Featured Blogs

At Harness, our story has always been about change — helping teams ship faster, deploy safer, and control the blast radius of every modification to production. Deployments, feature flags, pipelines, and governance are all expressions of how organizations evolve their software.
Today, the pace of change is accelerating. As AI-assisted development becomes the norm, more code reaches production faster, often without a clear link to the engineer who wrote it. Now, Day 2 isn’t just supporting the unknown – it’s supporting software shaped by changes that may not have a clear human owner.
And as every SRE and on-call engineer knows, even rigorous change hygiene doesn’t prevent incidents because real-world systems don’t fail neatly. They fail under load, at the edges, in the unpredictable ways software meets traffic patterns, caches, databases, user behavior, and everything in between.
When that happens, teams fall back on what they’ve always relied on: Human conversation and deep understanding of what changed.
That’s why today we’re excited to introduce the Harness Human-Aware Change Agent — the first AI system designed to treat human insight as operational data and use it to drive automated, change-centric investigation during incidents.
Not transcription plus RCA. One unified intelligence engine grounded in how incidents actually unfold.
📞 A Quick Look at Harness AI SRE
The Human-Aware Change Agent is part of Harness AI SRE — a unified incident response system built to help teams resolve incidents faster without scaling headcount. AI SRE brings together the critical parts of response: capturing context, coordinating action, and operationalizing investigation.
At the center is the AI Scribe, because the earliest and most important clues in an incident often surface in conversation before they appear in dashboards. Scribe listens across an organization’s tools with awareness of the incident itself – filtering out unrelated chatter and capturing only the decisions, actions, and timestamps that matter. The challenge isn’t producing a transcript; it’s isolating the human signals responders actually use.
Those signals feed directly into the Human-Aware Change Agent, which drives change-centric investigation during incidents.
And once that context exists, AI SRE helps teams act on it: Automation Runbooks standardize first response and remediation, while On-Call and Escalations ensure incidents reach the right owner immediately.
AI SRE also fits into the tools teams already run — with native integrations and flexible webhooks that connect observability, alerting, ticketing, and chat across systems like Datadog, PagerDuty, Jira, ServiceNow, Slack, and Teams.
🌐 Why We Built a Human-Aware Change Agent
Most AI approaches to SRE assume incidents can be solved entirely through machine signals — logs, metrics, traces, dashboards, anomaly detectors. But if you’ve ever been on an incident bridge, you know that’s not how reality works.
Some of the most important clues come from humans:
- “The customer said the checkout button froze right after they updated their cart.”
- “Service X felt slow an hour before this started.”
- “Didn’t we flip a flag for the recommender earlier today?”
- “This only happens in the US-East cluster.”
These early observations shape the investigation long before anyone pulls up a dashboard.
Yet most AI tools never hear any of that.
The Harness Human-Aware Change Agent changes this. It listens to the same conversations your engineers are having — in Slack, Teams, Zoom bridges — and transforms the human story of the incident into actionable intelligence that guides automated change investigation.
It is the first AI system that understands both what your team is saying and what your systems have changed — and connects them in real time.
🔍 How the Human-Aware Change Agent Works
1. It listens and understands human context.
Using AI Scribe as its conversational interface, the agent captures operational signals from a team’s natural dialogue – impacted services, dependencies, customer-reported symptoms, emerging theories or contradictions, and key sequence-of-events clues (“right before…”).
The value is in recognizing human-discovered clues, and converting them into signals that guide next steps.
2. It investigates changes based on those clues.
The agent then uses these human signals to direct investigation across your full change graph including deployments, feature flags or config changes, infrastructure updates, and ITSM change records – triangulating what engineers are seeing with what is actually changing in your production environment.
3. It surfaces evidence-backed hypotheses.
Instead of throwing guesses at the team, it produces clear, explainable insights:
“A deployment to checkout-service completed 12 minutes before the incident began. That deploy introduced a new retry configuration for the payment adapter. Immediately afterward, request latency started climbing and downstream timeouts increased.”
Each hypothesis comes with supporting data and reasoning, allowing teams to quickly validate or discard theories.
4. It helps teams act faster and safer
By uniting human observations with machine-driven change intelligence, the agent dramatically shortens the path from:
What are we seeing? → What changed? → What should we do?
Teams quickly gain clarity on where to focus, what’s most suspicious, and which rollback or mitigation actions exist and are safest.
🌅 A New Era of Incident Response
With this release, Harness is redefining what AI for incident management looks like.
Not a detached assistant. Not a dashboard summarizer. But a teammate that understands what responders are saying, investigates what systems have changed, connects the dots, and helps teams get to truth faster.
Because the future of incident response isn’t AI working alone. It’s AI working alongside engineers — understanding humans and systems in equal measure.
Book a demo of Harness AI SRE to see how human insight and change intelligence come together during real incidents.
Latest Blogs
_%20A%20Step-by-Step%20Guide.png)
Site Reliability Engineering (SRE) 101: Everything You Need to Know
- SRE codifies reliability through SLIs, SLOs, and error budgets, balancing deployment speed with system stability through measurable targets.
- AI-powered CD and GitOps platforms automate verification, rollbacks, and policy enforcement, reducing toil while accelerating incident recovery.
- Start with SLOs for one critical service, add intelligent rollbacks, then scale with policy-as-code guardrails for safe, rapid delivery.
A single second of latency can cost e-commerce sites millions in revenue, while just minutes of downtime trigger customer churn that takes months to recover. Modern users expect instant responses and seamless experiences, making reliability a competitive feature that directly impacts business outcomes.
Site Reliability Engineering treats operations as a software problem rather than a manual discipline. SRE applies engineering principles to achieve measurable reliability through automation.
Ready to implement SRE practices with AI-powered deployment automation? Explore how Harness Continuous Delivery provides intelligent verification and automated rollbacks that transform reliability from theory into practice.
What Is Site Reliability Engineering (SRE)?
Site Reliability Engineering (SRE) was born at Google to scale services for billions of users, providing concrete frameworks for balancing speed with stability.
SRE: Engineering Discipline That Codifies Operations
Instead of relying on manual processes and undocumented institutional knowledge, SRE codifies operational work through automation, monitoring, and measurable reliability targets. SRE teams write code to manage infrastructure, automate incident response, and build systems that automatically recover when possible.
The Language of Reliability: SLIs, SLOs, and Error Budgets
The engineering approach of SRE relies on three fundamental concepts that quantify reliability.
- Service Level Indicators (SLIs) measure what users actually experience, such as page load times or checkout success rates.
- Service Level Objectives (SLOs) set specific targets for these metrics, such as "99.9% of requests complete within 200ms."
- Error budgets represent the acceptable failure rate that remains after meeting your SLO.
When you burn through your error budget too quickly, it signals time to slow down deployments and focus on reliability improvements rather than new features.
Why SRE Matters for Microservices and High-Frequency Releases
Microservices architectures create cascading failure scenarios that traditional operations can't handle at scale. SRE addresses these challenges through:
- Progressive delivery strategies, like canary releases, detect 87% of service-impacting issues before full rollout, limiting the impact of failures.
- Automated rollbacks reduce recovery time from an average of 57 minutes with manual processes to just 3.7 minutes, preventing widespread outages.
- AI-driven verification shortens mean time to detection by 47% and resolution by up to 63% by automatically correlating metrics, logs, and traces under real traffic conditions.
- Error budgets provide the framework teams need to balance speed with safety, enabling daily or hourly deployments while maintaining service availability targets.
The Origins of SRE
SRE began at Google around 2003 when Ben Treynor Sloss, a software engineer, was asked to run a production team. Instead of hiring more system administrators, he approached operations as an engineering problem. As Sloss famously put it, "SRE is what happens when you ask a software engineer to design an operations team."
