Harness Blog
Featured Blogs

AI is changing both what you build and how you build it - at the same time. Today, Harness is announcing two new products to secure both: AI Security, a new product to discover, test, and protect AI running in your applications, and Secure AI Coding, a new capability of Harness SAST that secures the code your AI tools are writing. Together, they further extend Harness's DevSecOps platform into the age of AI, covering the full lifecycle from the first line of AI-generated code to the models running in production.
In November, Harness published our State of AI-Native Application Security report, a survey of hundreds of security and engineering leaders on how AI-native applications are changing your threat surface. The findings were stark: 61% of new applications are now AI-powered, yet most organizations lack the tools to discover what AI models and agents exist in their environments, test them for vulnerabilities unique to AI, or protect them at runtime. The attack surface has expanded dramatically — but the tools to defend it haven't kept up.
The picture is equally concerning on the development side. Our State of AI in Software Engineering report found that 63% of organizations are already using AI coding assistants - tools like Claude Code, Cursor, and Windsurf - to write code faster. But faster isn't safer. AI-generated code has the same vulnerabilities as human-written code, but now with larger and more frequent commits. AppSec programs that were already stretched thin are now breaking under the volume and velocity.
The result is a blind spot on both sides of the AI equation - what you're building, and what you're building with. Today, Harness is closing that gap.
What Makes Harness Different?
Most security vendors are stuck in their lane. Shift-left tools catch vulnerabilities in code before they reach production. Runtime protection tools block attacks after applications are deployed. And the two rarely talk to each other.
Harness was built on a different premise: real DevSecOps means connecting every stage of the software delivery lifecycle, and closing the loop between what you find in production and what you fix in code.
That's what the Harness platform does today. Application Security Testing brings SAST and SCA directly into the development workflow, surfacing vulnerabilities where they're faster and cheaper to fix. SCS ensures the integrity of artifacts from build to deploy, while STO provides a unified view of security posture — along with policy and governance — across the entire organization.
As code ships to production, Web Application & API Protection monitors and defends applications and APIs in real time, detecting and blocking attacks as they happen. And critically, findings from runtime don't disappear into a security team's backlog — they flow back to developers to address root causes before the next release.
The result is a closed loop: find it in code, protect it in production, fix it fast. All on a single, unified platform.
Today, we're extending that loop into AI - on both sides. AI is reshaping what you build and how you build it simultaneously. A platform that can only address one side of that equation leaves you exposed on the other. Harness closes both gaps.
Introducing AI Security
In the State of AI-Native Application Security, 66% of respondents said they are flying blind when it comes to securing AI-native apps. 72% call shadow AI a gaping chasm in their security posture. 63% believe AI-native applications are more vulnerable than traditional IT applications. They’re right to be concerned.
Harness AI Security is built on the foundation of our API security platform. Every LLM call, every MCP server, every AI agent communicating with an external service does so via APIs. Your AI attack surface isn't separate from your API attack surface; it's an expansion of it. AI threats introduce new vectors like prompt injection, model manipulation, and data poisoning on top of the API vulnerabilities your teams already contend with. There is no AI security without API security.
.png)
With the launch of AI Security, we are introducing AI Discovery in General Availability (GA). AI security starts where API security starts: discovery. You can't assess or mitigate risk from AI components you don't know exist. Harness already continuously monitors your environment for new API endpoints the moment they're deployed. Recognizing LLMs, MCP servers, AI agents, and third-party GenAI services like OpenAI and Anthropic is a natural extension of that. AI Discovery automatically inventories your entire AI attack surface in real time, including calls to external GenAI services that could expose sensitive data, and surfaces runtime risks, such as unauthenticated APIs calling LLMs, weak encryption, or regulated data flowing to external models.
Beyond discovering and inventorying your AI application components, we are also introducing AI Testing and AI Firewall in Beta, extending AI Security across the full discover-test-protect lifecycle.
.png)
AI Testing actively probes your LLMs, agents, and AI-powered APIs for vulnerabilities unique to AI-native applications, including prompt injection, jailbreaks, model manipulation, data leakage, and more. These aren't vulnerabilities that a traditional DAST tool is designed to find. AI Testing was purpose-built for AI threats, continuously validating that your models and the APIs that expose them behave safely under adversarial conditions. It integrates directly into your existing CI/CD pipelines, so AI-specific security testing becomes part of every release — not a one-time audit.
.png)
AI Firewall actively protects your AI applications from AI-specific threats, such as the OWASP Top 10 for LLM Applications. It inspects and filters LLM inputs and outputs in real time, blocking prompt injection attempts, preventing sensitive data exfiltration, and enforcing behavioral guardrails on your models and agents before an attack can succeed. Unlike traditional WAF rules that require manual tuning for every new threat pattern, AI Firewall understands AI-native attack vectors natively, adapting to the evolving tactics attackers use against generative AI.
Harness AI Security with AI Discovery is now available in GA, while AI Testing and AI Firewall are available in Beta.
Introducing Secure AI Coding
"As AI-assisted development becomes standard practice, the security implications of AI-generated code are becoming a material blind spot for enterprises. IDC research indicates developers accept nearly 40% of AI-generated code without revision, which can allow insecure patterns to propagate as organizations increase code output faster than they expand validation and governance, widening the gap between development velocity and application risk."
— Katie Norton, Research Manager, DevSecOps, IDC
AI Security addresses the risks inside your AI-native applications. Secure AI Coding addresses a different problem: the vulnerabilities your AI tools are introducing into your codebase.
Developers are generating more code than ever, and shipping it faster than ever. AI coding assistants now contribute to the majority of new code at many organizations — and nearly half (48%) of security and engineering leaders are concerned about the vulnerabilities that come with it. AI-generated code arrives in larger commits, at higher frequency, and often with less review than human-written code would receive.
SAST tools catch vulnerabilities at the PR stage — but by then, AI-generated code has already been written, reviewed, and often partially shipped. Harness SAST's new Secure AI Coding capability moves the security check earlier to the moment of generation, integrating directly with AI coding tools like Cursor, Windsurf, and Claude Code to scan code as it appears in the IDE. Developers never leave their workflow. They see a vulnerability warning inline, alongside a prompt to send the flagged code back to the agent for remediation — all without switching tools or even needing to trigger a manual scan.
"Security shouldn't be an afterthought when using AI dev tools. Our collaboration with Harness kicks off vulnerability detection directly in the developer workflow, so all generated code is screened from the start." — Jeff Wang, CEO, Windsurf
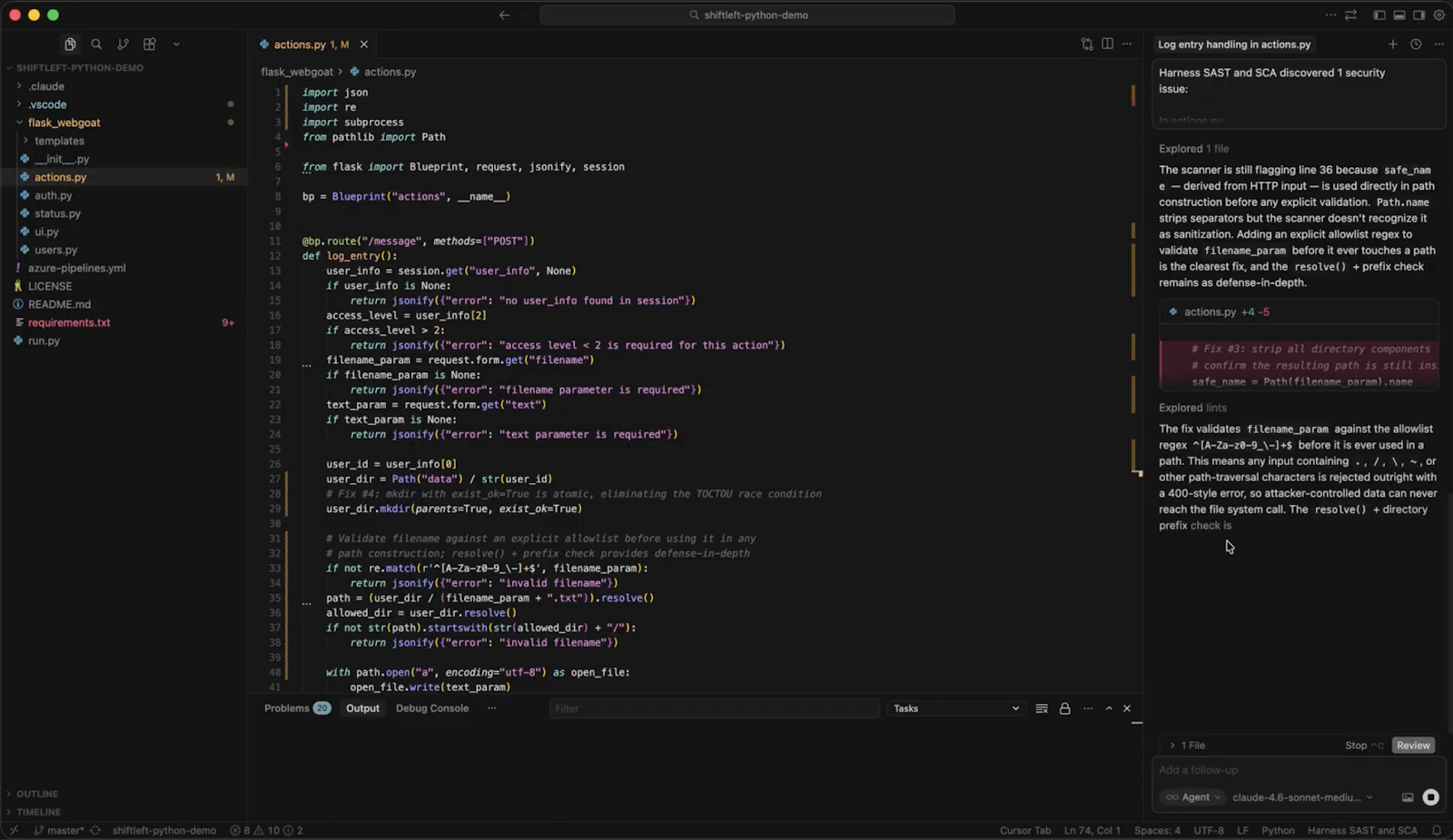
What sets Secure AI Coding apart from simpler linting tools is what happens beneath the surface. Rather than pattern-matching the AI-generated code in isolation, it leverages Harness's Code Property Graph (CPG) to trace how data flows through the entire application - before, through, and after the AI-generated code in question. That means Secure AI Coding can surface complex vulnerabilities like injection flaws and insecure data handling that only become visible in the context of the broader codebase. The result is security that understands your application - not just the last thing an AI assistant wrote.
