Featured Blogs

Key Takeaway: The Harness MCP Server is now in the official Claude Connectors Directory. Developers using Claude can now discover and connect to Harness, gaining structured, real-time access to their pipelines, deployments, approvals, and delivery workflows. What makes this different from a typical API integration is what's underneath: the Harness Software Delivery Knowledge Graph, which gives Claude the context it needs to make decisions that are accurate, fast, and safe.
AI agents are only as good as the context they operate in. That's not a design philosophy. It's a practical constraint. An AI agent that doesn't understand how the underlying software delivery entities relate to each other, or what the data actually means, will get things wrong. In software delivery, wrong looks like a botched deployment, a misread failure, or an approval granted when it shouldn't have been, which directly affects your users.
Today, we're announcing that the Harness MCP Server is in the official Claude Connectors Directory, making Harness discoverable and connectable for every team using Claude. But the announcement isn't really about the directory listing. It's about what Harness + Claude can actually do in your delivery system.
What You Can Do with Claude and Harness
Claude can work across the full Harness delivery platform:
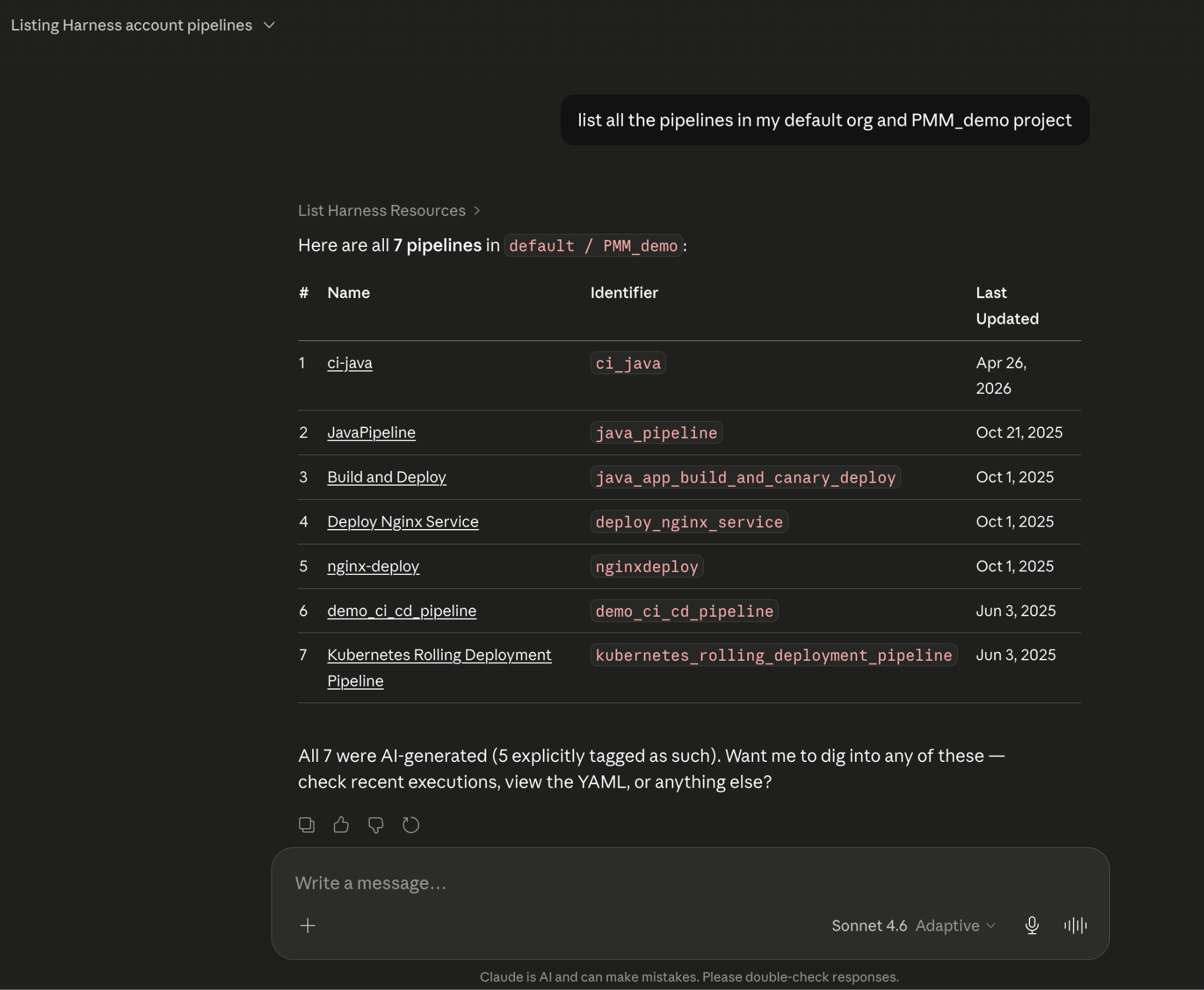
All of it is grounded in the Knowledge Graph, not raw API responses, but a structured model of your delivery system that Claude can reason over precisely.
The Problem With Giving AI Agents Raw API Access
MCP lets AI models call external tools by reading API descriptions and deciding which to invoke. That flexibility is useful. But when you're building an agent that needs to reason across an entire software delivery lifecycle, CI, CD, security scans, approvals, feature flags, cost signals, and environments, raw API access creates a deep reliability problem.
Consider a question a platform engineering lead might ask:
"Show me the pipelines with the highest failure rate over the last 30 days, and for each one, tell me which services they deploy and whether any of those services have open critical vulnerabilities."
That question spans four domains: pipeline execution history, service-to-pipeline relationships, environment state, and security scan results. An agent working off raw APIs has to discover which APIs exist across each domain, call them in the right order, paginate correctly, infer how field names correspond across systems, and synthesize the results without misinterpreting nested objects or guessing at relationships.
The result is 5+ sequential LLM calls, hundreds of thousands of input tokens, high latency, and an agent that had to guess at every join. Guessing is where hallucinations happen.