Google enforced a strict operational work limit for SREs, ensuring time for automation projects. These principles spread industry-wide through foundational SRE texts, starting with the 2016 publication of "Site Reliability Engineering: How Google Runs Production Systems." Today, SRE principles integrate seamlessly with cloud-native and GitOps patterns, enhancing tools like Argo CD with reliability guardrails rather than replacing existing investments.
Core SRE Principles
High-performing teams don't choose between speed and safety. They achieve both through disciplined engineering practices. The core principles of SRE make this balance measurable, repeatable, and scalable.
Reliability Through Measurable Targets
How do you know when you're reliable enough? When is it safe to deploy versus when you should pause? Error budget policies answer these questions with concrete thresholds that trigger escalating responses:
- At 64% budget consumption within a four-week rolling window, tighten approval processes and require additional review for risky changes
- At 100% budget exhaustion, halt all non-critical deployments until the service recovers within its SLO targets
- Monthly budget resets with full audit trails showing which services consumed the budget and why
- Policy as Code enforcement ensures consistent application across all services without subjective exceptions
- Automated remediation triggers canary rollbacks or traffic shifts when budget burn correlates to specific microservices
This approach transforms error budgets from reactive limits into proactive reliability controls.
Automation-First Mindset
Eliminating toil is fundamental to SRE success. This means reducing manual, repetitive work that scales linearly with service growth. Google limits SRE teams to 50% operational work, forcing automation investments.
Here's how to reduce toil systematically:
- Measure toil percentage of each SRE's time monthly, targeting under 50% initially and driving toward 20%.
- Automate deployment verification with AI-powered health checks that connect to your observability tools.
- Implement automated rollback triggers when anomalies are detected, eliminating manual intervention during incidents.
- Create golden path templates with continuous delivery platforms that let developers self-serve without writing custom scripts.
- Track and celebrate toil elimination wins. Treat deleted work as engineering victories.
The goal isn't zero toil. It's ensuring valuable engineering work always outweighs the mundane.
Controlled Risk and Safety Nets
SRE embraces controlled risk through progressive delivery strategies like canary deployments and blue-green releases. These approaches expose changes to small user populations first, detecting issues before full rollout. Automated rollbacks serve as primary safety nets. When anomalies are detected, systems revert to known-good states without human intervention. This combination of gradual exposure and rapid recovery enables higher deployment frequency while maintaining reliability targets.
Key SRE Practices
Essential practices in Site Reliability Engineering address the core challenges every SRE faces: reducing deployment anxiety, accelerating incident recovery, and preventing issues before they impact users.
Incident Management: From Chaos to Learning
Effective incident response follows the three Cs: coordinate, communicate, and control.
Here's how to implement structured incident management:
- Assign clear roles during incidents (incident commander, communications lead, operations lead) to reduce response time and prevent confusion.
- Align response time expectations with service criticality: 5 minutes for user-facing systems and 30 minutes for less critical services.
- Pre-write runbooks and escalation paths to eliminate decision latency during production outages.
- Enrich alerts with context by using systems that automatically correlate alerts with recent deployments, service ownership, and probable root causes, reducing MTTR by up to 85%.
- Conduct blameless postmortems immediately after incidents, documenting impact, root causes, and follow-up actions without individual blame.
- Capture specific contributing factors, detection gaps, and assign action items with owners and deadlines. Treat each incident as valuable learning that prevents future occurrences.
When postmortems become a cultural practice, organizations see faster recovery times with measurable improvements.
Progressive Delivery and Automated Rollbacks
Progressive delivery transforms risky big-bang releases into controlled, measurable rollouts. Modern canary deployments shift traffic incrementally while automated systems verify each step and trigger instant rollbacks when needed.
Here's how modern progressive delivery works in practice:
- Start small and grow gradually: Deploy to 10% traffic, then 25%, then 50%, and finally 100% while checking SLIs at each gate.
- Enable AI to select your metrics: Automated verification connects to Datadog, New Relic, Dynatrace, and Prometheus without writing complex analysis templates.
- Trigger instant rollbacks: Anomaly detection identifies issues within seconds and reverts automatically.
- Verify under real traffic: Production validation catches problems that staging environments miss.
- Reduce blast radius: Progressive traffic shifting limits the impact of failures to small user populations.
Observability: The Foundation of Reliable Systems
Focus monitoring on the four golden signals: latency, traffic, errors, and saturation. This approach detects regressions under real traffic conditions by integrating metrics from application performance monitoring, logs from centralized aggregation, and traces from distributed systems. Focus alerts on user-impacting symptoms rather than internal system states. This unified observability approach enables teams to validate changes against actual user experience and catch issues before customers notice them. Begin by instrumenting these four signals across your most critical services.
SRE vs. DevOps: What's the Difference?
Teams often ask how SRE differs from DevOps, especially when both disciplines focus on improving software delivery. While DevOps emerged as a cultural movement to break down silos between development and operations, SRE provides the engineering discipline and measurable frameworks to operationalize reliability at scale.
How SRE and DevOps Work Together
In practice, SRE and DevOps work together rather than compete. Teams implementing comprehensive SRE automation report 82% faster incident response and 47% fewer change failures. SRE operationalizes DevOps principles through platform engineering and GitOps:
- Platform engineering builds the infrastructure highways (internal developer platforms and golden paths).
- SRE acts as the traffic control system (defining SLO thresholds, error budgets, and verification criteria).
- GitOps handles declarative deployment mechanics while SRE provides governance guardrails.
The breakthrough happens when SRE policies become enforceable guardrails within platform tooling. Policy-as-code transforms SRE requirements like freeze windows and SLO gates into automated checkpoints that GitOps workflows execute without manual intervention. Organizations combining SRE and platform engineering see measurable improvements in uptime and recovery time. Development teams deploy more frequently while experiencing fewer customer-visible incidents.
Building an SRE Team
When deployments happen multiple times per day, manual verification becomes impossible and deployment anxiety spreads across engineering teams. Building the right SRE team means assembling engineers who can automate reliability work and eliminate toil.
Essential Skills: Engineers Who Automate Reliability
Look for engineers who blend coding skills with operational experience. These people can write Python or Go scripts to automate deployment checks, understand how services fail across networks, and know which metrics actually matter when things go wrong. They build safety features directly into applications, like circuit breakers that stop bad requests from spreading, or feature flags that let you turn off broken features instantly. Most importantly, they treat reliability problems as engineering challenges that need permanent fixes, not just quick patches.
Team Topologies: Central, Embedded, and Hybrid Models
SRE team structure fundamentally comes down to where reliability expertise lives in your organization:
- Central SRE teams build shared platforms, define policy standards, and create automation that scales across services. Think observability frameworks, deployment verification, and incident response tooling.
- Embedded SREs work directly within product teams, coaching developers on reliability practices and implementing service-specific improvements.
- Hybrid models combine both approaches. A small central team establishes reliability standards and provides AI-powered verification platforms, while embedded SREs implement and adapt these practices for their specific services.
Research across 145 organizations shows that hybrid SRE models report 87% better knowledge sharing and 79% improved operational efficiency compared to single-model approaches. Choose your structure based on organization size, service count, and reliability maturity. Startups often start embedded, enterprises lean central, but most successful organizations evolve toward hybrid models as they scale.
Getting Started with SRE
Learning how to implement SRE best practices doesn't require transforming your entire organization overnight. The most successful adoptions follow three focused steps: select a critical service and establish reliability targets, implement intelligent rollback capabilities, and create self-service guardrails. This approach proves value quickly while building confidence for broader SRE adoption across your microservices architecture.
Pick One Service and Define Your First SLOs
Choose one business-critical application that's actively developed and provides comprehensive monitoring and metrics. Define SLOs from your users' perspective: 99.95% availability, 95th percentile latency under 200ms, or error rates below 0.1%. Use a four-week rolling window for evaluation and document your error budget policy with specific actions when budgets are exhausted.
