
Harness's YAML Editor enhances developer efficiency by providing real-time schema validation, intellisense, and auto-completion for CI/CD pipelines, reducing setup and maintenance time significantly.
With the advent of modern DevOps, configuring Continuous Integration/Continuous Deployment (CI/CD) pipelines as code has become quite popular. Most notably, Kubernetes has played a pivotal role in the widespread adoption of YAML as the preferred language while defining Kubernetes objects as code. This, in conjunction with Kubernetes being one of the first and most important swimlanes in Harness CI/CD products, meant that it was important for us to provide a powerful YAML Editor experience to the end developer to write/edit a CI/CD pipeline in an efficient, error-free, and developer-friendly manner.
But what were we really up against? We wanted to create a great editing experience for a developer that would be capable of:
- Creating a connector, secret, or pipeline from scratch.
- Providing real-time schema validation.
- Providing intellisense and auto-completion.
- Providing field descriptions and rich inline documentation.
- Lastly, providing templates or sample YAML as a quick-start point.
This would solve the following customer use cases:
- A developer must create a YAML from scratch and requires assistance with which fields should go in it.
- A developer must modify an existing pipeline and validate its correctness.
- And, a developer must clone and edit an existing pipeline and quickly copy the current pipeline as code.
Behind the Scenes
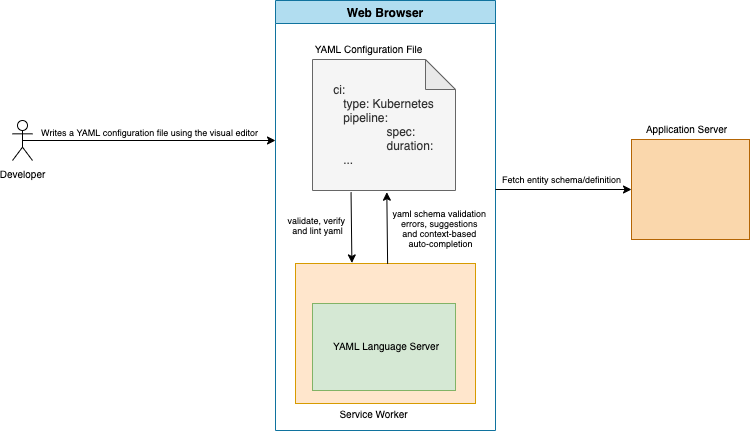
Creating a CI/CD pipeline from scratch with a build/deployment stage could be overwhelming without any auto-suggestion and auto-completion support for the developer. Furthermore, it’s not about creating any pipeline – it must be one that validates semantically to the “JSON Schema” of the CI/CD pipeline itself. JSON Schema is a grammar language for defining the structure, content, and (to some extent) semantics of a JSON object or a YAML file. This is more relevant to our use case.
As part of building our schema framework, we’ve also pioneered stitching a complex YAML schema from different microservices. For example, the combined YAML schema for a Harness CI/CD pipeline would have a CI and CD stage where individual schema for these stages could be contributed by the respective CI and CD microservices.
These complex schemas would facilitate YAML auto-completion to some really deeply-nested levels in the YAML. For example, for a typical multistage CI/CD pipeline, we’ve achieved YAML auto-completion to approximately 50 nested levels. The application server stitches this JSON schema for an entity based on it’s Swagger definition, our custom annotations, and a Swagger-to-JSON schema translator.
Semantically speaking, while defining the JSON schema for an entity, such as a pipeline, we’ve introduced a notion of a “type” and its corresponding “spec” field. For example, a CI/CD pipeline may have a stage of type, being either “build,” “deploy,” or “approval.” Corresponding to the type chosen by the developer, a spec object must be specified that would have information about the stage itself. For example, what codebase to clone, which rollout strategy to use, which resources to allocate, etc. This design principle has helped us generically model schema for all of our entities, such as connectors, secrets, and more.
What Is the User Experience Like?
When a developer writes/edits a YAML file for a specific entity, such as a pipeline, it’s validated semantically against its JSON schema. This returns all of the semantic validation errors in the YAML that should be fixed by the developer to obtain a valid and correct YAML configuration. For example, a pipeline should at least have an identifier, name, orgIdentifier, and projectIdentifier (see the following screenshot).