What the Harness + Claude Integration Changes
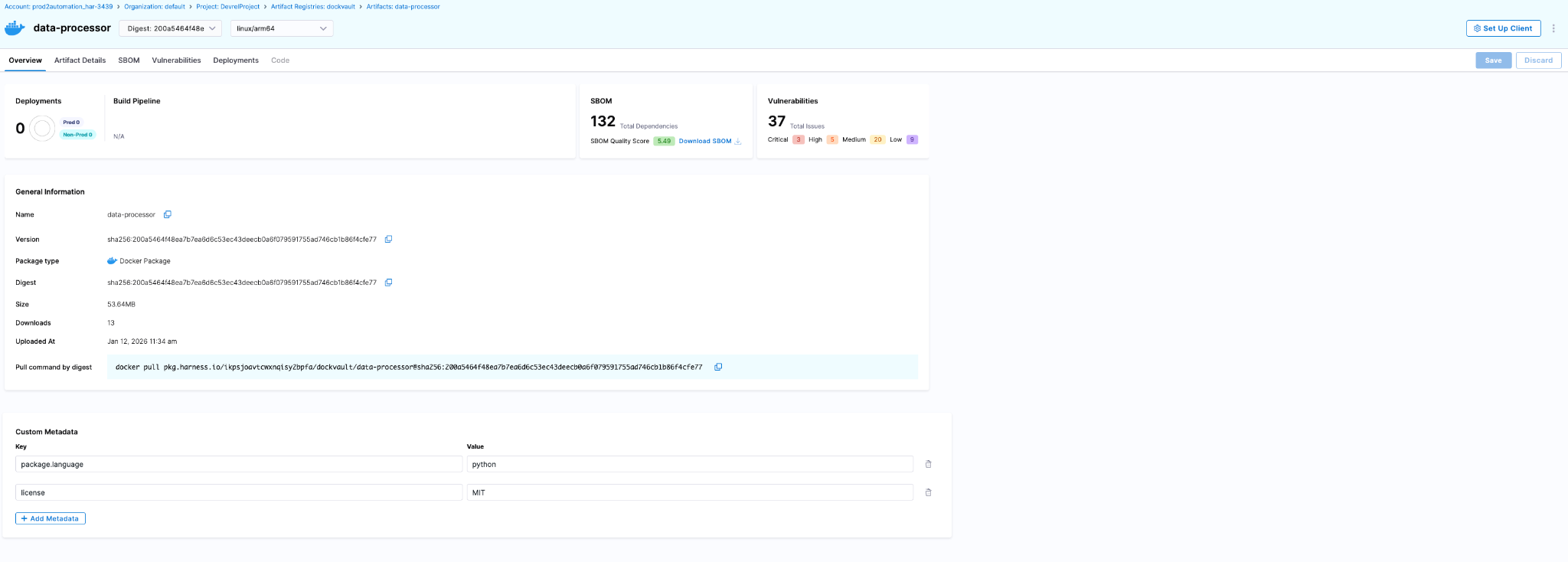
The Harness Software Delivery Knowledge Graph is a purpose-built model of everything that happens after code is written: builds, test runs, deployments, approvals, security scans, environment states, feature flags, infrastructure changes, cost signals, and rollbacks. Not as raw data but as a connected, typed, semantically annotated graph of entities and relationships.
Every field in the graph carries metadata that tells an agent exactly how to use it: whether a value is a number or a string, whether it can be aggregated or only filtered, what its unit is, and how it joins to related entities. Cross-module relationships, between a pipeline and the services it deploys, between a deployment and the security scan results for that artifact, between an environment change and the cost anomaly that followed, are explicitly declared, not inferred.
This is the difference between an agent that can access your delivery system and one that understands it.
When Claude connects to Harness via MCP, it doesn't receive a set of API endpoints. It's getting access to a structured model of your entire delivery organization, one where the relationships are known, the data types are enforced, and the agent can construct precise queries rather than guessing at field semantics.
The practical effect with Harness + Claude: that same cross-domain question above becomes 2–3 structured queries against a known schema. The agent selects the right entity types from the graph, generates queries with exact fields and declared relationships, and returns a deterministic answer. No guesswork. No hallucinated field names. No silent wrong answers.