Implement Intelligent Rollback Capabilities
Treat AI-powered rollback as your first must-have milestone. It immediately reduces release risk and builds confidence for high-frequency deployments. Context-aware platforms can detect anomalies instantly and trigger self-healing responses without human intervention, turning a potential 15-minute manual recovery into a 30-second intelligent response.
Codify Guardrails with Policy as Code
Policy as Code transforms operational rules into version-controlled artifacts that run in your CI/CD pipeline. Use tools like Open Policy Agent to enforce security baselines, block risky configuration changes, and verify deployment rules before production. Create reusable pipeline templates that embed these policies, allowing teams to self-serve while maintaining compliance.
A 90-Day SRE Adoption Plan
Breaking down SRE adoption into focused sprints makes the transformation manageable and delivers measurable improvements. This phased approach builds reliability practices incrementally without disrupting daily operations.
- Days 1-30: Define 3-4 customer-facing SLIs, set realistic SLOs (start with 99.9%), and establish clear incident roles with escalation policies.
- Days 31-60: Deploy canary strategies with automated health checks, integrate observability tools for real-time verification, and enable automated rollback on anomaly detection.
- Days 61-90: Implement error budget policies that gate risky changes, introduce blameless postmortem templates, and create self-service deployment templates.
- Ongoing: Track toil reduction percentage, MTTR improvements, and SLO achievement rates to measure progress and justify continued investment.
Common Pitfalls and How to Avoid Them
- Pitfall: Alerts tied to raw error rates instead of meaningful SLO breaches create noise that exhausts teams and influences turnover.
- How to avoid: Tie alerts to SLO breaches and burn rate consumption (such as 2% of your error budget in one hour) rather than arbitrary thresholds. This ensures alerts fire only when customer experience suffers, not when internal metrics fluctuate.
- Pitfall: Custom bash scripts for each service create technical debt that compounds with scale and becomes impossible to maintain consistently.
- How to avoid: Use reusable templates and centralized policies to codify best practices once and apply them everywhere. This eliminates the burden of maintaining service-specific scripts.
- Pitfall: Creating and maintaining service-specific monitoring scripts for deployment verification consumes significant SRE time and creates inconsistency.
- How to avoid: Leverage AI-powered platforms to automatically generate verification profiles that connect to your observability tools, eliminating manual script creation while ensuring reliable rollback procedures.
SRE Tools and Technologies
Traditional SRE tools force teams to choose: comprehensive features or operational simplicity. Modern platforms eliminate this tradeoff by integrating observability, delivery automation, and AI-powered verification into unified workflows that scale reliability practices without scaling headcount.
Observability: From Dashboard Watching to Automated Correlation
Enterprise observability suites like Datadog, New Relic, and Dynatrace automatically correlate metrics across services, while Prometheus and Grafana provide the open-source foundation for time-series collection and visualization. OpenTelemetry has become foundational for unified instrumentation, enabling teams to collect metrics, logs, and traces without vendor lock-in while supporting automated anomaly detection.
GitOps and Delivery: From Argo Sprawl to Centralized Control
Argo CD excels at declarative infrastructure changes and deployments, but managing multiple instances across teams creates "Argo sprawl" and coordination nightmares. Enterprise control planes solve this by centralizing visibility and orchestrating multi-stage promotions while preserving your GitOps investments. These platforms add policy-as-code governance, drift detection, and release coordination that eliminates manual handoffs between teams and environments.
AI-Powered Automation: From Manual Verification to Instant Rollbacks
Deployment anxiety stems from slow detection and manual rollback processes that extend outages. AI-assisted verification automatically analyzes metrics from your observability tools, compares against stable baselines, and triggers rollbacks within seconds of detecting regressions. Combined with golden-path templates and policy-as-code, these tools enable developer self-service while reducing incident response times by up to 82% and eliminating the manual toil that burns out SRE teams.
From Principles to Practice with AI for SRE
SRE transforms reliability from reactive firefighting into proactive engineering. When SLOs gate your releases, error budgets balance speed with safety, and AI-powered verification runs automatically, and deployment anxiety disappears.
Modern SRE implementation connects your observability tools directly to deployment pipelines through intelligent automation. Harness Continuous Delivery & GitOps eliminates manual verification toil, detecting regressions and rolling back in seconds instead of minutes.
Ready to transform your deployment process from anxiety-inducing to confidence-building? Explore Harness Continuous Delivery & GitOps to see how AI-powered verification and automated remediation deliver reliability at scale.
SRE Frequently Asked Questions
Common questions arise when implementing SRE practices for high-frequency deployments. These answers address the most frequent concerns from engineers scaling reliability in production.
What are the main responsibilities of a Site Reliability Engineer?
SREs design and implement reliability features like circuit breakers, automated rollbacks, and progressive delivery strategies. They define SLIs and SLOs, lead incident response, and run blameless postmortems to drive systemic improvements. The role balances reliability engineering with strategic planning across services.
How do error budgets actually work in practice?
Error budgets quantify acceptable risk as a percentage of your SLO target. For example, with a 99.9% monthly SLO, you have 43 minutes of downtime budget to spend on changes. When budget burns too quickly, automated policies can slow or halt risky changes until services recover, creating alignment between development velocity and reliability goals.
What's the difference between SRE and traditional operations?
Traditional operations focus on keeping systems running through manual processes and reactive monitoring. Harness SRE empowers teams to move from "how do we fix this?" to "how do we prevent this systematically?" by treating reliability as an engineering discipline using code, automation, and proactive measurement.

Phil Christianson on Balancing Innovation and Reliability in Modern Product Teams
At SREday NYC 2026, the ShipTalk podcast spoke with Phil Christianson, Chief Product Officer at Xurrent, for a leadership perspective on the intersection of product strategy, engineering investment, and platform reliability.
While many of the conversations at the conference focused on tools, automation, and incident response, Phil offered a view from the C-suite level, where decisions about engineering priorities and R&D investment ultimately shape how reliability practices evolve.
In the episode, ShipTalk host Dewan Ahmed, Principal Developer Advocate at Harness, spoke with Phil about how product leaders decide when to invest in new features versus strengthening the underlying platform that supports them.
🎧 Listen to the Full Episode
Balancing Innovation and Platform Stability
For product leaders responsible for large engineering budgets, the tension between innovation and reliability is constant.
New technologies—especially AI—create strong pressure to ship new features quickly. At the same time, the long-term success of a platform depends on its stability and reliability.
Phil has managed large R&D investments across global teams, and he believes that sustainable innovation requires a careful balance between these priorities.
Organizations that focus only on new features often accumulate technical debt that eventually slows development. On the other hand, teams that focus exclusively on stability risk falling behind competitors.
The role of product leadership is to ensure that innovation and reliability evolve together, rather than competing for resources.
When to Invest in the SRE Foundation
One of the hardest decisions for product leaders is determining when it is time to shift focus from new features to foundational improvements.
Investments in areas like observability, reliability engineering, and infrastructure automation may not immediately produce visible product features, but they can dramatically improve long-term development velocity.
Phil argues that product leaders should view these investments not as overhead but as strategic enablers.
When systems are reliable and well-instrumented, engineering teams can ship faster, experiment more safely, and recover from incidents more effectively.
In this sense, the work of SRE teams becomes an important part of the product roadmap itself.
Turning SRE Into a Catalyst for Innovation
Reliability engineering is sometimes perceived as the team that slows things down—adding guardrails, enforcing deployment policies, and pushing back on risky changes.
Phil believes that perspective misses the bigger picture.
When reliability practices are integrated into product development correctly, SRE teams can actually accelerate innovation.
By improving deployment safety, observability, and automation, SRE teams allow developers to move faster with confidence.
Instead of acting as a barrier, reliability engineering becomes a catalyst that enables experimentation without compromising system stability.