Furthermore, we show schema validation errors inline to highlight the exact validation issue (see the following screenshot) and the expected developer action to fix it (see the subsequent screenshot).


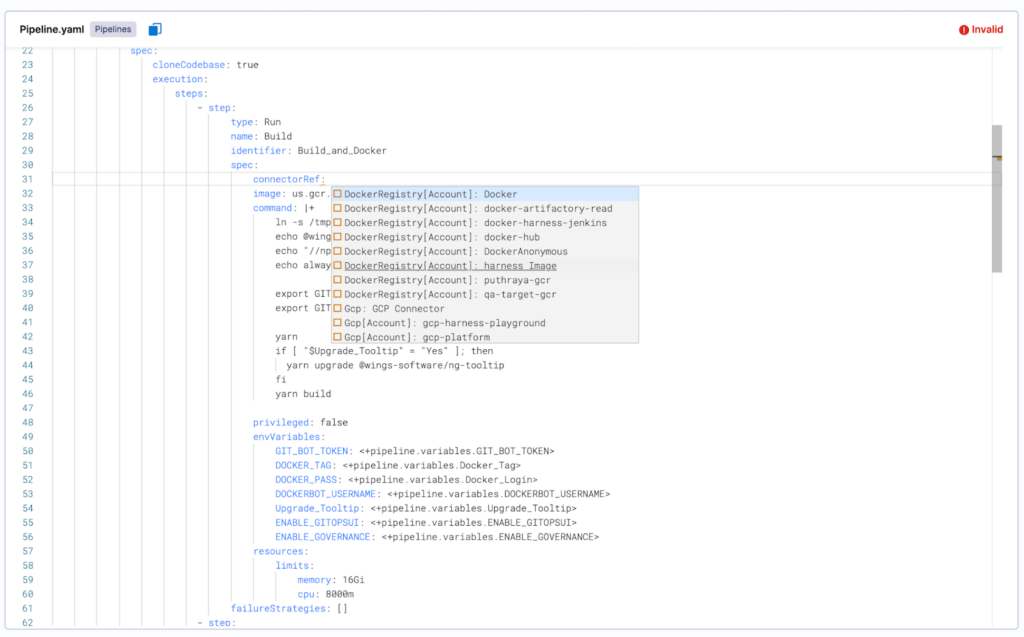
Apart from providing intelligent auto-suggestions against a JSON schema for an entity, Harness’ YAML editor can inject custom suggestions for a particular field in the YAML. For example, if a CI/CD pipeline must reference an existing connector or a secret in a build/deploy stage, we can enlist every connector or secrets reference (the “refs”) in a dropdown list against “connectorRef” or “secretRef” field in the YAML (see the following screenshot). This is a powerful developer experience, since the developer doesn’t have to navigate to another screen to find out the connector or secrets references to specify in the pipeline.
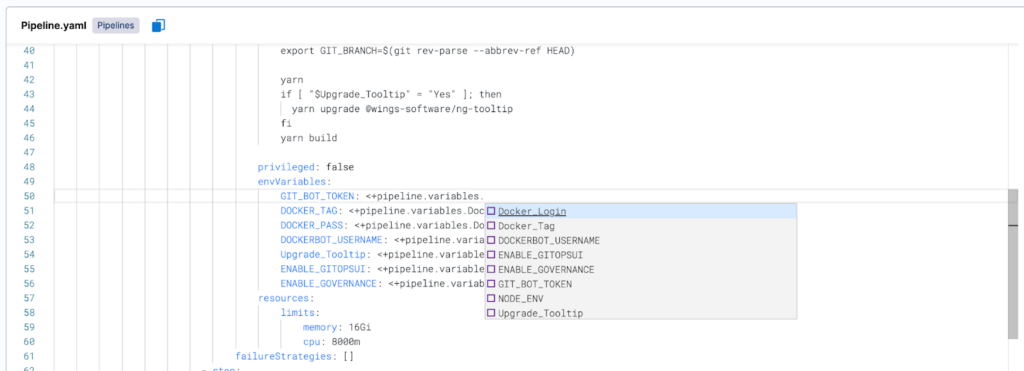
Similarly, the editor can also prompt every pipeline variable as a dropdown list for a field (see the following screenshot). This developer-focused feature allows for the seamless referencing of pipeline variables in the pipeline.