What This Looks Like in Practice
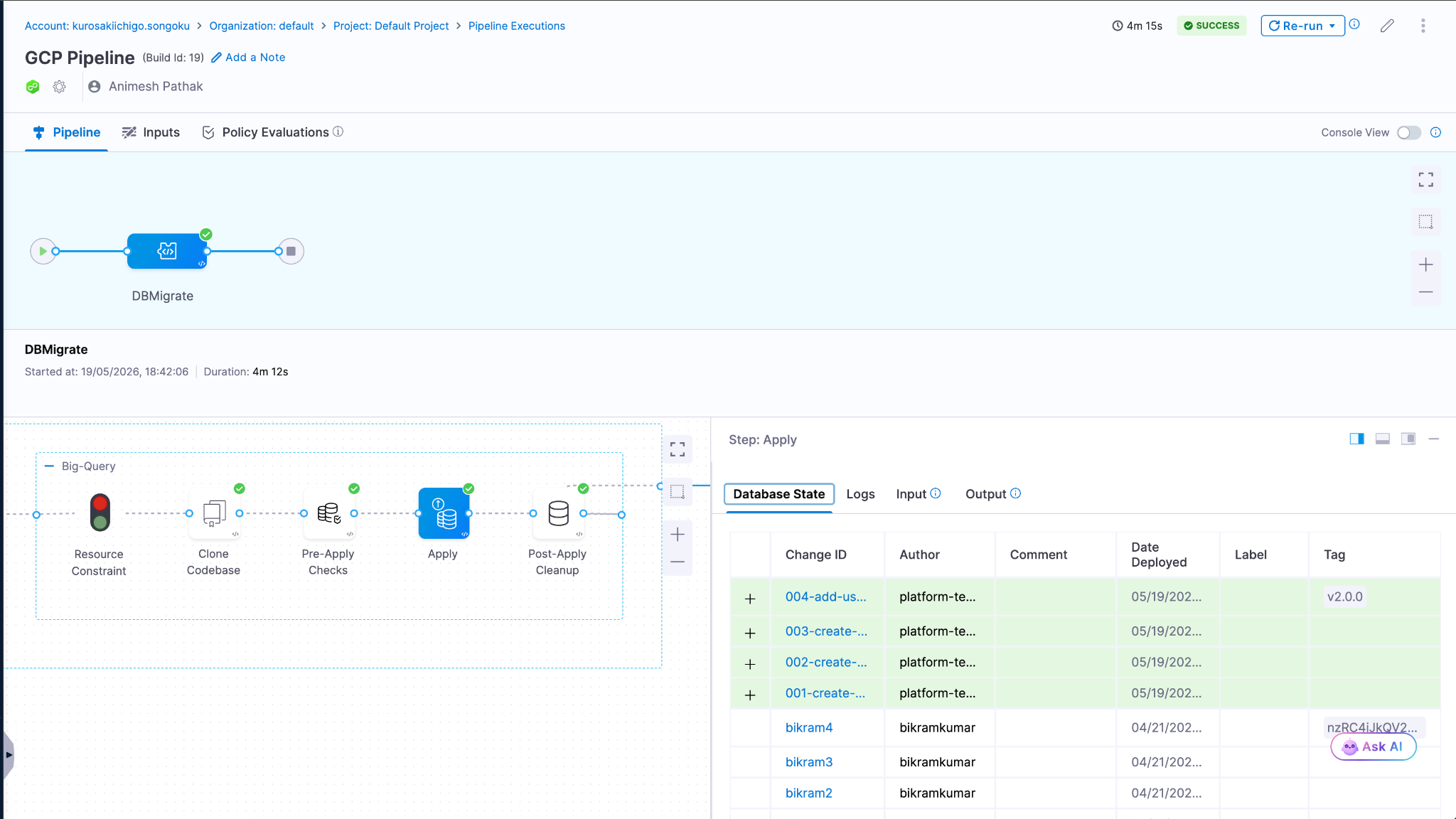
Debugging a failed pipeline without context switching
A build has failed. Normally, you'd open the Harness UI, navigate to the execution, copy the relevant logs, paste them into a conversation, and wait for analysis. The AI reasons over whatever you managed to capture.
With the Harness MCP connection active in Claude, you ask what failed. Claude doesn't just pull logs; it queries the Knowledge Graph to understand the structure of that pipeline, which stage failed, what services were involved, whether similar failures have occurred before, and what changed since the last successful run. The answer it surfaces reflects the full delivery context, not just the stack trace you happened to copy.
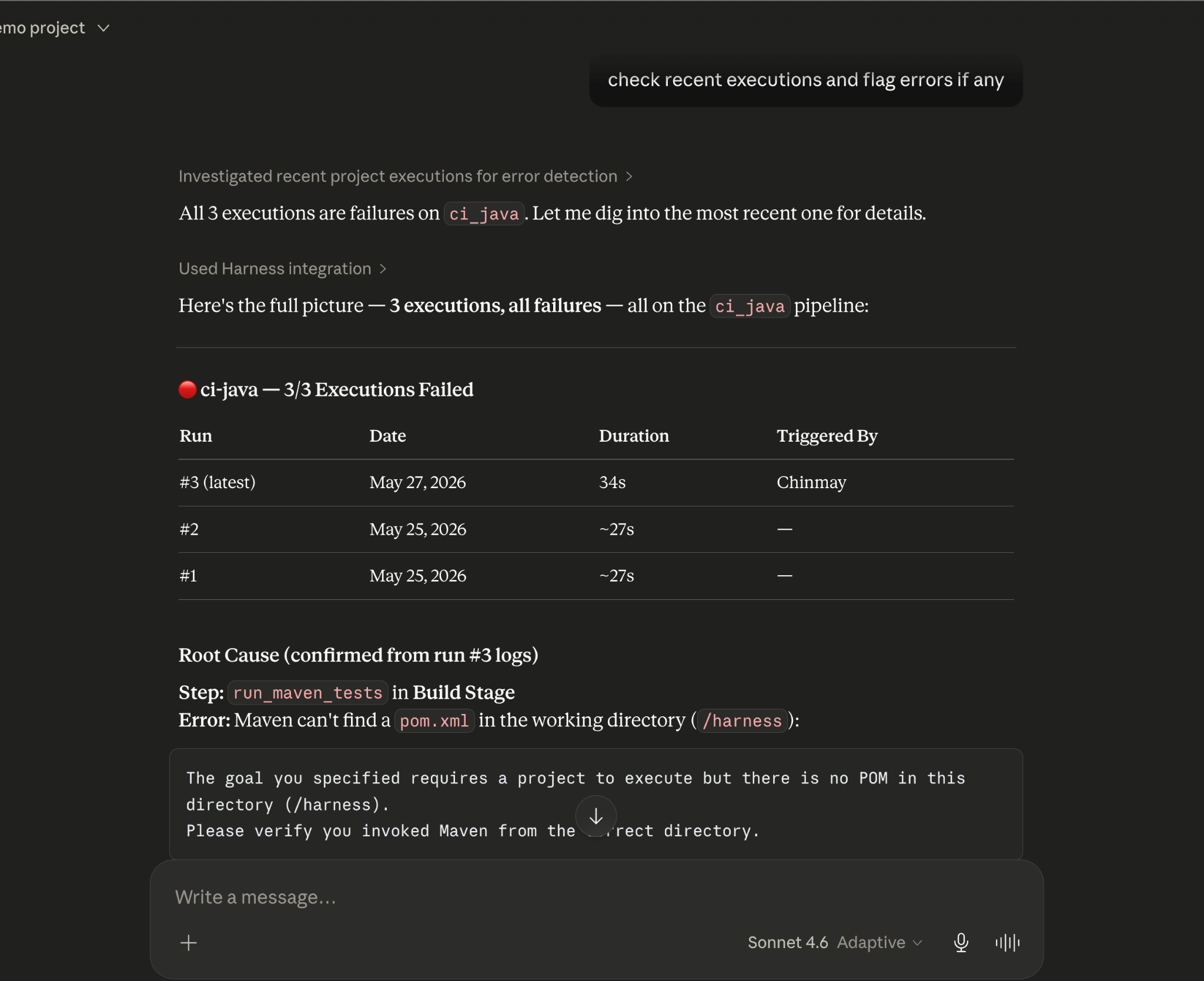
Promoting a deployment through governed gates
Your team is ready to move a service from staging to production. Claude checks the current environment state, verifies that required approval gates have been satisfied, confirms the security scan passed for the artifact version you're promoting, and initiates the deployment — with every action running through your existing RBAC policies and logged for audit.