This shift in mindset requires empowered teams, strong collaboration between product and engineering, and leadership that values long-term platform health.
The Role of Empowered Teams
A recurring theme in Phil’s leadership philosophy is the importance of empowered teams.
Rather than managing work through strict task lists and top-down directives, he emphasizes creating environments where engineers can take ownership of the systems they build.
In these environments:
- product leaders provide strategic direction
- engineers have autonomy to design solutions
- reliability practices are built directly into development workflows
This model allows teams to balance creativity and discipline—two qualities that are essential when building large-scale platforms.
Final Thoughts
Phil Christianson’s perspective highlights an important truth about modern software platforms.
Reliability engineering is not just an operational concern—it is a product strategy decision.
When organizations invest in strong reliability foundations and empower their teams to build safely, they create platforms that can evolve faster and scale more effectively.
In the end, the most successful products are not just the ones with the most features.
They are the ones built on systems that teams—and customers—can rely on.
🎧 Listen to the Full Episode
Subscribe to the ShipTalk Podcast
Enjoy conversations like this with engineers, founders, and technology leaders shaping the future of reliability and platform engineering.
Follow ShipTalk on your favorite podcast platform and stay tuned for more stories from the people building the systems that power modern technology. 🎙️🚀

The Multiverse of IT Storytelling
Leon Adato on SRE Lessons from Spider-Verse and Surviving Tech Failures
At SREday NYC 2026, the ShipTalk podcast welcomed Leon Adato, Principal Technical Marketing Engineer at Cribl and host of the Technically Religious podcast, for a conversation about how engineers navigate failure and uncertainty in complex systems.
In the episode, ShipTalk host Dewan Ahmed, Principal Developer Advocate at Harness, spoke with Leon about finding lessons for reliability engineering in unexpected places—including movies like Spider-Man: Into the Spider-Verse.
For Leon, the world of SRE is full of moments that feel like plot twists: systems fail, vendors disappear, and tools that once seemed essential suddenly become obsolete.
The key is not avoiding those moments—but learning how to respond to them.
🎧 Listen to the Full Episode
What Spider-Verse Teaches Us About Being an SRE
Leon often draws parallels between technology and storytelling, and one of his favorite examples comes from Spider-Man: Into the Spider-Verse.
In the movie, Miles Morales struggles to control his powers because he is overwhelmed by pressure. At one point he literally gets stuck to a ceiling because he cannot relax.
Leon sees that moment as a perfect metaphor for engineers during a production incident.
When systems break and the pressure is high, engineers can become overwhelmed by the situation. That stress can make it harder to think clearly and move forward.
Just like Miles learning to trust himself, SREs often need to pause, refocus, and trust their experience to navigate a difficult outage.
When a Technology Choice Falls Apart
Leon’s talk at SREday focused on a scenario many engineers eventually face: watching a technology choice fail.
Sometimes the failure comes from a vendor implosion.
Sometimes the product simply becomes obsolete.
Sometimes the tool just doesn’t live up to its promises.
In those moments, engineers may feel like the decision reflects badly on them.
But Leon argues that these situations often produce valuable outcomes.
When a tool collapses or a platform fails, teams are forced to rethink assumptions, improve architecture, and make better decisions moving forward.
What initially feels like a disaster can become an opportunity to build stronger systems and stronger teams.
Owning the Glitch
Another theme Leon emphasized is the importance of owning failures openly.
When something breaks, engineers can respond in very different ways. Some people try to hide the issue or shift blame. Others acknowledge the problem and focus on fixing it.
Leon believes the second approach leads to healthier engineering cultures.
Reliability engineering depends on transparency. Systems fail, and the best teams treat those moments as opportunities to learn rather than something to hide.
Owning the glitch helps organizations improve their systems—and helps engineers grow in the process.
Final Thoughts
Leon Adato’s message for SREs is simple but powerful.
Technology will always change. Tools will come and go. Systems will occasionally fail.
What matters most is how engineers respond to those moments.
Staying calm during outages, learning from failed technology choices, and approaching problems with honesty and humility are what ultimately make teams stronger.
And sometimes, a good lesson in reliability engineering can even come from a superhero movie.
🎧 Listen to the Full Episode
Subscribe to the ShipTalk Podcast
Enjoy conversations like this with engineers, platform builders, and reliability leaders from across the industry.
Follow ShipTalk on your favorite podcast platform and stay tuned for more stories from the people building the systems that power modern technology. 🎙️🚀

Birol Yildiz on Autonomous Incident Response and the Future of AI SRE
At SREday NYC 2026, the ShipTalk podcast welcomed Birol Yildiz, Co-founder and CEO of ilert, for a conversation about the next evolution of incident response.
In the episode, ShipTalk host Dewan Ahmed, Principal Developer Advocate at Harness, spoke with Birol about how artificial intelligence is transforming reliability engineering—from simply assisting engineers during incidents to autonomously diagnosing and resolving outages.
For many SRE teams, the goal has always been clear: fewer late-night pages and faster recovery times. According to Birol, the next wave of tooling may finally make that possible.
🎧 Listen to the Full Episode
The Shift Toward Autonomous Incident Resolution
For years, AI tools in operations have focused mainly on post-incident assistance—summarizing alerts, analyzing logs, or helping generate incident reports.
But Birol believes the industry is now moving beyond that stage.
Instead of just helping engineers understand what happened, AI SRE agents are beginning to actively resolve incidents in real time.
These systems ingest signals from multiple sources, including:
- Observability data and system metrics
- Deployment and infrastructure changes
- Application logs and traces
- Code context and service dependencies
By correlating these signals, an AI agent can detect the root cause of an outage and automatically execute remediation steps—often within minutes.
The result is a dramatic shift in incident response.
Rather than waking up engineers with alerts in the middle of the night, the system can often resolve the issue first and present a clean incident report afterward.
How AI Combines Observability, Deployment Context, and Code Intelligence
One of the biggest challenges for SREs during incidents is context switching.
Engineers typically jump between multiple tools to investigate problems:
- Observability dashboards
- Log aggregation systems
- Deployment pipelines
- Infrastructure changes
- Application code
Each system provides only part of the picture.
According to Birol, modern AI agents work by aggregating all of that context into a single reasoning layer.
Instead of humans manually stitching together signals, the system continuously evaluates relationships between events. For example:
- A deployment happened minutes before a spike in latency
- A specific service dependency began failing
- Error rates correlate with a configuration change
By combining these insights, the AI can determine whether the correct response is to:
- Roll back a deployment
- Restart a failing service
- Scale infrastructure resources
- Route traffic away from a problematic component
To prevent risky actions, these systems operate within carefully defined guardrails and remediation policies, ensuring automation helps rather than harms production environments.
The Rise of the “Product-Minded” SRE
Birol’s perspective on reliability engineering is shaped by his background as Chief Product Owner for Big Data products at REWE Digital before founding ilert.
That experience gave him a product-centric lens on operations.
Instead of treating incidents purely as operational events, he sees them as product experience problems.
From that viewpoint, reliability engineering becomes less about firefighting and more about designing systems that:
- reduce operational toil
- improve developer productivity
- accelerate recovery times
- minimize customer impact
As autonomous agents take on more of the routine incident work, the role of the human SRE will likely evolve.
Rather than spending most of their time responding to alerts, engineers will increasingly focus on:
- defining automation policies
- improving observability coverage
- designing safer remediation workflows
- validating AI-driven incident responses
In other words, the SRE of the future may look less like a firefighter and more like a systems architect overseeing intelligent automation.
Building Toward a World Without 3 A.M. Pages
For many engineers, being on-call remains one of the most stressful parts of the job.
Birol believes that autonomous incident resolution can fundamentally change that experience.
If AI agents can reliably detect, diagnose, and remediate common failure scenarios, teams can dramatically reduce the number of alerts that require human intervention.