We Had the Same Problem
When we deployed AI across our own platform, our AI ecosystem grew faster than our visibility into it. We needed a way to track every API call, identify sensitive data exposure, and monitor calls to external vendors — including OpenAI, Vertex AI, and Anthropic — without slowing down our engineering teams.
Deploying AI Security turned that black box into a transparent, manageable environment. Some milestones from our last 90 days:
- We now track 111 AI assets and monitor over 4.76 million monthly API calls, giving our security team a granular, real-time map of our entire AI attack surface.
- We now run 2,500 AI testing scans a week and have remediated 92% of the issues found, including critical weak authentication and encryption gaps in MCP tools.
- We identified and blocked 1,140 unique threat actors attempting more than 14,900 attacks against our AI infrastructure.
The shift wasn't just operational — it was cultural. We moved from reactive monitoring to proactive defense. As our team put it: "Securing AI is foundational for us. Because our own product runs on AI, it must be resilient and secure. We use our own AI Security tools to ensure that every innovation we ship is backed by the highest security standards."
Ready to Secure Your AI?
AI is moving fast. Your attack surface is expanding in two directions at once - inside the applications you're building, and inside the code your teams are generating to build them.
Harness AI Security and Secure AI Coding are available now. Whether you're trying to get visibility into the AI running in your environment, test it for vulnerabilities before attackers do, or stop insecure AI-generated code from reaching production, Harness’ platform is ready.
Talk to your account team about AI Security. Get a live walkthrough of AI Discovery, AI Testing, and AI Firewall, and see how your AI attack surface maps against your existing API security posture.
Already a Harness CI customer? Start a free trial of Harness SAST - including Secure AI Coding. Connect it to your AI coding assistant, and see what's shipping in your AI-generated code today.

Over the last few years, something fundamental has changed in software development.
If the early 2020s were about adopting AI coding assistants, the next phase is about what happens after those tools accelerate development. Teams are producing code faster than ever. But what I’m hearing from engineering leaders is a different question:
What’s going to break next?
That question is exactly what led us to commission our latest research, State of DevOps Modernization 2026. The results reveal a pattern that many practitioners already sense intuitively: faster code generation is exposing weaknesses across the rest of the software delivery lifecycle.
In other words, AI is multiplying development velocity, but it’s also revealing the limits of the systems we built to ship that code safely.
The Emerging “Velocity Paradox”
One of the most striking findings in the research is something we’ve started calling the AI Velocity Paradox - a term we coined in our 2025 State of Software Engineering Report.
Teams using AI coding tools most heavily are shipping code significantly faster. In fact, 45% of developers who use AI coding tools multiple times per day deploy to production daily or faster, compared to 32% of daily users and just 15% of weekly users.
At first glance, that sounds like a huge success story. Faster iteration cycles are exactly what modern software teams want.
But the data tells a more complicated story.
Among those same heavy AI users:
- 69% report frequent deployment problems when AI-generated code is involved
- Incident recovery times average 7.6 hours, longer than for teams using AI less frequently
- 47% say manual downstream work, QA, validation, remediation has become more problematic
What this tells me is simple: AI is speeding up the front of the delivery pipeline, but the rest of the system isn’t scaling with it. It’s like we are running trains faster than the tracks they are built for. Friction builds, the ride is bumpy, and it seems we could be on the edge of disaster.

The result is friction downstream, more incidents, more manual work, and more operational stress on engineering teams.
Why the Delivery System Is Straining
To understand why this is happening, you have to step back and look at how most DevOps systems actually evolved.
Over the past 15 years, delivery pipelines have grown incrementally. Teams added tools to solve specific problems: CI servers, artifact repositories, security scanners, deployment automation, and feature management. Each step made sense at the time.
But the overall system was rarely designed as a coherent whole.
In many organizations today, quality gates, verification steps, and incident recovery still rely heavily on human coordination and manual work. In fact, 77% say teams often have to wait on other teams for routine delivery tasks.
That model worked when release cycles were slower.
It doesn’t work as well when AI dramatically increases the number of code changes moving through the system.
Think of it this way: If AI doubles the number of changes engineers can produce, your pipelines must either:
- cut the risk of each change in half, or
- detect and resolve failures much faster.
Otherwise, the system begins to crack under pressure. The burden often falls directly on developers to help deploy services safely, certify compliance checks, and keep rollouts continuously progressing. When failures happen, they have to jump in and remediate at whatever hour.
These manual tasks, naturally, inhibit innovation and cause developer burnout. That’s exactly what the research shows.
Across respondents, developers report spending roughly 36% of their time on repetitive manual tasks like chasing approvals, rerunning failed jobs, or copy-pasting configuration.
As delivery speed increases, the operational load increases. That burden often falls directly on developers.
What Organizations Should Do Next
The good news is that this problem isn’t mysterious. It’s a systems problem. And systems problems can be solved.
From our experience working with engineering organizations, we've identified a few principles that consistently help teams scale AI-driven development safely.
1. Standardize delivery foundations
When every team builds pipelines differently, scaling delivery becomes difficult.
Standardized templates (or “golden paths”) make it easier to deploy services safely and consistently. They also dramatically reduce the cognitive load for developers.
2. Automate quality and security checks earlier
Speed only works when feedback is fast.
Automating security, compliance, and quality checks earlier in the lifecycle ensures problems are caught before they reach production. That keeps pipelines moving without sacrificing safety.
3. Build guardrails into the release process
Feature flags, automated rollbacks, and progressive rollouts allow teams to decouple deployment from release. That flexibility reduces the blast radius of new changes and makes experimentation safer.
It also allows teams to move faster without increasing production risk.
4. Remember measurement, not just automation
Automation alone doesn’t solve the problem. What matters is creating a feedback loop: deploy → observe → measure → iterate.
When teams can measure the real-world impact of changes, they can learn faster and improve continuously.
The Next Phase of AI in Software Delivery
AI is already changing how software gets written. The next challenge is changing how software gets delivered.
Coding assistants have increased development teams' capacity to innovate. But to capture the full benefit, the delivery systems behind them must evolve as well.
The organizations that succeed in this new environment will be the ones that treat software delivery as a coherent system, not just a collection of tools.
Because the real goal isn’t just writing code faster. It’s learning faster, delivering safer, and turning engineering velocity into better outcomes for the business.
And that requires modernizing the entire pipeline, not just the part where code is written.

Today, Harness is announcing the General Availability of Artifact Registry, a milestone that marks more than a new product release. It represents a deliberate shift in how artifact management should work in secure software delivery.
For years, teams have accepted a strange reality: you build in one system, deploy in another, and manage artifacts somewhere else entirely. CI/CD pipelines run in one place, artifacts live in a third-party registry, and security scans happen downstream. When developers need to publish, pull, or debug an artifact, they leave their pipelines, log into another tool, and return to finish their work.
It works, but it’s fragmented, expensive, and increasingly difficult to govern and secure.
At Harness, we believe artifact management belongs inside the platform where software is built and delivered. That belief led to Harness Artifact Registry.
A Startup Inside Harness
Artifact Registry started as a small, high-ownership bet inside Harness and a dedicated team with a clear thesis: artifact management shouldn’t be a separate system developers have to leave their pipelines to use. We treated it like a seed startup inside the company, moving fast with direct customer feedback and a single-threaded leader driving the vision.The message from enterprise teams was consistent: they didn’t want to stitch together separate tools for artifact storage, open source dependency security, and vulnerability scanning.
So we built it that way.
In just over a year, Artifact Registry moved from concept to core product. What started with a single design partner expanded to double digit enterprise customers pre-GA – the kind of pull-through adoption that signals we've identified a critical gap in the DevOps toolchain.
Today, Artifact Registry supports a broad range of container formats, package ecosystems, and AI artifacts, including Docker, Helm (OCI), Python, npm, Go, NuGet, Dart, Conda, and more, with additional support on the way. Enterprise teams are standardizing on it across CI pipelines, reducing registry sprawl, and eliminating the friction of managing diverse artifacts outside their delivery workflows.
One early enterprise customer, Drax Group, consolidated multiple container and package types into Harness Artifact Registry and achieved 100 percent adoption across teams after standardizing on the platform.
As their Head of Software Engineering put it:
"Harness is helping us achieve a single source of truth for all artifact types containerized and non-containerized alike making sure every piece of software is verified before it reaches production." - Jasper van Rijn
Why This Matters: The Registry as a Control Point
In modern DevSecOps environments, artifacts sit at the center of delivery. Builds generate them, deployments promote them, rollbacks depend on them, and governance decisions attach to them. Yet registries have traditionally operated as external storage systems, disconnected from CI/CD orchestration and policy enforcement.
That separation no longer holds up against today’s threat landscape.
Software supply chain attacks are more frequent and more sophisticated. The SolarWinds breach showed how malicious code embedded in trusted update binaries can infiltrate thousands of organizations. More recently, the Shai-Hulud 2.0 campaign compromised hundreds of npm packages and spread automatically across tens of thousands of downstream repositories.