The agent isn't guessing about whether conditions are met. It's querying a graph where those conditions are modeled as typed relationships with known states. The answer is deterministic because the data is structured to make it so.
This Is Not AI Without Guardrails
The natural question when Claude can trigger pipelines and manage deployments: what stops it from doing something it shouldn't?
The same controls that govern everything else in Harness. Every action taken through the MCP server runs through your existing RBAC permissions, OPA policy enforcement, approval gates, and audit logging. Claude operates with exactly the permissions you have, nothing more. Every action is tracked. Nothing bypasses the governance layer.
The Knowledge Graph reinforces this: because Harness AI understands your delivery system structurally, it also understands the constraints within it. Approval gates aren't just optional steps the agent might skip; they're modeled as typed relationships with state. The agent can't promote past a gate that hasn't cleared because the graph reflects that clearly.
Speed and governance aren't a tradeoff. They coexist by design.
Why the Claude Connectors Directory Matters
The Claude Connectors Directory is a curated, reviewed set of integrations. Anthropic evaluates each server before listing it. Being approved is a signal of trust that carries weight for enterprise teams deciding which AI integrations to enable.
It also means discoverability at scale: engineering teams using Claude for DevOps workflows will find Harness natively. One-click OAuth connection, no API key management, no manual configuration.
This fits a broader pattern. The Google Cloud partnership brought Harness into Google's AI ecosystem through Vertex AI and Gemini CLI. The Cursor plugin brought it into the IDE. The Claude Connectors Directory brings it into conversational AI. In each case, the goal is the same: wherever developers are doing their best thinking and wherever AI is being asked to help with software delivery, Harness should be present with the right context for that AI to act reliably.
Getting Started
If you're already a Harness customer:
- Open Claude and then the Connectors page
- Search for Harness in the MCP directory
- Authenticate with OAuth, no API keys, no manual configuration
- Start asking Claude about your pipelines, deployments, and delivery workflows
If you're new to Harness, sign up for free and connect from day one. Detailed steps are listed in the documentation.
The Harness Connector gives Claude the ability to act in your delivery system. The Knowledge Graph gives it the understanding to act well. Together, that's what reliable AI in software delivery actually looks like.

- Harness IaCM introduces native Terragrunt support, enabling true enterprise-grade orchestration at scale.
- Teams can now manage Terraform, OpenTofu, and Terragrunt in a single platform without fragmented tooling.
- Built-in governance, policy enforcement, and approvals streamline secure infrastructure operations.
- End-to-end visibility and drift detection improve reliability across complex, multi-environment deployments.
- The launch marks a major step toward a unified, multi-IaC control plane for modern infrastructure teams.
Bringing First-Class Terragrunt Support to IaCM
“We’ve been operating in a hybrid environment with both OpenTofu and Terragrunt, and Harness has made it much easier to bring those workflows together into a single, consistent platform with IaCM. The addition of Terragrunt support is a valuable step toward simplifying how we manage infrastructure at scale.”
— Lead Platform Engineer, Enterprise Customer
Infrastructure as Code is now a standard for modern cloud operations, with most enterprises using IaC to provision and manage environments. However, as adoption grows, so does complexity. Teams are no longer managing a handful of environments. They are operating across multiple regions, accounts, and services, often at massive scale.
This is where traditional approaches begin to fall short.
As organizations scale their infrastructure, Terraform alone is often not enough. Teams adopt Terragrunt to manage complex, multi-environment deployments, but they are often forced to stitch together fragmented tooling that lacks visibility, governance, and consistency.
At Harness, we are changing that.
Today, we are excited to announce native Terragrunt support in Harness IaCM, bringing it to full parity with Terraform and OpenTofu while delivering capabilities that go beyond what is available in standalone tooling. This is more than support. It is about making Terragrunt a first-class platform for enterprise infrastructure management.