The long-term goal isn’t to remove humans from operations entirely. Instead, it’s to eliminate the repetitive operational toil that prevents engineers from focusing on higher-value work.
When systems resolve routine incidents automatically, teams gain the freedom to spend more time on:
- improving system architecture
- building better developer tooling
- shipping new features
- innovating on reliability practices
Final Thoughts
Birol Yildiz’s vision for the future of SRE reflects a broader shift happening across the industry.
Observability, automation, and AI are converging to create systems that can understand infrastructure and respond intelligently to failures.
If that vision succeeds, the next generation of reliability engineering might look very different from today.
Fewer dashboards.
Fewer manual investigations.
And far fewer 3 a.m. incident pages.
Subscribe to the ShipTalk Podcast
🎧 Listen to the Full Episode
Enjoy conversations like this with engineers, founders, and reliability leaders from across the cloud-native ecosystem.
Follow ShipTalk on your favorite podcast platform and stay tuned for more stories from the people building the systems that power modern technology. 🎙️🚀
.png)
Harness AI January 2026 Updates: Human-Aware SRE and Smarter API and Application Security
Harness AI is starting 2026 by doubling down on what it does best: applying intelligent automation to the hardest “after code” problems, incidents, security, and test setup, with three new AI-powered capabilities. These updates continue the same theme as December: move faster, keep control, and let AI handle more of the tedious, error-prone work in your delivery and security pipelines.
What’s New in Harness AI:
- Human-aware incident analysis that correlates conversations with changes
- AI-driven API naming that reduces security noise
- Natural-language auth script generation for faster AST onboarding
- AppSec agent for querying security data and generating policies
Human-Aware Change Agent for AI SRE
Harness AI SRE now includes the Human-Aware Change Agent, an AI system that treats human insight as first-class operational data and connects it to the changes that actually break production. Instead of relying only on logs and metrics, it listens to real incident conversations in tools like Slack, Teams, and Zoom and turns those clues into structured signals.
- The AI Scribe captures key decisions, timestamps, symptoms, and “right before this happened…” moments from live conversations, filtering out unrelated chatter.
- The Change Agent uses these human signals to drive a change-centric investigation across deployments, feature flags, config, infra changes, and ITSM records, then produces evidence-backed hypotheses such as, “This checkout deployment changed retry behavior 12 minutes before the incident, and latency spiked immediately after.”
By unifying human observations with the software delivery knowledge graph and change intelligence, teams get a much faster path from “what are we seeing?” to “what changed?” to “what should we roll back or fix safely?” The result is shorter incidents, clearer ownership, and a teammate-like AI that reasons about both people and systems in real time. Learn more in the announcement blog post.
AI-Powered API Naming for Cleaner Security Signals
Effective application security starts with knowing what you actually have in production. Traditional API naming based on regex heuristics often leads to over-merged or under-merged API groups, noisy inventories, and false positives across detection workflows.
This month, API naming in our Traceable product gets a major upgrade with AI-powered API semantics:
- API naming is now powered by LLMs that understand intent, behavior, and functional semantics, not just URL or path similarity. The result is more stable, meaningful API groupings that reflect how your services actually behave.
- The LLM-driven results were baselined against custom naming rules from advanced users and achieved >98.7% average match in internal benchmarking.
- With cleaner API groupings, teams see reduced false positives across vulnerability detection, AST, and runtime protection, and a less noisy API inventory that’s easier for security and platform teams to act on.
For security leaders trying to tame API sprawl, this is a foundational improvement that boosts signal quality across the entire platform.
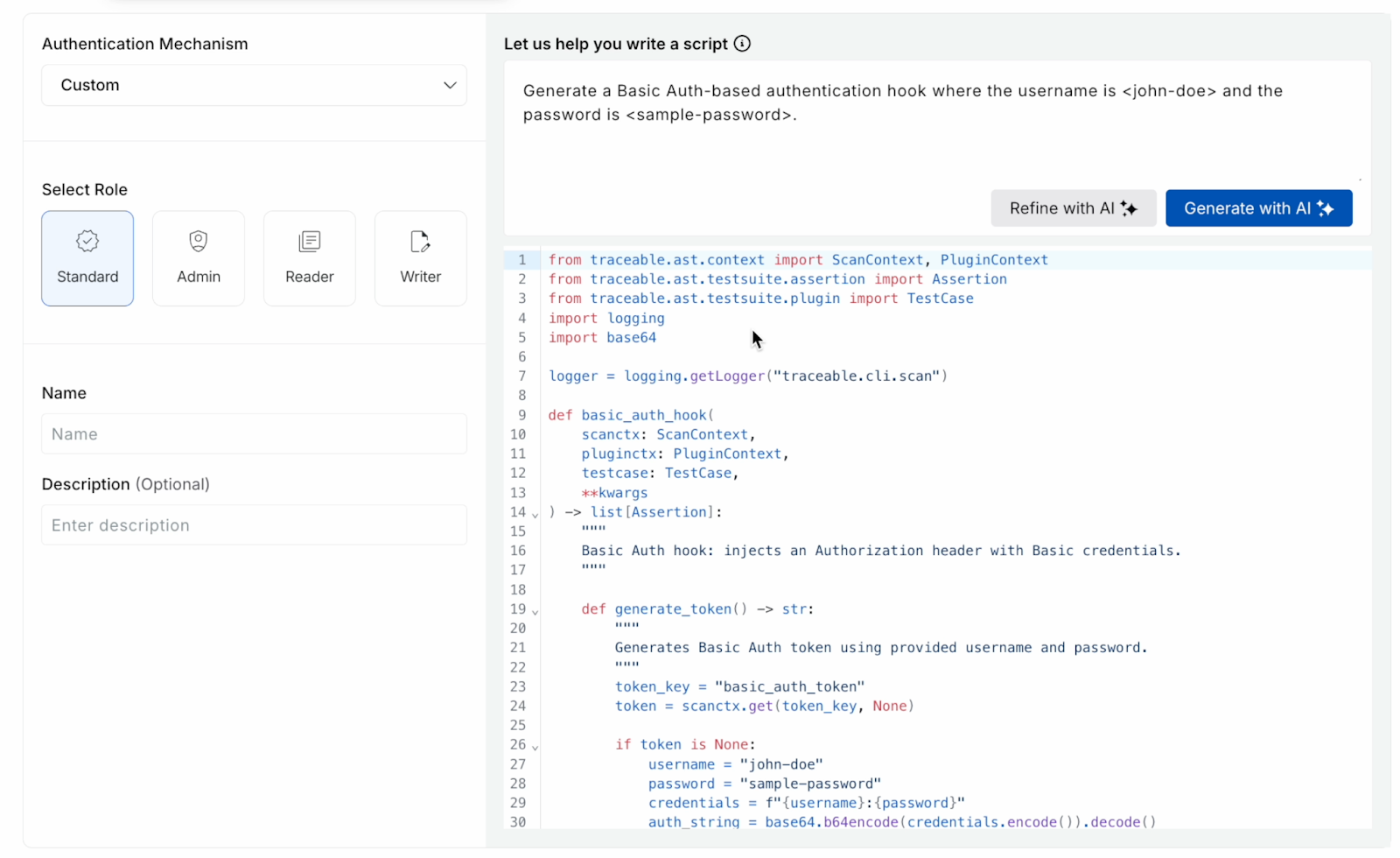
AI-Based Auth Script Generation: Faster, Safer API Security Testing Setup
Authentication setup has been one of the most consistent sources of friction for application security testing. Manual scripting, validation cycles, and back-and-forths often create bottlenecks — and a broken auth script can quietly invalidate an entire scan run.
To solve this, all API Security Testing customers now get AI-based Authentication Script Generation:
- Generate auth scripts by simply describing the scenario in natural language; AI produces a ready-to-use script in a few seconds, which you can refine, edit, or use as a base for existing scripts.