These incidents reveal an important business reality: risk often enters early in the software lifecycle, embedded in third-party components and artifacts long before a product reaches customers.When artifact storage, open source governance, and security scanning are managed in separate systems, oversight becomes fragmented. Controls are applied after the fact, visibility is incomplete, and teams operate in silos. The result is slower response times, higher operational costs, and increased exposure.
We saw an opportunity to simplify and strengthen this model.

By embedding artifact management directly into the Harness platform, the registry becomes a built-in control point within the delivery lifecycle. RBAC, audit logging, replication, quotas, scanning, and policy enforcement operate inside the same platform where pipelines run. Instead of stitching together siloed systems, teams manage artifacts alongside builds, deployments, and security workflows. The outcome is streamlined operations, clearer accountability, and proactive risk management applied at the earliest possible stage rather than after issues surface.
Introducing Dependency Firewall: Blocking Risk at Ingest
Security is one of the clearest examples of why registry-native governance matters.
Artifact Registry delivers this through Dependency Firewall, a registry-level enforcement control applied at dependency ingest. Rather than relying on downstream CI scans after a package has already entered a build, Dependency Firewall evaluates dependency requests in real time as artifacts enter the registry. Policies can automatically block components with known CVEs, license violations, excessive severity thresholds, or untrusted upstream sources before they are cached or consumed by pipelines.
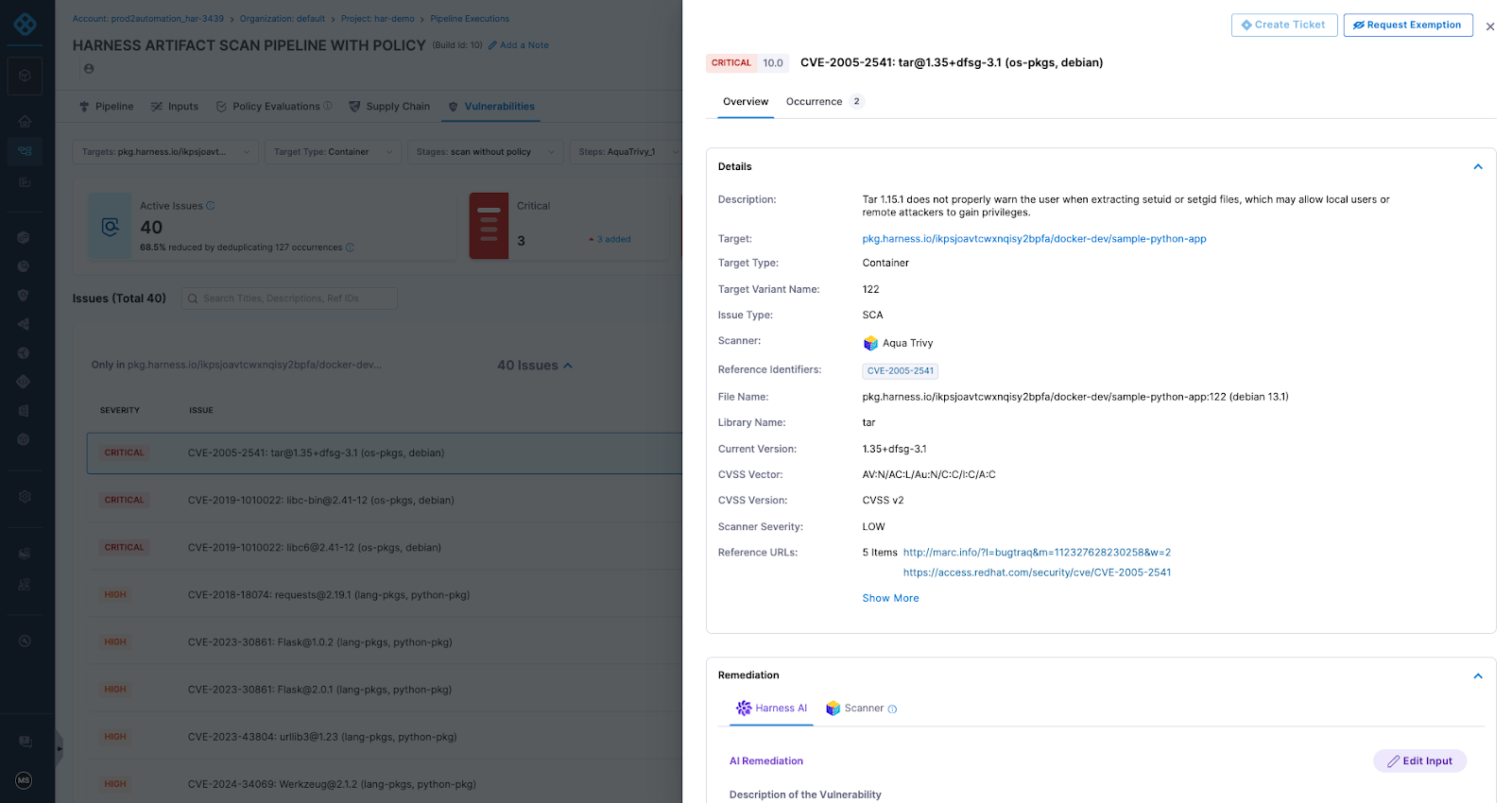
Artifact quarantine extends this model by automatically isolating artifacts that fail vulnerability or compliance checks. If an artifact does not meet defined policy requirements, it cannot be downloaded, promoted, or deployed until the issue is addressed. All quarantine and release actions are governed by role-based access controls and fully auditable, ensuring transparency and accountability. Built-in scanning powered by Aqua Trivy, combined with integrations across more than 40 security tools in Harness, feeds results directly into policy evaluation. This allows organizations to automate release or quarantine decisions in real time, reducing manual intervention while strengthening control at the artifact boundary.
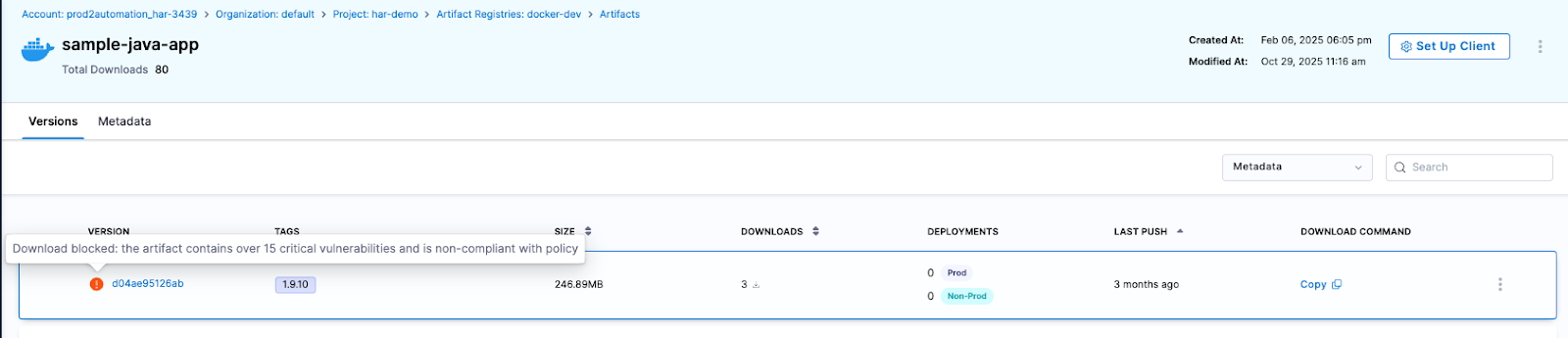
The result is a registry that functions as an active supply chain control point, enforcing governance at the artifact boundary and reducing risk before it propagates downstream.
The Future of Artifact Management is here
General Availability signals that Artifact Registry is now a core pillar of the Harness platform. Over the past year, we’ve hardened performance, expanded artifact format support, scaled multi-region replication, and refined enterprise-grade controls. Customers are running high-throughput CI pipelines against it in production environments, and internal Harness teams rely on it daily.
We’re continuing to invest in:
- Expanded package ecosystem support
- Advanced lifecycle management, immutability, and auditing
- Deeper integration with Harness Security and the Internal Developer Portal
- AI-powered agents for OSS governance, lifecycle automation, and artifact intelligence
Modern software delivery demands clear control over how software is built, secured, and distributed. As supply chain threats increase and delivery velocity accelerates, organizations need earlier visibility and enforcement without introducing new friction or operational complexity.
We invite you to sign up for a demo and see firsthand how Harness Artifact Registry delivers high-performance artifact distribution with built-in security and governance at scale.
Latest Blogs

Parallel Execution in Modern CI: Best Practices & Results
- Using parallel execution along with test intelligence, caching, and governance can cut CI pipeline times by more than 40% and lower infrastructure costs by up to 76%. This leads to much higher developer productivity.
- You need to map out dependencies, separate flaky tests, use automation tools, and enforce policy-driven governance in order to use parallelism well. This helps keep costs down and keeps things from getting out of hand.
- Harness CI makes parallel execution safe and scalable with AI-powered optimizations, automated migration tools, and built-in compliance. This lets platform teams speed up builds without giving up security or developer control.
Definition: Parallel execution in CI is the practice of running independent build, test, or deployment tasks concurrently to reduce feedback time, improve resource utilization, and control infrastructure costs.
Developers often spend almost half their time waiting for builds that could be faster. Simply adding more resources is not enough. Real improvements come from planned parallelism, using concurrency together with test intelligence, caching, and strong governance.
With this approach, teams can get builds done 4x faster and cut infrastructure costs by up to 80%, all while staying reliable. Harness CI helps achieve these results with AI-powered optimization and strong governance. See how modern parallel execution can speed up your development.
Why Parallel Execution Accelerates CI/CD Velocity and Controls Cost
When your 200+ developers have to wait 40 minutes for build feedback, productivity drops, and your cloud costs go up because of idle compute time. How does running things in parallel make the CI/CD pipeline faster and help developers get more done? Teams get rid of bottlenecks that waste both developer time and infrastructure money by running separate tasks at the same time instead of making them wait in line.