With Harness IaCM, teams can now:
- Orchestrate complex Terragrunt environments with full visibility across all units
- Apply cost estimation, approvals, and policy enforcement natively
- Detect and manage drift across environments with granular insights
- View infrastructure changes at the resource level across orchestrated deployments
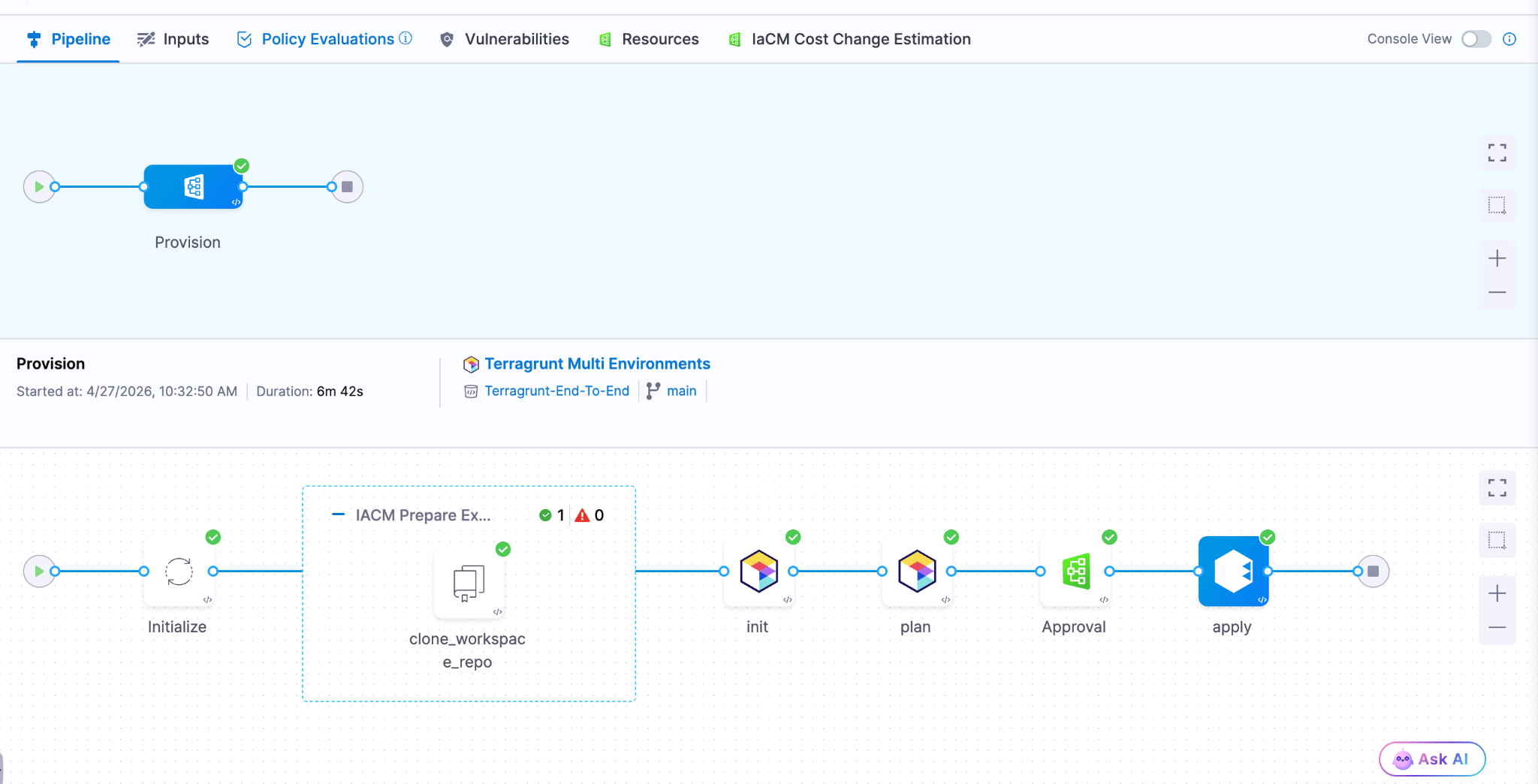
Terragrunt has become a critical layer for managing infrastructure at scale because it simplifies how teams structure and reuse configurations across environments. Harness builds on that foundation with deep, native integration, enabling platform teams to operate with both flexibility and control.
This is especially important for enterprises where a single deployment spans multiple environments and services. Harness abstracts that complexity while maintaining governance, auditability, and consistency.
Extending IaCM to a Multi-IaC Future
Terragrunt is part of a broader shift toward multi-tool infrastructure strategies.
Modern teams are no longer standardized on a single IaC tool. Instead, they operate across:
- Terraform and OpenTofu for provisioning
- Terragrunt for orchestration
- CDK for developer-driven infrastructure
- Ansible for configuration and automation

This creates challenges around consistency, visibility, and governance. Harness IaCM is built for this reality. We are evolving IaCM into a unified control plane for multi-IaC workflows, where teams can manage different frameworks with a consistent experience, shared policies, and centralized visibility.
This means:
- Eliminating fragmented pipelines across tools
- Standardizing governance across environments
- Gaining full visibility into infrastructure state and changes
Instead of managing infrastructure in silos, teams can now operate from a single platform across the entire lifecycle.
What’s Next for Infrastructure as Code?
The next phase of Infrastructure as Code is not just about supporting more tools. It is about making infrastructure systems more intelligent and automated.
We are investing in two key areas:
Expanded IaC Support
We are continuing to support modern frameworks like AWS CDK, enabling developer-centric infrastructure workflows alongside provisioning, configuration, and orchestration tools.
AI-Driven Automation
We are introducing intelligence into IaC workflows to simplify tasks such as drift management and optimization. This helps teams reduce manual effort and operate more efficiently at scale.
Together, these investments move IaCM toward a unified, multi-IaC platform that combines flexibility, governance, and automation. Terragrunt has become essential for managing infrastructure at scale but until now, it hasn’t had a platform that truly supports it. As infrastructure continues to grow in complexity, our focus remains the same. Helping teams move faster, reduce risk, and scale with confidence no matter which IaC tools they use.
.png)
We’ve come a long way in how we build and deliver software. Continuous Integration (CI) is automated, Continuous Delivery (CD) is fast, and teams can ship code quickly and often. But environments are still messy.
Shared staging systems break when too many teams deploy at once, while developers wait on infrastructure changes. Test environments get created and forgotten, but over time, what is running in the cloud stops matching what was written in code.
We have made deployments smooth and reliable, but managing environments still feels manual and unpredictable. That gap has quietly become one of the biggest slowdowns in modern software delivery.
This is the hidden bottleneck in platform engineering, and it's a challenge enterprise teams are actively working to solve.
As Steve Day, Enterprise Technology Executive at National Australia Bank, shared:
“As we’ve scaled our engineering focus, removing friction has been critical to delivering better outcomes for our customers and colleagues. Partnering with Harness has helped us give teams self-service access to environments directly within their workflow, so they can move faster and innovate safely, while still meeting the security and governance expectations of a regulated bank.”
At Harness, Environment Management is a first-class capability inside our Internal Developer Portal. It transforms environments from manual, ticket-driven assets into governed, automated systems that are fully integrated with Harness Continuous Delivery and Infrastructure as Code Management (IaCM).