- The feature works alongside existing flows, so teams can keep using form-based or code-based auth with identical behavior while layering in AI where it helps most.
The result is less time lost to brittle auth setup, faster onboarding for new apps, and fewer failed scans due to script errors.
You can find implementation details and examples in the docs.
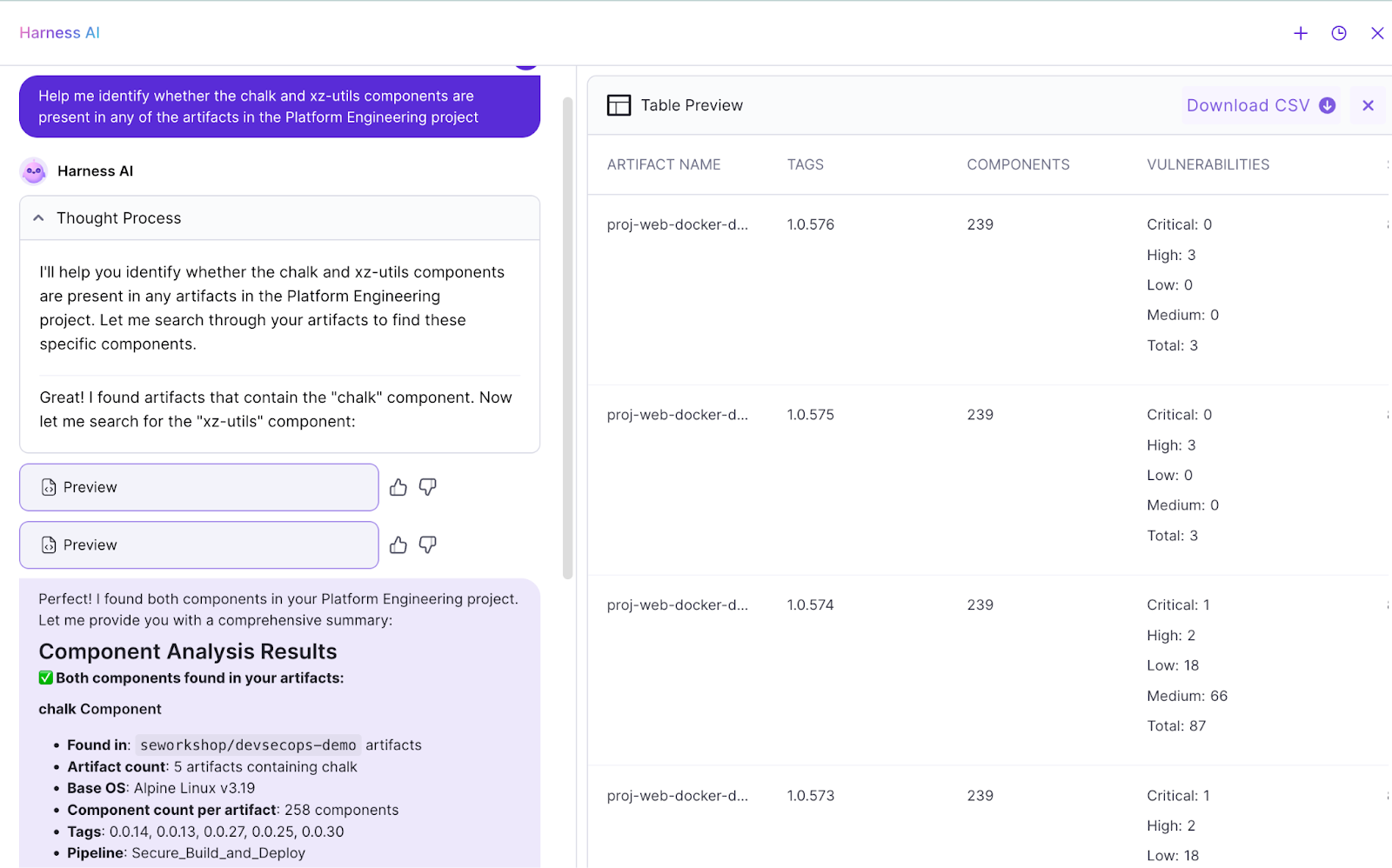
Chat with AppSec Agent: Security Data, in Plain Language
Security and platform teams often know the question they want to ask: “Where is this component used?” “Which exemptions are still pending?” , but answering it requires hopping across dashboards and stitching together filters by hand.
The new AppSec Agent makes this dramatically easier by letting you query AppSec data using natural language.
Here's what it does:
- In Harness STO, you can ask about security issues and exemptions, then drill into issue-level insights from STO results without manually navigating views or composing complex filters. Questions like “Approve all valid pending exemptions in this project of issue type secret” become a single prompt instead of a multi-step workflow.
- In Harness SCS, you can query for artifacts, code repos, SBOMs, chain-of-custody, and compliance results, then even generate OPA policies with a single prompt to block components based on license risk or vulnerable packages. For example, “Create an OPA policy to block the deployment of components licensed under the GPL-3.0 license” or “Help me identify whether the chalk and xz-utils components are present in any of the artifacts in this project” are fully supported.
- The AppSec Agent is available across all production environments and integrates directly with Harness Security Testing Orchestration (STO) and Software Supply Chain Assurance (SCS).
This is a big step toward making AppSec data as queryable and collaborative as the rest of your engineering stack. Learn more in the docs.
How This Fits the Harness AI Vision
Harness AI is focused on everything after code is written — building, testing, deploying, securing, and optimizing software through intelligent automation and agentic workflows. January’s updates extend that vision across:
- Security and AppSec: higher-fidelity API grouping, fewer false positives, and faster AST onboarding with AI-generated auth.
- SRE and Operations: human-aware incident response that unifies human and machine signals into a single, change-driven flow.
- Governance and Compliance: consistent with December’s AI governance updates, all of these capabilities inherit Harness’s approach of policy-aware AI, auditability, and RBAC-aligned actions.
Teams adopting these features can ship changes faster, investigate less, and focus more of their time on the work that actually moves the business — while Harness AI quietly handles the complexity in the background.
Checkout Event: Harness at RSAC
Announcing the Harness Human-Aware Change Agent
At Harness, our story has always been about change — helping teams ship faster, deploy safer, and control the blast radius of every modification to production. Deployments, feature flags, pipelines, and governance are all expressions of how organizations evolve their software.
Today, the pace of change is accelerating. As AI-assisted development becomes the norm, more code reaches production faster, often without a clear link to the engineer who wrote it. Now, Day 2 isn’t just supporting the unknown – it’s supporting software shaped by changes that may not have a clear human owner.
And as every SRE and on-call engineer knows, even rigorous change hygiene doesn’t prevent incidents because real-world systems don’t fail neatly. They fail under load, at the edges, in the unpredictable ways software meets traffic patterns, caches, databases, user behavior, and everything in between.
When that happens, teams fall back on what they’ve always relied on: Human conversation and deep understanding of what changed.
That’s why today we’re excited to introduce the Harness Human-Aware Change Agent — the first AI system designed to treat human insight as operational data and use it to drive automated, change-centric investigation during incidents.
Not transcription plus RCA. One unified intelligence engine grounded in how incidents actually unfold.
📞 A Quick Look at Harness AI SRE
The Human-Aware Change Agent is part of Harness AI SRE — a unified incident response system built to help teams resolve incidents faster without scaling headcount. AI SRE brings together the critical parts of response: capturing context, coordinating action, and operationalizing investigation.
At the center is the AI Scribe, because the earliest and most important clues in an incident often surface in conversation before they appear in dashboards. Scribe listens across an organization’s tools with awareness of the incident itself – filtering out unrelated chatter and capturing only the decisions, actions, and timestamps that matter. The challenge isn’t producing a transcript; it’s isolating the human signals responders actually use.
