitHub Action calls to external URLs, using a baseline technique to reduce noise and improve detection of suspicious activities.
- Identify Malicious RCE: It will also be able to detect malicious remote code execution (RCE) calls, such as scripts trying to print environment variables, helping to block potential threats before they escalate.
Conclusion
The tj-actions/changed-files supply chain attack highlights the increasing risks in CI/CD security. To prevent similar incidents, organizations must adopt proactive security measures and follow best practices, such as using pinned actions, auditing workflows, and enforcing strict access controls. Consider using the Harness SCS to prevent future attacks.







.png)





.png)
.png)
.png)