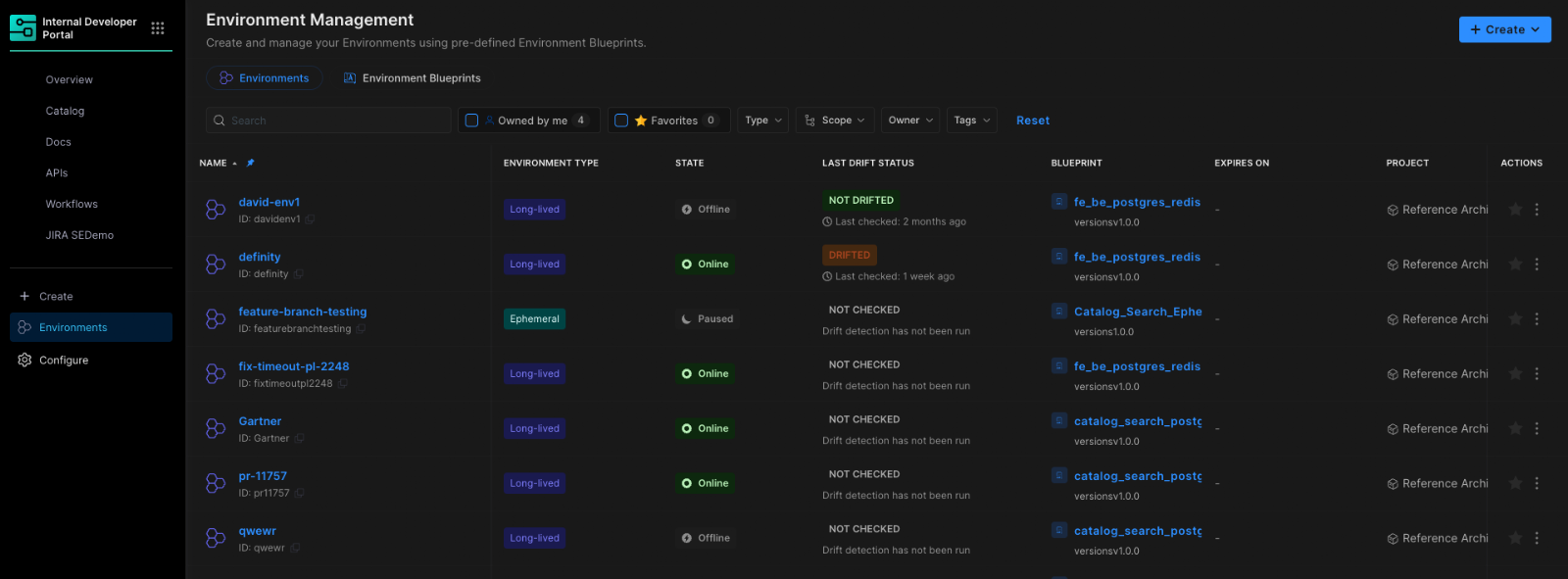
This is not another self-service workflow. It is environment lifecycle management built directly into the delivery platform.
The result is faster delivery, stronger governance, and lower operational overhead without forcing teams to choose between speed and control.
Closing the Gap Between CD and IaC
Continuous Delivery answers how code gets deployed. Infrastructure as Code defines what infrastructure should look like. But the lifecycle of environments has often lived between the two.
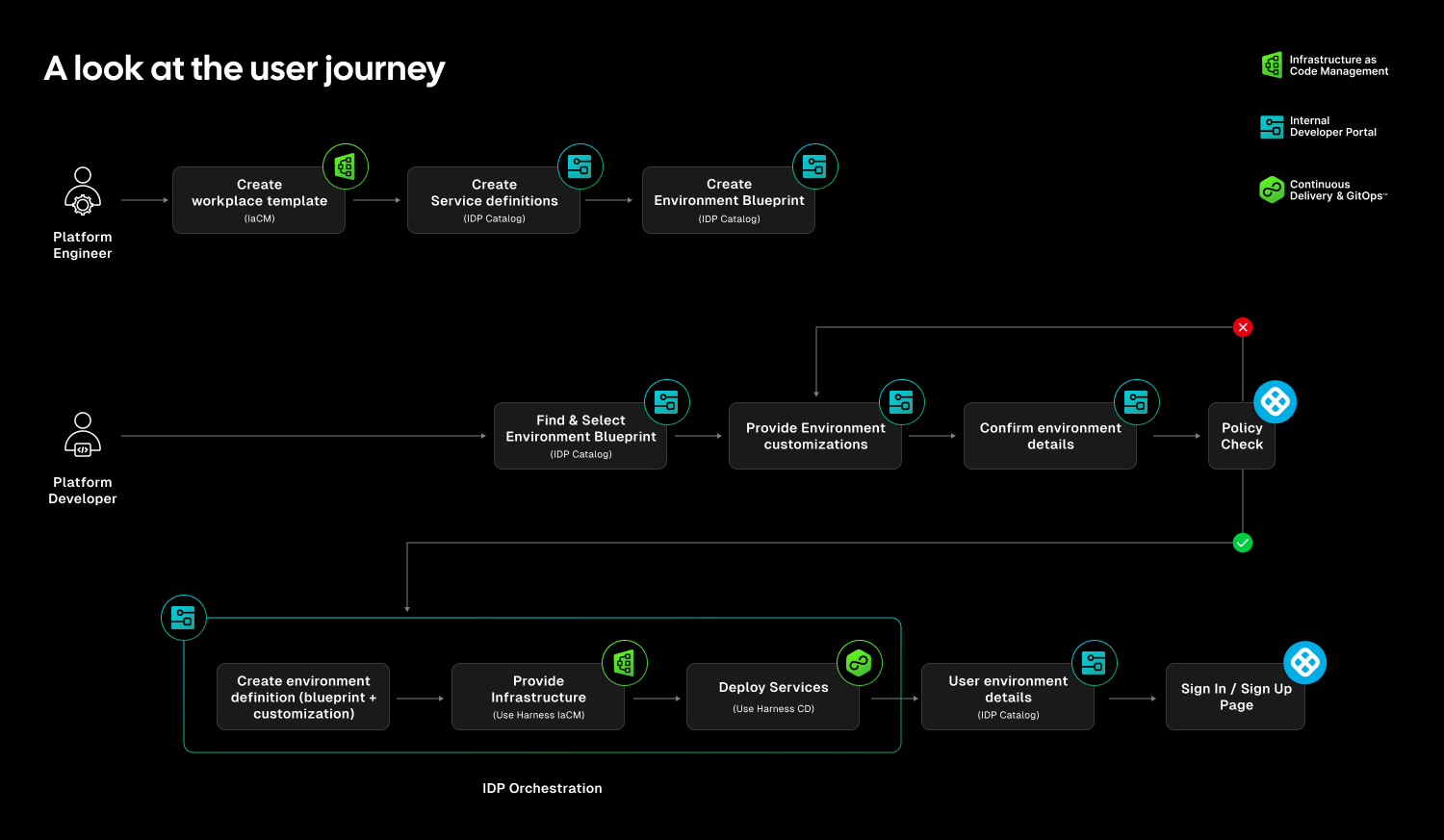
Teams stitch together Terraform projects, custom scripts, ticket queues, and informal processes just to create and update environments. Day two operations such as resizing infrastructure, adding services, or modifying dependencies require manual coordination. Ephemeral environments multiply without cleanup. Drift accumulates unnoticed.