Those signals feed directly into the Human-Aware Change Agent, which drives change-centric investigation during incidents.
And once that context exists, AI SRE helps teams act on it: Automation Runbooks standardize first response and remediation, while On-Call and Escalations ensure incidents reach the right owner immediately.
AI SRE also fits into the tools teams already run — with native integrations and flexible webhooks that connect observability, alerting, ticketing, and chat across systems like Datadog, PagerDuty, Jira, ServiceNow, Slack, and Teams.
🌐 Why We Built a Human-Aware Change Agent
Most AI approaches to SRE assume incidents can be solved entirely through machine signals — logs, metrics, traces, dashboards, anomaly detectors. But if you’ve ever been on an incident bridge, you know that’s not how reality works.
Some of the most important clues come from humans:
- “The customer said the checkout button froze right after they updated their cart.”
- “Service X felt slow an hour before this started.”
- “Didn’t we flip a flag for the recommender earlier today?”
- “This only happens in the US-East cluster.”
These early observations shape the investigation long before anyone pulls up a dashboard.
Yet most AI tools never hear any of that.
The Harness Human-Aware Change Agent changes this. It listens to the same conversations your engineers are having — in Slack, Teams, Zoom bridges — and transforms the human story of the incident into actionable intelligence that guides automated change investigation.
It is the first AI system that understands both what your team is saying and what your systems have changed — and connects them in real time.
🔍 How the Human-Aware Change Agent Works
1. It listens and understands human context.
Using AI Scribe as its conversational interface, the agent captures operational signals from a team’s natural dialogue – impacted services, dependencies, customer-reported symptoms, emerging theories or contradictions, and key sequence-of-events clues (“right before…”).
The value is in recognizing human-discovered clues, and converting them into signals that guide next steps.
2. It investigates changes based on those clues.
The agent then uses these human signals to direct investigation across your full change graph including deployments, feature flags or config changes, infrastructure updates, and ITSM change records – triangulating what engineers are seeing with what is actually changing in your production environment.
3. It surfaces evidence-backed hypotheses.
Instead of throwing guesses at the team, it produces clear, explainable insights:
“A deployment to checkout-service completed 12 minutes before the incident began. That deploy introduced a new retry configuration for the payment adapter. Immediately afterward, request latency started climbing and downstream timeouts increased.”
Each hypothesis comes with supporting data and reasoning, allowing teams to quickly validate or discard theories.
4. It helps teams act faster and safer
By uniting human observations with machine-driven change intelligence, the agent dramatically shortens the path from:
What are we seeing? → What changed? → What should we do?
Teams quickly gain clarity on where to focus, what’s most suspicious, and which rollback or mitigation actions exist and are safest.
🌅 A New Era of Incident Response
With this release, Harness is redefining what AI for incident management looks like.
Not a detached assistant. Not a dashboard summarizer. But a teammate that understands what responders are saying, investigates what systems have changed, connects the dots, and helps teams get to truth faster.
Because the future of incident response isn’t AI working alone. It’s AI working alongside engineers — understanding humans and systems in equal measure.
Book a demo of Harness AI SRE to see how human insight and change intelligence come together during real incidents.

Harness x AWS re:Invent 2025
Enter the AI Survival Arena 🦑🟩
Dec 1 to 5 · Booth 731 · The Venetian · Las Vegas
(Harness is an AWS Partner)
AI dominates re:Invent 2025, and engineering leaders everywhere are asking the same question:
Which AI will actually help teams ship better software on AWS with less friction?
This year Harness invites you to step into a Squid Game inspired AI Survival Arena. Pick your role, take on challenges, earn rewards, and leave Las Vegas with real AI powered delivery strategies. Captain Canary will be on site in a special 456 uniform to welcome players into the game.

Add Booth 731 to your conference planner and find all event details here.
🔺 Choose Your Role
Select the role that defines your strategy inside the arena:
- The Builder seeking faster dev loops and fewer blockers
- The Platform Architect creating golden paths for teams
- The Cost Strategist eliminating AWS waste
- The Security Guardian protecting code, pipelines, and AI flows
Your journey begins at Booth 731.
🟥 Main Challenge: Beat the AI Tool Sprawl Game Master
In The State of AI in Software Engineering, teams report using 8 to 10 different AI tools across dev, test, security, and ops. Tool overload slows delivery, increases friction, and creates unnecessary complexity.
Your objective: Discover how one unified, AI powered delivery platform on AWS can simplify CI, CD, cost, and security at once.
Download The State of AI in Software Engineering before re:Invent.
🏟 Booth 731: The AI Survival Arena
Inside the arena, you can unlock:
- Live AI demos across CI, CD, cost, and security
- The Ask an Agent Challenge, where you present a delivery bottleneck and see how AI solves it
- A chance to Spin to Win on our slot machine
- One-to-one strategy conversations with product and engineering leaders
This is where the competition begins.
🎁 Bonus Loot: Swag Drops
Get ready for epic AI GAME swag, surprise giveaways, and booth-exclusive merch. We’re talking a mix of playful items, premium collectibles, and fan favorites designed to make your re:Invent run a lot more fun. Swing by to see what you can win.
🟩 Side Quests and Achievements
Complete as many as you can:
☐ Ask where AI can remove a step in your delivery flow
☐ Pick your role and request a Day 1 Experiment to try at home
☐ Bring your cloud bill and learn where AI optimization can have immediate impact
☐ Share your top engineering metric and see how AI can improve it
Bonus: Share your most challenging pipeline story and ask how AI can help resolve it.
🌃 Night Raid: After Hours with Harness
Dec 2 · 8:45 PM to 11:45 PM · Flight Club, The Venetian
Darts, drinks, and DevOps. This is where teams talk honestly about AI, velocity, AWS, risk, and reality.
Register for the After Hours event.
🥂 Leadership Missions
For directors, VPs, and execs looking for high signal conversations.
Executive Resiliency Roundtable
Dec 2 · 5:30 PM to 8:30 PM · Mastro’s Ocean Prime
VIP Networking Dinner
Dec 3 · 6:30 PM to 8:30 PM · STK Steakhouse [Invite only].
Enjoy a curated culinary experience and meaningful conversation with Harness executives and industry leaders in an evening designed to connect, celebrate, and look ahead.
This dinner is at capacity. To join the waitlist, email jessica.jackson@harness.io
The Future of AppSec Luncheon
Dec 3 · 11:30 AM to 1:30 PM · Sadelle’s Cafe
Connect with technology and security leaders to explore modern AppSec challenges and how top organizations are securing apps and APIs without slowing innovation. Gain actionable insights through open conversation in an intimate, curated executive setting.
Register for the AppSec Luncheon.
🎤 Hear from Harness at re:Invent
Engineering the Future of Hospitality: Marriott’s Global Digital Transformation
Thursday, December 4 | 1:00 PM | Room: MGM Grand 116
Join leaders from Marriott International and Harness for a deep dive into how Marriott modernized their global delivery ecosystem, built a resilient cloud-native foundation, and prepared their engineering org for an AI-enabled future.
Speakers include:
- Jyoti Bansal, CEO, Harness
- Nick Durkin, Field CTO, Harness
- Adnan Haq, VP, DevSecOps & Infrastructure, Marriott International
- Sean Corkum, Sr. Director, DevSecOps & Automation, Marriott International
Add this session to your agenda [DVT104-S].
🤝 Co-op Mode: Harness + AWS
Harness is an AWS Partner with a delivery platform purpose-built for AWS environments. Many teams also choose to run Harness through AWS Marketplace for a native buying experience.
🏁 Final Mission: Your Path to Victory
Before re:Invent
- Download the AI report
- Pick your character
- Bring one challenge you want solved
During re:Invent
- Visit Booth 731
- Hit at least one leadership event or the Marriott session
- Try the Spin to Win machine
After re:Invent
- Run one small experiment inspired by your week
- Meet with Harness for an AI delivery blueprint
See you in Las Vegas.