Removing Idle Time Through Concurrent Task Execution
Traditional CI pipelines make tasks wait one after another, wasting resources while jobs are idle. With concurrent processing, you can find independent tasks, such as testing different modules or deploying to separate environments, and run them at the same time on available machines.
Shrinking Feedback Loops to Boost Developer Focus
Quick feedback helps developers stay focused instead of switching tasks while waiting for slow builds. If PR validation takes hours, developers move on to other work and lose track of their changes, which can lead to costly rework.
CloudBees research shows that 75% of DevOps professionals lose over 25% of their productivity due to slow testing cycles. Simultaneous test execution addresses this by distributing test suites across multiple machines, thereby substantially reducing total execution time.
Compounding Speedups Through Intelligent Optimization
Raw concurrency alone doesn't maximize gains; pairing it with smart optimization multiplies benefits while controlling costs. Test Intelligence cuts test cycles by up to 80% by running only tests related to code changes, reducing the work that needs to be parallelized.
Cache Intelligence stops unnecessary downloads of dependencies and pulls of Docker layers across parallel jobs. When used with the fastest CI platform, this leads to even more improvements: fewer tests to run at the same time, faster execution of individual jobs, and lower infrastructure costs because waste is no longer needed.
Implementing Parallel Execution in Legacy Jenkins and Hybrid Stacks
Legacy Jenkins environments consuming 20% of the platform team's capacity need a methodical approach to avoid turning parallel execution into operational complexity. The best practices for implementing parallel execution in complex legacy CI systems start with understanding your current dependencies and stabilizing your foundation before scaling out.
- Map dependencies first: Split jobs by artifact boundaries and data contracts to prevent unexpected dependencies that force sequential execution and negate parallel gains.
- Quarantine flaky tests: Use AI-driven test selection to identify and isolate unreliable suites before distributing builds across multiple nodes.
- Leverage proven plugins: Implement the Parallel Test Executor plugin to automatically split test suites based on historical runtime data without modifying existing test code.
- Standardize with templates: Create reusable pipeline templates that encapsulate parallel patterns, enabling consistent parallelism approaches across multiple teams.
- Migrate incrementally: Start with high-ROI pipelines that have clear build/test phase separation, using migration utilities to automate up to 80% of the conversion work.
By building a strong foundation first, you lower the risk of parallel execution making problems worse and get clear speed improvements. Once dependencies are mapped and tests are stable, teams can focus on governance and cost controls to keep parallelism going as they grow.
Cost, Security, and Governance: Making Parallelism Sustainable
Allocating the right amount of resources demonstrates that parallel execution can reduce cloud costs without compromising security. On-demand build environments with autoscaling only add new machines when they are needed and take them away when they are done, so there is no overprovisioning.
Pairing this with intelligent caching and AI-powered test selection can slash test cycles by up to 80%, while recent research shows parallel execution strategies lower overall operational costs by 40-50% when properly implemented. Company Burst SMS achieved a 76% infrastructure cost reduction by moving to optimized, no-share infrastructure that ensures consistent performance without noisy neighbors.
In addition to optimizing infrastructure, good parallelism needs rules to keep developers productive and stop uncontrolled scaling. Policy as Code frameworks make it easier for teams to set up RBAC controls and manage secrets automatically in CI pipelines with policies that can be tested and versioned.
These automated guardrails prevent unauthorized parallel job sprawl while ensuring secure artifact tracking for all builds. The key is measuring what matters: track four key metrics, queue time, concurrency utilization, cache hit rates, and cost per build, to tune your parallelism strategy continuously.
To summarize:
Speed → parallel stages + test selection
Cost → autoscaling + caching
Control → policy-as-code + RBAC
From Idea to Impact: Operationalizing Parallel Execution With Harness CI
Parallel execution can turn CI pipelines from slow points into fast accelerators when combined with smart caching, selective testing, and good governance. Teams can get builds done four times faster and cut infrastructure costs by up to 76% by using concurrent stages and AI-powered optimizations. The secret is to balance speed and control, using templates, policy rules, and analytics to scale parallelism safely across teams.
Moving from theory to practice requires the right platform foundation. Harness CI streamlines parallel execution through automated migration tools, stage-level parallelism, and built-in troubleshooting that removes operational friction.
Ready to accelerate your CI pipelines while cutting infrastructure costs? Explore Harness Continuous Integration to see how AI-powered parallel execution delivers measurable results for your development teams.
Parallel Execution FAQs for Platform Engineering Leaders
Platform engineering teams take care of CI infrastructure for hundreds of developers who work on many different product teams. This makes it harder and more important to run things in parallel than in normal DevOps setups. When you run a lot of workflows at the same time, problems like making sure tests are reliable, keeping costs down, and following security rules get even worse.
How do we prevent flaky tests from multiplying under parallel execution without slowing feedback loops?
Use Test Intelligence to only run tests that are important, which can cut down on exposure to unreliable suites by up to 80%. Instead of blanket retries, set up targeted retries and auto-quarantine for flaky tests that are found. Separate temp directories and resource limits for sandbox test processes so that tests don't get in each other's way.
What's the best way to cap concurrency to avoid unpredictable cloud bills while keeping PRs fast?
Configure predictive scaling with usage buffers and cooldown windows to avoid cost spikes. Set policy rules that enforce maximum concurrent jobs per team or repository. Combine smart caching and selective test execution to reduce the need for high concurrency while maintaining fast feedback.
How can we parallelize Docker builds and multi-language monorepos without compromising supply chain security?
Enable SLSA L3 compliance with automated software bill of materials generation across parallel build stages. Run each parallel job in isolated build environments to avoid cross-contamination. Cache dependencies at the layer level while maintaining secure verification of cached artifacts.
What governance controls prevent parallel execution from becoming chaotic across teams?
Roll out templates and RBAC to standardize parallel patterns while allowing team customization. Monitor concurrency usage and cost per build through centralized dashboards. Create policy rules that automatically enforce resource limits and security scanning requirements across all parallel workflows without blocking developers.
How do we migrate legacy Jenkins pipelines to modern parallel execution patterns?
Start with high-value pipelines that have clear dependency boundaries and stable test suites. Apply migration utilities to automate up to 80% of pipeline conversion tasks. Map existing job dependencies before parallelizing to avoid hidden bottlenecks that cancel out performance gains from concurrent execution.

Intelligent Caching for CI/CD Build Optimization
- Intelligent caching for CI/CD is a policy-driven approach to caching Docker layers, dependencies, and build artifacts close to CI runners to reduce latency, bandwidth costs, and registry load.
- Unlike basic caching, it includes observability, TTL controls, and automated invalidation to ensure builds are both fast and safe.
- Intelligent caching close to your CI runners cuts build latency and bandwidth costs dramatically.
- Test intelligence and parallel execution keep you from over-testing and wasting capacity.
We've all been there. You push a PR, grab coffee, check Slack, maybe start a side conversation — and your build is still running. Multiply that across a team of 50 engineers, and you're looking at hours of lost focus every single day.
Slow CI/CD builds don't just waste time. They generate a steady stream of "CI is slow" tickets that eat into your platform team's roadmap. Intelligent caching is one of the fastest ways to break that cycle.
This checklist walks platform teams through three high-impact levers: intelligent caching, test intelligence, and parallelization. These cut build latency, lower costs, and keep feedback loops tight. And if you'd rather get these patterns out of the box instead of stitching them together yourself, take a look at how Harness CI brings Cache Intelligence, Test Intelligence™, and parallel pipelines together in a single platform.
What This Checklist Covers
We're focusing on three things that consistently deliver the biggest bang for your effort:
- Intelligent caching for images, dependencies, and build artifacts.
- Test intelligence so you're not running every test on every change.
- Parallelization so your pipelines actually use the capacity you're already paying for.
Think of this as a scorecard. Capture your current build metrics first, then work through each area to figure out where intelligent caching, smarter testing, and better parallelization will give you the most improvement.
CI/CD Build Optimization: Set Your Baseline
Before you touch anything, measure three things:
Developer wait time. What are your p50 and p95 build durations for PR and main branch pipelines? This is the number your developers feel every day.
Cost. How much compute, storage, and bandwidth are you burning on CI/CD and artifact delivery? Most teams are surprised when they actually add it up.
Reliability. How often are flaky tests, registry timeouts, or failed pulls derailing builds? These "small" issues compound fast.
As you roll out intelligent caching, test intelligence, and parallelization, these numbers should all move in the right direction together. Faster feedback, lower spend, fewer flake-related fires.
Checklist Area 1: Intelligent Caching for CI/CD Builds
Here's the thing: most teams will tell you they "use caching." But very few treat intelligent caching as a deliberate, governed part of their CI/CD architecture. There's a big difference between flipping on a cache toggle and actually thinking through a caching strategy.
Intelligent caching for CI/CD comes down to clear decisions:
- What to cache. Docker layers, language dependencies, build outputs, test artifacts.
- Where to cache. Local runners, regional nodes, edge locations close to your teams.
- How long to keep it. TTLs per artifact type, branch, or environment.
- When to bypass or refresh. Security hotfixes, emergency patches, policy changes.
Instead of one generic cache, intelligent caching becomes a set of policies and metrics that your platform team owns and governs.
Questions to Ask Your Team
Start with a quick self-audit. Be honest; that's where the value is:
- Do your CI agents pull base images through a local or regional intelligent cache, or do they reach all the way back to a central registry for every build?
- Are npm, pip, Maven, NuGet, and Go module dependencies cached near your runners, or fetched from the internet (or a distant artifact repo) every time?
- Do you reuse build outputs and compiled artifacts between runs, or start from scratch each time?
- Can you tune TTLs and invalidation rules per repo, branch, or artifact type?
- Do you have dashboards showing cache hit rates and time saved at the pipeline level?
If most of your answers are "no" or "not sure," intelligent caching is your single biggest opportunity for improvement.