The outcome is familiar: slower innovation, rising cloud spend, and increased operational risk.
Environment Management closes this gap by making environments real entities within the Harness platform. Provisioning, deployment, governance, and visibility now operate within a single control plane.
Harness is the only platform that unifies environment lifecycle management, infrastructure provisioning, and application delivery under one governed system.
Blueprint-Driven by Design
At the center of Environment Management are Environment Blueprints.
Platform teams define reusable, standardized templates that describe exactly what an environment contains. A blueprint includes infrastructure resources, application services, dependencies, and configurable inputs such as versions or replica counts. Role-based access control and versioning are embedded directly into the definition.
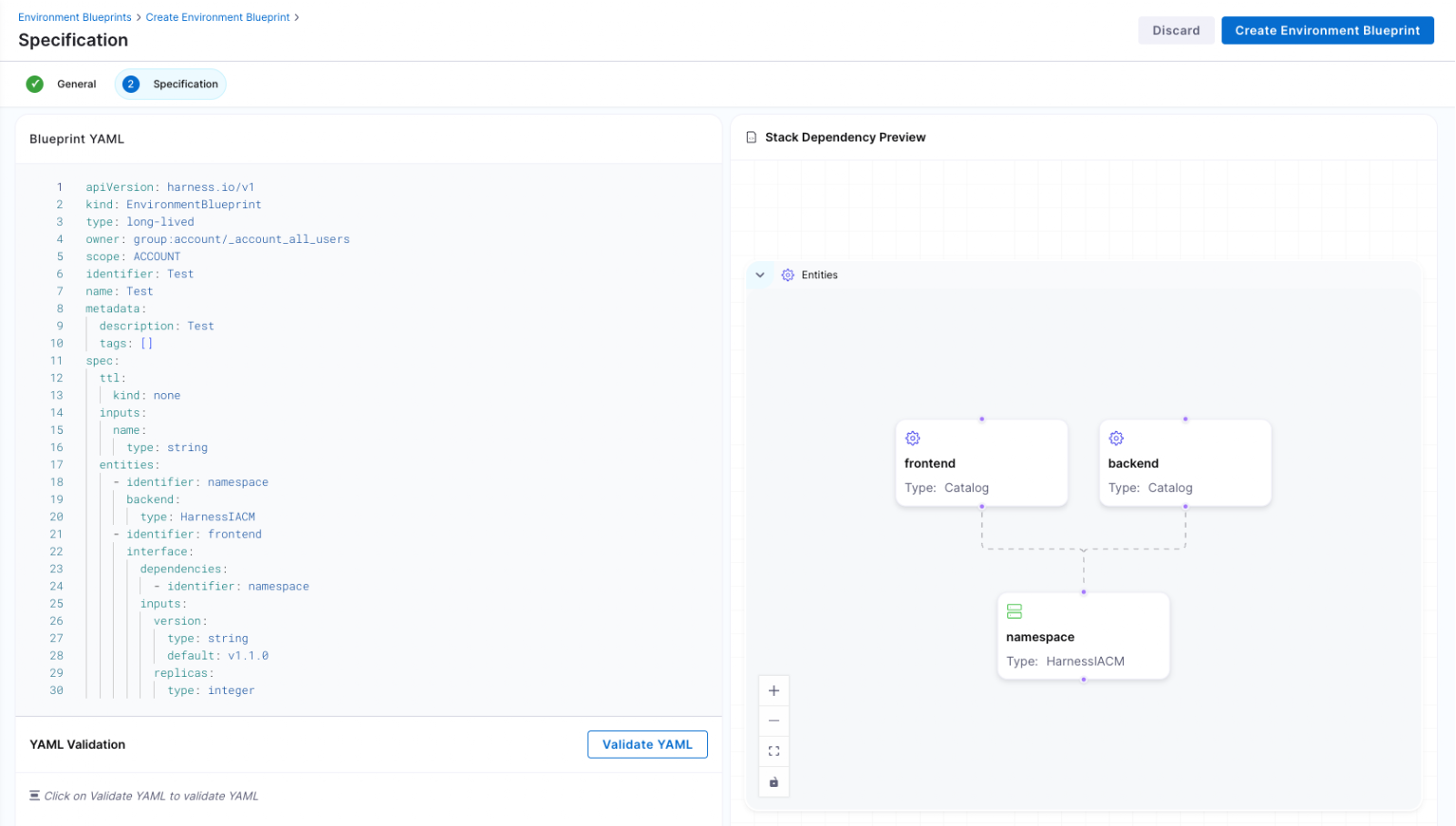
Developers consume these blueprints from the Internal Developer Portal and create production-like environments in minutes. No tickets. No manual stitching between infrastructure and pipelines. No bypassing governance to move faster.