Come ready to play, learn, build, and win. Step into the arena with confidence because Harness will bring the AWS expertise, the AI innovation, and the platform your team needs to advance.
The games begin at Booth 731. Are you ready to make it to the final round?
Checkout the Event: After Hours with Harness at AWS re:Invent!, re:Invent re:Cap w/ Harness Raffle

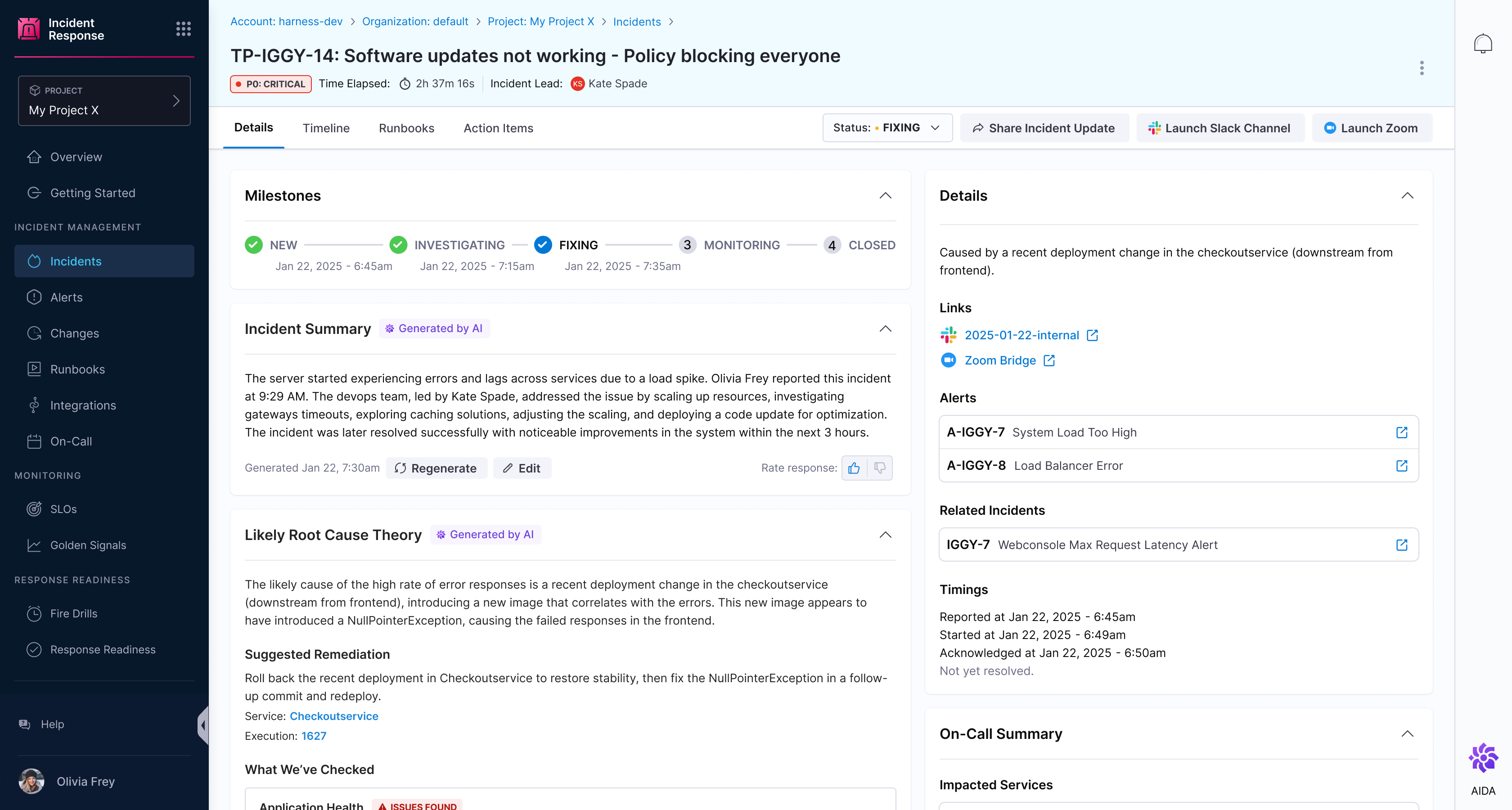
Introducing Harness Incident Response - Coming Soon
Most incidents begin with change, yet traditional incident response tools treat them as isolated events. What if your response was seamlessly connected to the systems, changes, and workflows that caused them—leveraging generative AI to connect the dots? Not as a replacement for your team, but as a teammate working alongside them to help prevent, triage, and resolve issues faster.
We’re thrilled to announce that Harness Incident Response (IR) is coming! This next-generation solution combines proactive issue prevention and rapid incident resolution to empower modern teams to minimize downtime, streamline workflows, and achieve operational excellence.
Harness Incident Response: AI-Powered, Human in the Loop Reliability
Harness IR builds on the foundation of Harness’s AI agent architecture, extending its capabilities beyond software delivery into the realm of incident response. At the heart of Harness IR is an always-available AI SRE agent seamlessly integrated within the Harness DevOps ecosystem. The AI SRE agent delivers actionable insights, guided triage, and tailored recommendations by connecting data across CI/CD pipelines, Feature Flags, infrastructure changes, and external updates. It doesn’t just correlate changes—it works dynamically with your team, asking questions to fill in gaps and ensuring critical context is never missing. Think of it as a dynamic runbook reimagined, where AI doesn’t act alone but collaborates with humans to drive faster, smarter decisions.
Harness IR is built on a foundation of end-to-end visibility and automation, enabling teams to track every change across the software delivery lifecycle, from code commits to deployments, and overlay that with alerts and incidents for a holistic view. It provides a single pane of glass for operational visibility, centralizing all critical data so your team can anticipate and mitigate issues before they escalate.
How Harness IR Makes Incident Response Smarter and Faster
Leverage AI for Proactive Incident Response
Harness the power of AI to detect application failures, identify root causes, and suggest actionable remediation steps. The AI SRE agent ensures faster, smarter decisions while preventing future issues by delivering actionable insights and guiding teams through triage and resolution.
Orchestrate and Visualize Operations Across Your Entire Pipeline
Coordinate workflows, automate responses, and streamline incident resolution with an end-to-end operational control plane spanning the entire software delivery lifecycle—including deployments, feature releases, security incidents, and cost anomalies. More than just orchestration, it acts as a centralized operations hub, offering a single pane of glass to monitor your pipeline and controls to take action in real-time.
.png)
Streamline the Incident Management Process
Harness IR combines on-call management, runbooks, incident workflows, readiness drills, and SLO tracking into a single, unified platform. Fully integrated into your DevOps workflows, it ensures seamless coordination across teams, clear accountability, and actionable insights. By aligning operations with software delivery, it enhances readiness, improves MTTR, and drives continuous improvement in reliability and efficiency.

Prepare for the Unexpected with Incident Response Readiness
Plan, prepare, and respond to incidents with confidence. Simulate real-world scenarios through fire drills to test processes, train teams, and evaluate performance. Gain organization-wide readiness ratings, identifying strengths and areas for improvement to ensure your team is always prepared to respond effectively, minimize downtime, and enhance collaboration during critical incidents.
.png)
Empower Developers in Production
Equip developers with integrated tools, actionable insights, and runbooks designed to debug and resolve application issues in production environments.
With native integrations for tools like Slack, MS Teams, and ServiceNow, Harness IR bridges the gap between automation, collaboration, and AI, empowering your team to focus on what matters most—delivering value to your customers.
.png)
Take Part in the Incident Response Revolution
Join the waitlist today and help shape the future of AI-powered incident response with Harness! Check out our website for more information on our key features and capabilities.