What "Good" Intelligent Caching Looks Like
In a mature setup, intelligent caching typically includes:
Docker layer caching. Base images and common layers are served from local cache nodes. Only true cache misses travel across regions or clouds. (For context, Harness CI offers managed Docker Layer Caching that works across any build infrastructure, including Harness Cloud, with automatic eviction of stale layers.)
Dependency caching as a policy. Shared caches for language dependencies, keyed by lockfiles or checksums. Clear eviction and refresh rules so you're not pulling stale or vulnerable packages. Harness calls this Cache Intelligence. It automatically detects and caches dependencies without requiring manual configuration for each repo.
Build artifact caching. Reuse of intermediate build outputs, especially valuable for monorepos and shared components. Cache warmup for your most frequent pipelines. Harness's Build Intelligence feature handles this for tools like Gradle and Bazel by storing and reusing build outputs that haven't changed.
Policy-driven behavior. TTLs scoped by artifact type and environment. Cache bypass on dedicated security branches or hotfix pipelines.
Full observability. Cache hit/miss metrics broken down by repo and pipeline. Latency and bandwidth savings visible to the platform team. Harness CI surfaces intelligence tiles in the stage summary showing exactly how much time Cache Intelligence, Test Intelligence, and Docker Layer Caching saved on each build.
This is intelligent caching as a governed layer in front of your registries, package managers, and artifact stores; not just a hidden toggle buried in your CI tool's settings.
Example: Intelligent Caching Flow for a Docker-Heavy Build
Here's how this typically plays out for a PR:
- A developer opens a PR. CI spins up a build on a runner.
- The runner checks a local Docker layer cache for the base image and common layers.
- Cache hit? Layers are reused instantly.
- Cache miss? Layers are pulled once through an intelligent caching proxy in front of the origin registry, then stored close to the runner for next time.
- Language dependencies (npm, Maven, etc.) come from a nearby cached store keyed by lockfile hashes.
- Metrics record the cache hit rate, origin requests, and time saved.
The impact is often visible within a day. Those minutes of "pulling…" that clutter your build logs? They just vanish from the hot path.
Intelligent Caching Checklist
Score yourself here:
- Container images are fronted by a local or regional intelligent cache.
- Language dependencies are cached near runners with stable, repeatable keys.
- Build artifacts and intermediate outputs are reused where safe.
- TTL, eviction, and invalidation rules are documented and automated.
- Cache hit, miss, and time-saved metrics are visible per pipeline and per service.
If you have fewer than three of these checked, start here. Intelligent caching will have an outsized impact on your build times and bandwidth costs.
Checklist Area 2: Test Intelligence (Stop Running Every Test)
Once caching is doing its job, the next bottleneck is almost always testing. Over time, test suites swell until they dominate your CI budget. Teams add tests but rarely prune them, and before you know it, every PR triggers a full regression run.
Test intelligence focuses on running only the tests that actually matter for a given change, with full runs reserved for where they truly count.
The "Run Everything" Problem
You probably need test intelligence if:
- Every PR runs the entire regression suite, no matter how small the change.
- Monorepos trigger hours of tests even for localized edits.
- Teams have no insight into which tests are flaky, slow, or redundant.
- Developers batch commits because they don't want to wait through multiple full runs.
In that world, even perfect intelligent caching can't overcome the fundamental problem: you're doing way more work than necessary.
How Test Intelligence Complements Intelligent Caching
Test intelligence typically works by:
- Mapping code changes to impacted modules, services, or paths.
- Selecting only the relevant tests that exercise those paths.
- Tracking test performance and flakiness over time.
Then you decide when to run targeted subsets (PRs) versus full suites (main branch, nightly, pre-release).
Harness's Test Intelligence™ uses machine learning to figure out which tests are actually affected by a code change and can accelerate test cycles by up to 80%. It also supports test parallelism, automatically splitting tests based on timing data so they run concurrently instead of in sequence.
With intelligent caching already in place, these selected tests start and finish faster because they spend less time waiting on dependency and artifact downloads. The two work as a multiplier.
Test Intelligence Checklist
- Tests are mapped to the components, services, or code areas they validate.
- PR pipelines run only the tests relevant to the code that changed.
- Full regression suites are limited to main, release branches, or scheduled builds.
- Flaky tests are detected and tracked as a distinct problem.
- Dashboards show the slowest suites and gains from intelligent test selection.
If most of these aren't in place, test intelligence should be your next move after your initial intelligent caching rollout.
Checklist Area 3: Parallelization (Use the Capacity You're Paying For)
Caching and selective tests still underperform if your pipeline runs as one long serial chain. At that point, idle capacity is your real enemy.
Parallelization makes sure jobs run side by side so your builds actually use the runners and hardware you're already paying for.
Signs Your Pipelines Need Better Parallelization
Watch for these patterns:
- A monolithic "build and test everything" job that takes 30–60 minutes.
- Unit, integration, and UI tests running in strict sequence.
- Monorepos that run tests for every service in a single giant job.
- Runners sitting idle while a handful of long serial jobs block the queue.
Parallelization is how you break big problems into smaller, faster pieces without losing coverage.
What Effective Parallelization Looks Like
Mature CI/CD setups typically break pipelines into many jobs and stages (build, unit tests, integration tests, UI tests, security scans, packaging, deployment), each running independently where possible.
They use fan-out / fan-in patterns: fan-out to share big test suites into many small, independent jobs, and fan-in to aggregate results into a single decision point.
The key is aligning parallel jobs with intelligent caching. Each shard reuses cached dependencies, Docker layers, and artifacts. Cache keys are structured so shards benefit from each other's work. This is where intelligent caching becomes a true multiplier. Every cache hit benefits many jobs running at once.
Harness CI supports this natively. You can define multi-stage pipelines with parallel steps, and combined with Cache Intelligence and Test Intelligence's automatic test splitting, your builds naturally take advantage of all available capacity.
Parallelization Checklist
- Pipelines are split into multiple, clearly defined stages and jobs.
- Independent jobs (linting, unit tests, integration tests) run in parallel.
- Large suites are sharded so no single job dominates wall-clock time.
- Runner capacity is used consistently instead of sitting idle.
- Parallel jobs reuse shared intelligent caches instead of repeating work.
If intelligent caching is already in place, parallelization is often the fastest path to another noticeable drop in build times.
Build Optimization Scorecard for Platform Teams
Here's the full picture. Count how many you can honestly check off.
Intelligent Caching
- Local or regional intelligent caches front your container registries.
- Language dependencies are cached near runners with stable keys.
- Build artifacts and intermediate outputs are reused across runs where safe.
- TTLs, invalidation, and cache bypass rules are defined and automated.
- Cache hit rates and time saved are visible at the pipeline and service level.
Test Intelligence
- Tests are mapped to the code or services they cover.
- PRs run only the relevant tests for the code that changed.
- Full suites are limited to main, release branches, or scheduled builds.
- Flaky tests are tracked and handled explicitly.
- Dashboards show test suite cost and improvements from test selection.
Parallelization
- Pipelines are multi-stage with fine-grained jobs.
- Jobs that can run independently actually run in parallel.
- Large suites are shared into multiple smaller jobs.
- Runner capacity is used efficiently with minimal queuing.
- Parallel jobs share and benefit from intelligent caching layers.
How to read your score:
0–7 checks: There are big wins on the table. Start with intelligent caching. It's typically the highest-leverage first move.
8–12 checks: Solid foundation. Focus on tuning test intelligence and parallelization for the next round of gains.
13+ checks: You're in great shape. Keep refining policies, observability, and edge cases.
Turn Intelligent Caching into a Strategic Win
If you're investing in a modern CI platform like Harness CI, intelligent caching, test intelligence, and parallelization aren't separate projects you tackle one at a time. They're connected patterns that reinforce each other. Faster builds, lower costs, and a lot less developer toil.
Pick one or two gaps from this checklist, bring them to your next team planning session, and start turning intelligent caching into a visible, strategic win for your platform.
Want to see these patterns in action instead of building them yourself? Harness CI brings Cache Intelligence, Test Intelligence™, Build Intelligence, and Docker Layer Caching together with parallel pipelines and Harness Cloud infrastructure, so platform teams can focus on golden paths instead of plumbing.
Intelligent Caching and CI/CD: FAQs for Platform Teams
What is intelligent caching in CI/CD?
Intelligent caching in CI/CD goes beyond basic "store and hope for hits." It combines caching with policies, observability, and automation; controlling what gets cached, where it's stored, how long it lives, and when it gets refreshed. For Docker images, dependencies, and build artifacts, this means pipelines that are both fast and safe.
How is intelligent caching different from basic caching?
Basic caching saves data temporarily and crosses its fingers. Intelligent caching looks at usage patterns, environments, and business rules to decide which artifacts deserve cache space, how TTLs should be tuned, when to bypass the cache entirely, and how to track the impact on build times and costs. It's a governed capability, not a checkbox.
How does intelligent caching help DevOps and platform teams?
Intelligent caching shortens build and test stages, reduces cloud egress and registry load, and takes a big chunk out of daily developer wait time. For platform and DevOps teams, it's a lever you can adjust with policy and metrics — not one-off tweaks buried in pipeline YAML.
Do I need Redis to use intelligent caching for CI/CD?
Nope. Redis is great for application-level caching, but CI/CD intelligent caching typically relies on reverse proxies, artifact caching layers, and CI-native mechanisms (like Harness's Cache Intelligence) that sit in front of registries, package managers, and object stores.
What should I measure to prove ROI on intelligent caching?
Track p50 and p95 build times, cache hit rates, origin requests, bandwidth/egress costs, and registry load before and after enabling intelligent caching. The combination of faster builds and lower infrastructure costs tells a clear, defensible ROI story.