Consistency becomes the default. Governance is built in from the start.
Full Lifecycle Control
Environment Management handles more than initial provisioning.
Infrastructure is provisioned through Harness IaCM. Services are deployed through Harness CD. Updates, modifications, and teardown actions are versioned, auditable, and governed within the same system.
Teams can define time-to-live policies for ephemeral environments so they are automatically destroyed when no longer needed. This reduces environment sprawl and controls cloud costs without slowing experimentation.
Harness EM also introduces drift detection. As environments evolve, unintended changes can occur outside declared infrastructure definitions. Drift detection provides visibility into differences between the blueprint and the running environment, allowing teams to detect issues early and respond appropriately. In regulated industries, this visibility is essential for auditability and compliance.
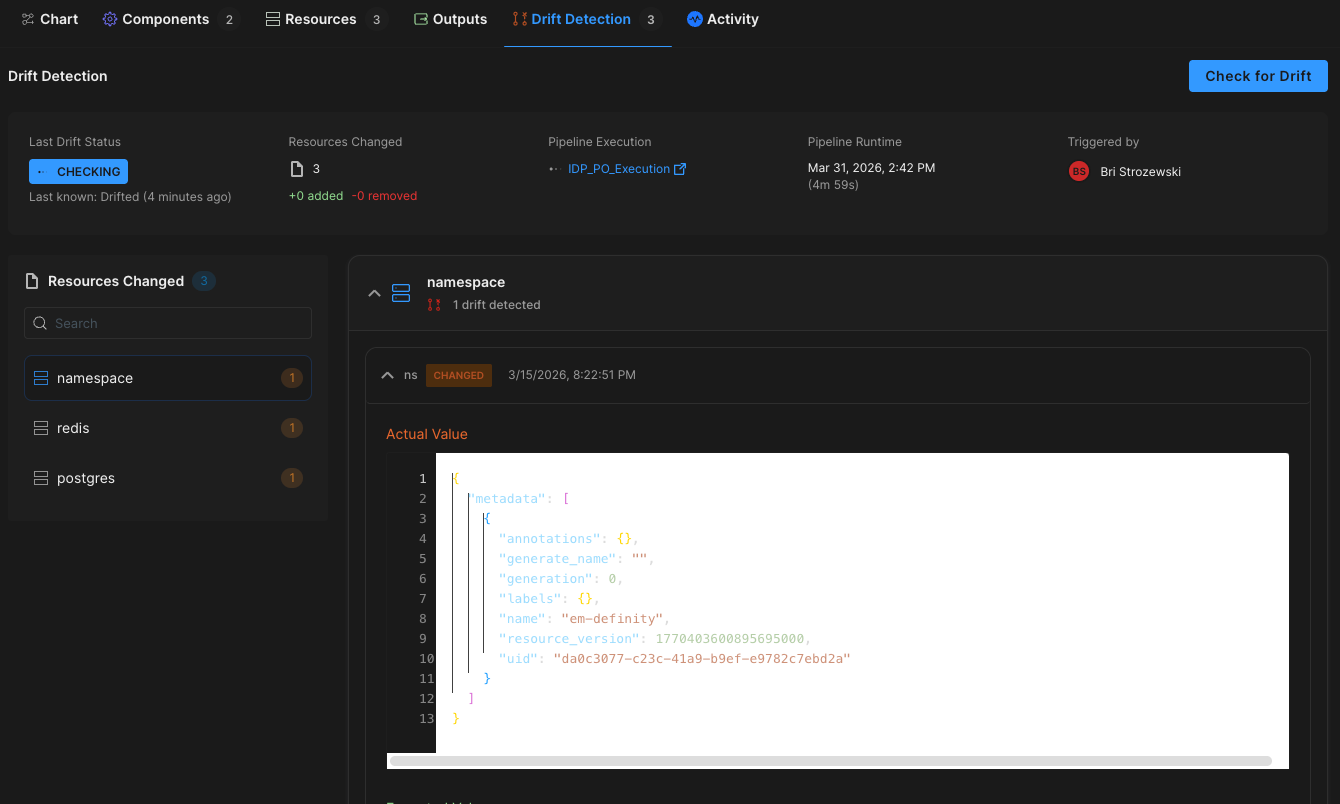
Governance Built In
For enterprises operating at scale, self-service without control is not viable.
Environment Management leverages Harness’s existing project and organization hierarchy, role-based access control, and policy framework. Platform teams can control who creates environments, which blueprints are available to which teams, and what approvals are required for changes. Every lifecycle action is captured in an audit trail.
This balance between autonomy and oversight is critical. Environment Management delivers that balance. Developers gain speed and independence, while enterprises maintain the governance they require.
"Our goal is to make environment creation a simple, single action for developers so they don't have to worry about underlying parameters or pipelines. By moving away from spinning up individual services and using standardized blueprints to orchestrate complete, production-like environments, we remove significant manual effort while ensuring teams only have control over the environments they own."
— Dinesh Lakkaraju, Senior Principal Software Engineer, Boomi
From Portal to Platform
Environment Management represents a shift in how internal developer platforms are built.
Instead of focusing solely on discoverability or one-off self-service actions, it brings lifecycle control, cost governance, and compliance directly into the developer workflow.
Developers can create environments confidently. Platform engineers can encode standards once and reuse them everywhere. Engineering leaders gain visibility into cost, drift, and deployment velocity across the organization.
Environment sprawl and ticket-driven provisioning do not have to be the norm. With Environment Management, environments become governed systems, not manual processes. And with CD, IaCM, and IDP working together, Harness is turning environment control into a core platform capability instead of an afterthought.
This is what real environment management should look like.