Lastly, the editor also allows for the capability of auto-completing partial pipeline variables as inputs. For example, we show the developer only the pipeline variables beginning with “pipeline.variables” in the dropdown list when the auto-completion is triggered for developer input “<+pipeline.variables” (see the following screenshot).
Going the Extra Mile
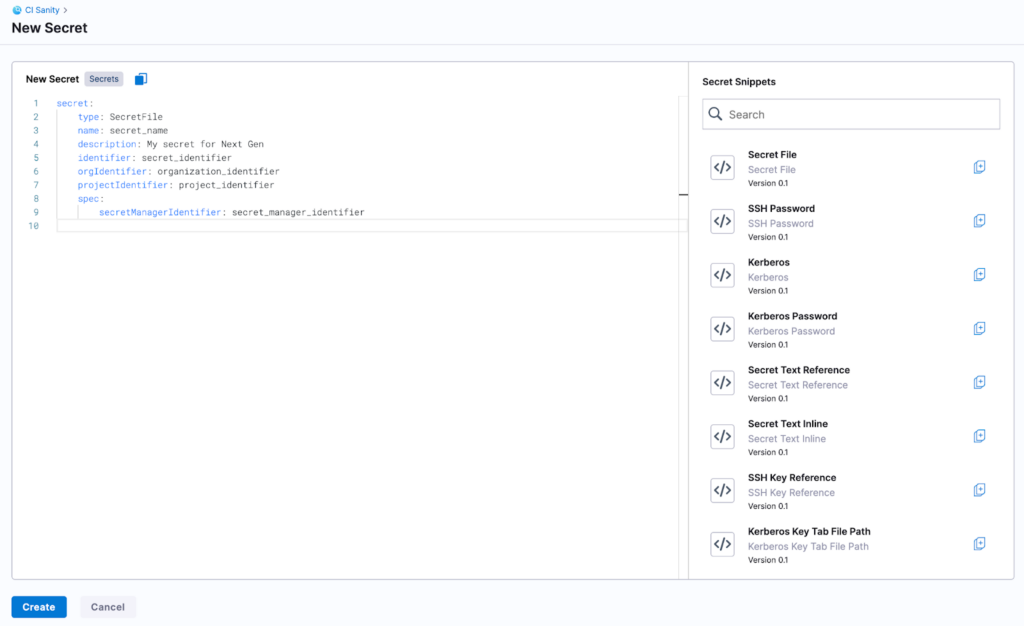
Even after having provided a powerful editor experience with intellisense and auto-completion, we still felt that writing a full-blown YAML from scratch could be a bit overwhelming for someone who may not be familiar with YAML language - or a pipeline as a concept in general. To tackle this, we came up with a Snippets section that provides ready-to-go YAMLs that can be copy/pasted right away in the editor pane, and edited as needed to quickly create a connector, secret, or pipeline (see the following screenshot).
As of today, this feature is still in active development for most Harness entities. However, it does pave the way for a great marketplace experience to help the developer get started with a pipeline or connector creation as a YAML in just a few clicks.
Summary
Harness’ YAML Editor promises a lot of potential to modern DevOps solutions, providing a best-in-class user experience and helping developers reduce the overall time to set up and maintain CI/CD pipelines.
Want to learn more about CI and CD? We released Templates for CI a couple weeks back - that's designed to save you a ton of time. On the CD end, here's a cool tech deep dive on Event-Driven Architecture Using Redis Streams.
This article was written in collaboration with Abhinav Singh, Rama Tummala, and Vardan Bansal.

All this author’s posts
Vardan Bansal is a Senior Staff Software Engineer at Harness, where he leads frontend engineering for the company's CI platform and AI-powered developer tools