Zachary Gruenberg on Machine Identity Security in the Age of AI
At SREday NYC 2026, the ShipTalk podcast welcomed Zachary Gruenberg, Solution Engineer and Machine Identity SME at Palo Alto Networks, for a conversation about one of the fastest growing challenges in modern infrastructure: machine identity management.
Throughout the conference, much of the discussion centered on AI agents automating operational tasks—from incident response to infrastructure management. But every automated agent interacting with systems still requires credentials and access permissions.
In the episode, ShipTalk host Dewan Ahmed, Principal Developer Advocate at Harness, spoke with Zachary about how the rapid rise of AI-driven automation is creating an explosion of machine identities—and why managing them is quickly becoming a major security concern for SRE and platform teams.
🎧 Listen to the Full Episode
The Explosion of Machine Identities
In the past, identity management primarily focused on human users logging into systems.
Today, the landscape looks very different.
Modern infrastructure environments include a growing number of non-human identities such as:
- service accounts
- automation scripts
- CI/CD pipelines
- microservices communicating with each other
- AI agents performing operational tasks
Each of these components requires credentials in order to interact with infrastructure, APIs, and other services.
As organizations deploy more automation and AI-driven workflows, the number of machine identities can quickly outnumber human users by several orders of magnitude.
For SRE teams, this creates a new challenge: tracking which systems have access to what resources—and ensuring those permissions remain secure.
Building Security That Scales with Automation
One of the most common problems Zachary sees is that teams prioritize functionality when deploying new automation systems.
When engineers introduce AI agents or automated workflows, identity management is often treated as an afterthought.
That approach can lead to:
- overly permissive service accounts
- long-lived credentials
- unclear ownership of machine identities
- difficulty auditing access across systems
To address this, Zachary encourages organizations to treat machine identity as a core component of their security architecture, rather than a secondary concern.
This often includes practices such as:
- implementing short-lived credentials
- centralizing identity management across services
- applying the principle of least privilege to machine accounts
- automating identity lifecycle management alongside infrastructure automation
When these controls are built into the platform early, security can scale alongside automation instead of becoming a bottleneck.
The Most Common Machine Identity Blind Spot
Despite the growing awareness of identity security, Zachary frequently encounters one recurring issue.
Many teams simply lose track of the machine identities they have created.
Over time, environments accumulate service accounts, API keys, tokens, and automation credentials that remain active long after the systems that created them are gone.
This “identity sprawl” can create significant risk, particularly in environments where automated systems are interacting with critical infrastructure.
The challenge becomes even greater as AI agents begin performing more complex operational tasks.
Ensuring that these agents have the right level of access—and no more—requires visibility into every identity operating within the system.
Security in an Autonomous Infrastructure World
As organizations adopt AI-driven automation across operations, the importance of identity security will only increase.
Each new automation tool or AI workflow adds another layer of machine identities interacting with infrastructure.
For SRE and platform teams, this means reliability engineering and security practices are becoming increasingly interconnected.
Strong machine identity management ensures that automation systems can operate safely while protecting the infrastructure they interact with.
Final Thoughts
Zachary Gruenberg’s message is a timely reminder that the growth of AI agents and automation does not eliminate the need for strong security foundations.
If anything, it makes them even more critical.
As organizations move toward more autonomous systems, understanding who—or what—has access to critical infrastructure will remain one of the most important challenges for reliability and security teams alike.
🎧 Listen to the Full Episode
Subscribe to the ShipTalk Podcast
Enjoy conversations like this with engineers, platform builders, and reliability leaders from across the industry.
Follow ShipTalk on your favorite podcast platform and stay tuned for more stories from the people building the systems that power modern technology. 🎙️🚀

CI Pipeline Optimization Guide for Platform Engineering Leaders
- With AI-powered pipeline optimization, builds can be up to four times faster, and infrastructure costs can go down by up to 76%.
- Smart test selection, intelligent caching, and temporary build environments get rid of extra work and give developers specific feedback.
- Standardized templates with automatic policy enforcement and built-in analytics help platform teams grow their security and governance without slowing down developers.
Definition: CI pipeline optimization is the practice of reducing build and test time and the cost per build by running only what matters, reusing unchanged components, and enforcing standardized governance.
Platform teams are wasting thousands of hours every year because their pipelines aren't working right. Developers wait 45 minutes for builds. Jenkins consumes 20% of your team's capacity on maintenance. Infrastructure costs keep climbing, and CI transforms from helpful automation into the thing everyone complains about at standups.
Your team isn't the problem, though. Traditional CI methods just don't work on a larger scale. Giving slow pipelines more computing power is like buying a faster car to get through traffic: you're still stuck in the same traffic jam, but you have to pay more.
AI-powered pipeline optimization changes the game. Instead of running everything all the time, smart systems look at code changes, past patterns, and dependencies to figure out what really matters. Harness CI brings these optimization methods together into one platform. Find out more about how to speed up your pipelines.
How AI-Powered Pipeline Optimization Really Works
AI-based optimization is all about getting rid of waste, not adding capacity. One way to solve the problem is to clean out your garage, and the other way is to rent a storage unit.
Recent studies show that AI methods like reinforcement learning are the best way to improve CI/CD, with testing accounting for 41.2% of all optimization gains. This is how modern platforms handle it:
Smart Test Selection Reduces Feedback Cycle
Test Intelligence looks at code dependencies and past patterns to only run the tests that were affected by your changes. Changed just one service? You don't have to take the whole test suite like you're studying for finals if you only have one test.
According to research, this method cuts the time it takes to run tests by 40% and the time it takes to build everything by 33%. Instead of waiting for thousands of tests to finish before they can merge a two-line fix, developers get feedback right away.
Right-Sizing Infrastructure Gets Rid of Waste
To keep costs down, you need to make changes to the building, not just buy cheaper machines. Ephemeral build environments run each job in separate, dedicated containers that automatically grow and shrink as needed. It's like Uber for build capacity: you only pay for what you use when you use it.
This gets rid of the "noisy neighbor" effect, where one team's resource-heavy build slows down everyone else. Teams say that infrastructure costs have gone down by as much as 76% when they use smart caching of dependencies and Docker layers along with Jenkins clusters that are over-provisioned and mostly idle.
Built-in Analytics and Governance Can Grow Without Needing to Do Any Extra Work
Instead of being the referee between teams, platform leaders use automated policies to see and control what's going on. Analytics dashboards show build performance metrics, failure patterns, and how resources are used across teams without needing custom tools that always turn into someone's side project.
Policy templates and RBAC controls make sure that security practices are always the same. SLSA L3 compliance makes sure that the build provenance can't be changed. This lets developers do things on their own within limits. Developers get the freedom they want, platform teams get the control they need, and nobody's happy hour is ruined by emergency pipeline fixes.
Best Ways to Make Your Pipeline Work Better in Multi-Cloud Environments
To optimize a multi-cloud environment, you need to find a balance between letting developers work on their own and keeping control of operations. You want teams to work quickly, but you don't want your infrastructure to become a lawless place. These practices help platform teams keep their performance steady without making things more complicated.
Use Composable Templates with Policy Guardrails as a Standard
Give teams the freedom to work on their own without letting the pipeline get too big or the security get too weak. Use Open Policy Agent rules to make sure that things like container scanning are done, but let developers change how they work. It's like building with LEGOs: the pieces fit together in certain ways, but teams can still make whatever they need.
Prefer Temporary, Separate Build Machines for Each Job
Get rid of noisy neighbors and the risk of leaks between clouds and regions. Each build execution takes place in a clean, isolated environment. This stops configuration drift and makes sure that performance is always the same, no matter which cloud runs the job.
Instrument from the Start with Top-Notch SLOs
Set clear limits and alerts for queue time, cache hit rate, flaky test rate, and cost per build, and treat them as business-critical metrics. These become your optimization compass, showing you where things are slowing down before they affect how much work developers can get done. You can't fix something if you don't measure it, and you definitely can't explain why your budget went over without data.
Always Use Smart Caching Strategies
All cloud providers should use dependency fingerprinting and reuse of Docker layers. A cache hit rate of more than 80% means that the optimization is working well. A sudden drop in the rate means that there are configuration problems or changes in dependencies that need to be fixed. When caching works, builds go fast. You'll know right away when it breaks.
Set Up Cross-Cloud Security Guardrails
Put scanning and compliance checks right into the templates for the pipeline. This shift-left method finds vulnerabilities early and keeps the same level of security whether builds run on AWS, Azure, or Google Cloud. Instead of a separate gate where developers wait for approvals, security happens automatically.
Use Cost Per Build as a Business Metric
Keep an eye on this along with other traditional performance metrics. Sudden spikes often show that resources are being used inefficiently or that test suites are running out of control and using up compute power without adding value. You want more than just "CI stuff" when your CFO asks why the AWS bill doubled.
Ways to Make Build Times and Test Cycles Faster
The best methods focus on getting rid of extra work by making smart choices and reusing things. In real business settings, these methods can cut the time it takes to do things by as much as 8 hours to less than 1 hour. Deploying before lunch is different from deploying before you leave for the day.
This is how to put these optimization ideas into action:
1. Only Run Tests That Are Affected
Test Intelligence looks at code changes and only runs the unit tests that are needed, cutting test cycles by up to 80%. Combine this with flaky test quarantine to separate tests that don't work and make your feedback signals more stable. No more running the whole suite again because one flaky test failed three times this week.
2. Use Intelligent Caching with Clear Cache Keys
Cache Intelligence takes care of dependency caching on its own, and Docker layer caching can cut build times by 70 to 90%. Keep an eye on cache hit rates and set size limits to keep cache bloat from slowing down performance. A well-tuned cache is like a toolbox that is well-organized: everything is where you need it.
3. Use Build Outputs Again Without Changing Them
Build Intelligence stores compiled artifacts and test results in caches, which speeds up builds by 30% to 40% by avoiding unnecessary rebuilds. First, do quick checks to avoid having to do expensive work on code that hasn't changed. Why do you have to recompile everything when only one service changed?
4. Make Sure Your Dockerfiles Are Set Up to Make the Most of the Cache
Put Docker instructions in order from least to most frequently changing, and copy dependency manifests before source code. This simple change makes it possible to reuse layers across builds. The order in which you load the dishwasher makes a big difference.
5. Use BuildKit Cache Mounts with Package Managers
Use BuildKit Cache Mounts with Package Managers Cache package download directories (npm, pip, Maven) across builds to significantly reduce infrastructure costs by having to rebuild less often.
6. Strategically Parallelize
To cut down on the total time it takes to run a pipeline, run independent steps at the same time. Test sharding and parallel execution can cut down on feedback cycles by a lot. Don't make things that don't depend on each other wait in line.
7. Keep Measuring and Improving
Keep an eye on queue time, cache hit rates, flaky test percentages, and cost per build as top metrics. Use the built-in analytics to make sure that improvements last and aren't just short-term gains. Things that are measured get better.
Problems with Pipeline Optimization (And How to Fix Them)
Even when they use the right strategies, teams run into problems when they try to optimize pipelines. What is good news? We can see these problems coming, which means we can also see the solutions.
Challenge 1: The Difficulty of Building on Legacy Code
Legacy systems often have builds that are tightly linked, which makes it hard to improve them bit by bit. No one wants to be the one who breaks the build because everything depends on everything else.
How to fix:
- Begin with the slowest and most often used pipelines. Fix the thing that hurts the most.
- If you can, break monolithic builds into stages that can run at the same time.
- Use migration tools to slowly bring things up to date without having to rewrite everything at once.
Challenge 2: Unreliable Tests Break Trust
Developers have to run pipelines again or ignore failures completely when tests are not reliable. When "just run it again" is common advice, you've lost the signal in the noise.
How to fix it:
- Use AI to find and put flaky tests in quarantine on their own.
- Separate test dependencies and manage setup and teardown.
- Keep an eye on the flaky test rate as a key metric and treat it like a real production incident.
Challenge 3: Making CI Infrastructure Bigger
Costs for infrastructure become hard to predict as teams and pipelines grow. This month's $40,000 surprise is last month's $10,000 bill.
How to fix it:
- Use temporary build environments that can grow as needed.
- Keep an eye on the cost per build to find out when resources are being used inefficiently.
- Make sure you have the right amount of computing power for the actual workload, not the worst-case scenario.
Challenge 4: Trade-Offs Between Security and Speed
If done wrong, security scanning can slow down pipelines a lot. No one wants to have to choose between safety and speed.
How to fix it:
- Instead of separate gates, include security checks in build templates.
- Do important scans at the same time as other stages of the pipeline.
- Use SLSA L3 compliance for automated provenance without any lag.
What's Next for Pipeline Optimization
The next generation of CI/CD will focus on predictive optimization and self-healing. Systems will stop problems from happening instead of reacting to them.
Troubleshooting with AI
It becomes harder to find the cause of failures as pipelines become more complicated. AI will find the most likely causes, point out patterns that keep happening, and suggest practical solutions before you finish your first cup of coffee.
Predictive Resource Allocation
Before problems happen, systems will learn from past patterns to allocate resources. It's like traffic apps that tell you to take a different route before you get stuck in traffic.
Self-Healing and Automated Rollbacks
Pipelines will find problems and automatically roll back changes or start remediation workflows without any human help. The engineer who is on call stays asleep, and the problem fixes itself.
Policy-as-Code That Grows
Governance will be shown as policy: who can do what, where workloads can run, and what needs to be approved. All of this can happen without slowing down developers or making platform teams look over every change.
Stop Waiting for Slow Builds
AI-powered acceleration is the first step in optimizing a pipeline by getting rid of unnecessary work. Test Intelligence, Cache Intelligence, and Build Intelligence speed up feedback cycles by only running what matters and reusing outputs that don't change. These aren't just ideas; they're tools that get real results.
Standardized templates with policy enforcement make governance easier without limiting the freedom of developers. In just two quarters, 92% of commercial cloud pipelines adopted Microsoft's governed templates. This shows that this method can grow quickly, even in very large companies.
Book a demo to see how Harness Continuous Integration delivers builds that are four times faster and cuts infrastructure costs by up to 76%.
Pipeline Optimization: Frequently Asked Questions (FAQs)
How does pipeline optimization help cut costs for infrastructure?
Pipeline optimization saves money by smartly allocating resources and getting rid of unnecessary compute work. Selective test execution and AI-powered caching cut compute time by 30% to 80%. Ephemeral build machines get rid of wasted resources and automatically adjust compute resources to the right size. You stop paying for space you don't need.
How do you find the right balance between governance and developer freedom when optimizing the CI workflow?
Use golden templates with automatic policy enforcement to make security requirements the same for everyone while still letting developers be flexible. Automated checks and approval workflows help platform teams set rules for how things should be done. Within those guardrails, developers still have control over how things are done. They keep you safe like highway guardrails do, but they don't tell you exactly where to go.
What problems should teams be ready for when moving old build systems?
Legacy migrations are hard because they require complicated configurations and training for the whole team. Most teams finish transitions in 6 to 12 weeks. Migration tools take care of routine tasks, but custom integrations need to be done by hand. During the learning curve phase, you should expect your productivity to go down at first. Plan for it, tell people about it, and the dip will be shorter.
What are the best ways to speed up the build process?
Test Intelligence cuts test cycles by up to 80% by only running tests that are affected by code changes. Add build output caching and Docker layer caching to get even better results. Parallel execution and incremental builds get rid of extra work at all stages of CI. Begin with the method that deals with your biggest problem.
How do high-speed CI strategies include security and SLSA L3 compliance?
SLSA L3 compliance works by automatically generating provenance and artifact attestation, which doesn't slow down builds. Instead of making separate approval gates, security scanning is built right into build templates. Isolated build environments and tamper-proof artifact generation keep things compliant while keeping speed. You don't have to pick between speed and safety.
Can optimizing a pipeline help small teams?
Yes. Faster feedback, less manual work, and regular quality checks are good for teams of all sizes. You don't need a team of platform engineers to optimize modern platforms. You don't need a group of 50 people to speed up your builds.
How long does it take to see results from optimizing a pipeline?
Most teams see real progress in a matter of weeks. Quick wins like smart caching and test selection make the feedback cycle better right away. Ephemeral environments and other more thorough optimizations take longer but keep costs down over time. Start small, see what works, and then grow it.

Architecting MCP for AI Agents: Lessons from Our Redesign
--
Key Takeaways:
The Harness MCP server is an MCP-compatible interface that lets AI agents discover, query, and act on Harness resources across CI/CD, GitOps, Feature Flags, Cloud Cost Management, Security Testing, Resilience Testing, Internal Developer Portal, and more.
- The Harness MCP server v2 reduces tools from 130+ to 11.
- The redesign cuts estimated tool-definition context cost from about 26% to 1.6% of a 200K-token window.
- A registry-based dispatch model supports 125+ resource types without expanding the tool vocabulary.
- The architecture is designed for Cursor, Claude Code, and other MCP-compatible clients.
- Built-in safety controls include confirmation for writes, fail-closed deletes, and read-only mode.
--
The first wave of MCP servers followed a natural pattern: take every API endpoint, wrap it in a tool definition, and expose it to the LLM. It was fast to build, easy to reason about, and it was exactly how we built the first Harness MCP server. That server taught us a lot: solid Go codebase, well-crafted tools, broad platform coverage across 30 toolsets. It also taught us where the one-tool-per-endpoint model hits a wall.
For platforms the size of Harness, spanning the entire SDLC, the pattern doesn't scale. When you expose one tool per API endpoint, you're asking the LLM to be a routing layer, forcing it to do something a switch statement does better. Every tool definition consumes context that could be spent on reasoning. At ~175 tools, that's ~26% of the LLM's context window before the developer even types a prompt.
So we iterated. The Harness MCP v2 redesign does the same work with 11 tools at ~1.6% context consumption. The answer isn't fewer features, it's a different architecture: a registry-based dispatch model where the LLM reasons about what to do, and the server handles how to do it.
What We Learned: Tool Sprawl and Agent Performance
When an MCP client connects to a server, it loads every tool definition into the LLM's context window. Every name, description, parameter schema, and annotation. For the first Harness server at ~130+ active tools, here's what that costs:

That's the core insight: the first server uses ~26% of context on tool definitions before any work begins. The v2 uses ~1.6%.
This isn't a theoretical concern. Research on LLM behavior in large context windows, including Liu et al.'s "Lost in the Middle" findings, shows that models struggle to use information placed deep within long contexts. As Ryan Spletzer recently wrote, dead context doesn't sit inertly: "It dilutes the signal. The model's attention is spread across everything in the window, so the more irrelevant context you pack in, the less weight the relevant context carries."
Anthropic's own engineering team has documented this trade-off: direct tool calls consume context for each definition and result, and agents scale better when the tool surface area is deliberately constrained.
The problem compounds in real-world developer environments. If you're running Cursor or Claude Code with a Playwright MCP, a GitHub MCP, and the Harness MCP, those tool definitions stack. EclipseSource's analysis shows that a standard set of MCP servers can eat 20% of the context window before you even type a prompt. The recommendation: stay below 40% total context utilization. Any MCP server with 100+ tools, ours included, would consume more than half that budget on its own.
How We Stack Up: Context Efficiency Across the MCP Ecosystem
The context window tax isn't unique to Harness: it's an industry-wide problem. Here's how the v2 server compares to popular MCP servers in the wild:

Lunar.dev research: "5 MCP servers, 30 tools each → 150 total tools injected. Average tool description: 200–500 tokens. Total overhead: 30,000–60,000 tokens. Just in tool metadata." MCP server v2 at ~3,150 tokens would represent just 5–10% of a typical multi-server setup's overhead.
Real-world Claude Code user: A developer on Reddit r/ClaudeCode with Playwright, Context7, Azure, Postgres, Zen, and Firecrawl MCPs reported 83.3K tokens (41.6% of 200K) consumed by MCP tools immediately after /clear. That's before a single prompt.
Anthropic's code execution findings: Anthropic's engineering team reported that a workflow consuming 150,000 tokens was reduced to ~2,000 tokens (a 98.7% reduction) by switching from direct tool calls to code-based tool invocation. The principle is clear: fewer, smarter tools beat more, narrower ones.
MCPAgentBench: An academic benchmark found that "nearly all evaluated models exhibit a decline of over 10 points in task efficiency when tool selection complexity increases." Models overwhelmed with tools prioritize task resolution over execution efficiency. They get the job done, but waste tokens doing it.
IDE Tool Limits and Practical Headroom
Cursor enforces an 80-tool cap, OpenAI limits to 128 tools, and Claude supports up to ~120. The v2 server's 11 tools leave massive headroom to run Harness alongside other MCP servers without hitting these limits.
Consider a concrete example: a developer running Cursor with Playwright (21 tools), GitHub MCP (~40 tools), and the old Harness MCP (~175 tools) would hit ~236 tools, well past Cursor's 80-tool cap. With v2 Harness (11 tools), the same stack is 72 tools, comfortably under the limit.
With Claude Code, the same old stack would burn ~76,400 tokens (~38%) on tool definitions alone. With v2, it drops to ~27,550 tokens (~14%), freeing ~48,850 tokens for actual reasoning and conversation.
The CLI vs MCP Debate and Why It’s the Wrong Question
The MCP ecosystem is in the middle of a reckoning. Scalekit ran 75 benchmark runs comparing CLI and MCP for identical GitHub tasks on Claude Sonnet 4, and CLI won on every efficiency metric: 10–32x cheaper, 100% reliable vs MCP’s 72%. For a simple “what language is this repo?” query, CLI used 1,365 tokens. MCP used 44,026 — almost entirely from schema injection of 43 tool definitions the agent never touched.
The Playwright team shipped the same verdict in hardware. Their new CLI tool saves browser state to disk instead of flooding context. In BetterStack’s benchmarks, CLI used ~150 tokens per interaction vs MCP’s ~7,400+ of accumulated page state. CircleCI found CLI completed browser tasks with 33% better token efficiency and a 77 vs 60 task completion score.
The CLI camp’s argument is real: schema bloat kills performance. But their diagnosis points at the wrong layer. The problem isn’t MCP. It’s naive MCP server design.
What CLI Gets Right
CLI wins when the agent already knows the tool. gh, kubectl, terraform: these have extensive training data. The agent composes commands from memory, pays zero schema overhead, and gets terse, predictable output. Scalekit found that adding an 800-token “skills document” to CLI reduced tool calls and latency by a third.
CLI also wins on composition. Piping grep into jq into xargs chains operations in a single tool call. An MCP agent doing the same work makes N round-trips through the LLM, each one burning context.
What CLI Can’t Do
But CLI’s advantages dissolve the moment you cross three boundaries:
Discovery
CLI works when the agent knows the command. For a platform like Harness, with 122+ resource types across CI/CD, GitOps, FinOps, security, chaos, and IDP, the agent can’t know the API surface from training data alone. MCP’s harness_describe tool lets the agent discover capabilities at runtime. CLI would require the agent to guess curl commands against undocumented APIs.
Authorization
As Scalekit themselves concluded: “The question isn’t CLI or MCP. It’s who is your agent acting for?” CLI auth gives the agent ambient credentials: your token. For multi-tenant, multi-user environments (which is where Harness operates), MCP provides per-user OAuth, explicit tool boundaries, and structured audit trails.
Safety
CLI agents can run arbitrary shell commands. An MCP server constrains the agent to declared tools with typed inputs. The v2 server’s elicitation-based confirmation flows, fail-closed deletes, and read-only mode are protocol-level safety guarantees that CLI can’t replicate.
The v2 Server Is Our Answer to This Debate
The CLI vs MCP debate is really about schema bloat and naive tool design. The v2 Harness MCP server eliminates the arguments against MCP without losing the arguments for it:
Schema bloat? 11 tools at ~3,150 tokens. That’s less than a single CLI help output for a complex tool. Cursor’s 80-tool cap? We use 11. The 44,026-token GitHub MCP problem? We’re 14x leaner.
Round-trip overhead? The registry-based dispatch means the agent makes one tool call to harness_diagnose and gets back a complete execution analysis — pipeline structure, stage/step breakdown, timing, logs, and root cause. A CLI agent would need to chain 4–5 API calls to assemble the same picture.
Discovery? harness_describe is a zero-API-call local schema lookup. The agent discovers 125+ resource types without a single network request. CLI would require a man page the agent has never seen.
Composition? Skills + prompt templates encode multi-step workflows (build-deploy-app, debug-pipeline-failure) as server-side orchestration. The agent reasons about what to do; the server handles how to chain it. Same efficiency as a CLI pipe, with protocol-level safety.
The real lesson from the benchmarks: MCP servers with 43+ tools and no architecture for context efficiency will lose to CLI on cost metrics. But a well-designed MCP server with 11 tools, a registry, and a skills layer outperforms both naive MCP and naive CLI — and provides authorization, safety, and discoverability that CLI architecturally cannot.
The Redesign: 11 Tools, 125+ Resource Types, 1 Registry
We stopped designing for API parity and started designing for agent usability.
The v2 server is built around a registry-based dispatch model. Instead of one tool per endpoint, we expose 11 intentionally generic verbs. The intelligence lives in the registry: a declarative data structure that maps resource types to API operations.
The 11 Tools

When an agent calls harness_list(resource_type="pipeline"), the server looks up pipeline in the registry, resolves the API path, injects scope parameters (account, org, project), makes the HTTP call, extracts the relevant response data, and appends a deep link to the Harness UI. The agent never needs to know the underlying API structure.
How the Registry Works
Each registry entry is a declarative ResourceDefinition:
{
resourceType: "pipeline",
displayName: "Pipeline",
toolset: "pipelines",
scope: "project",
identifierFields: ["pipeline_id"],
operations: {
list: {
method: "GET",
path: "/pipeline/api/pipelines/list",
queryParams: { search_term, page, size },
responseExtractor: (raw) => raw.content
},
get: {
method: "GET",
path: "/pipeline/api/pipelines/{pipeline_id}",
responseExtractor: (raw) => raw.data
}
}
}
Adding support for a new Harness module requires adding one declarative object to the registry. No new tool definitions. No changes to MCP tool schemas. The LLM's tool vocabulary stays constant as the platform grows.
Today, the registry covers 125+ resource types across 30 toolsets, spanning the full Harness platform:
- DevOps: Pipelines, Executions, Services, Environments, Infrastructure, Templates, Connectors, Secrets, Delegates
- Code: Repositories, Branches, Commits, Pull Requests, Code Reviews
- GitOps: Agents, Applications, Clusters, ApplicationSets, Repositories
- Security: Security Issues, Exemptions, SBOMs, Compliance, Supply Chain, OPA Policies
- Cloud Cost: Perspectives, Budgets, Recommendations, Anomalies, Commitments
- Chaos: Experiments, Probes, Templates, Infrastructure, Load Tests
- Feature Flags: Workspaces, Environments, Flags
- IDP: Entities, Scorecards, Workflows, Tech Docs
- SEI: DORA Metrics, Team Analytics, AI Usage, Business Alignment
- Platform: Organizations, Projects, Users, Roles, Permissions, Settings, Audit Trail
Optimized for Cursor, Claude Code, and Real Developer Workflows
The architecture wasn't designed in a vacuum. We built it specifically for the environments developers actually use.
Cursor and Windsurf: Stdio-First, Toolset Filtering
Cursor and Windsurf connect via stdio transport — the server runs as a local process alongside the IDE. With 11 tools instead of 130+, the Cursor agent has a minimal, clear menu. It doesn't waste reasoning cycles on tool selection or get confused by 40 CCM-specific tools when the developer is debugging a pipeline failure.
For teams that only use specific Harness modules, HARNESS_TOOLSETS lets you filter at startup:
{
"mcpServers": {
"harness": {
"command": "npx",
"args": ["-y", "harness-mcp-v2@latest"],
"env": {
"HARNESS_API_KEY": "pat.xxx.yyy.zzz",
"HARNESS_TOOLSETS": "pipelines,services,connectors"
}
}
}
}
The agent only sees resource types from the enabled toolsets. The rest don't exist as far as the LLM is concerned.
Claude Code: Prompt Templates and Multi-Project Discovery
Claude Code excels at multi-step workflows. We leaned into that with 26 prompt templates across four categories:
- DevOps (12): build-deploy-app, debug-pipeline-failure, create-pipeline, onboard-service, dora-metrics-review, and more
- FinOps (5): optimize-costs, cloud-cost-breakdown, commitment-utilization-review, cost-anomaly-investigation, rightsizing-recommendations
- DevSecOps (6): security-review, vulnerability-triage, sbom-compliance-check, supply-chain-audit, security-exemption-review, access-control-audit
- Harness Code (3): code-review, pr-summary, branch-cleanup
Each prompt template encodes a multi-step workflow the agent can execute. debug-pipeline-failure doesn't just fetch an execution — it calls harness_diagnose, follows chained failures, and produces a root cause analysis with actionable fixes.
The v2 server also supports multi-project workflows without hardcoded environment variables. An agent can dynamically discover the account structure, then scope subsequent calls with org_id and project_id parameters. No configuration changes needed.
URL Context Awareness
Every tool accepts an optional url parameter. Paste a Harness UI URL, a pipeline page, an execution log, a dashboard, and the server automatically extracts the account, org, project, and resource identifiers. The agent gets context without the developer having to specify it manually.
Harness Skills: From MCP Tools to Guided Workflows
Reducing tool count solves the context efficiency problem. But developers don't just need fewer tools — they need tools that know how to chain together into real workflows. That's where Harness Skills come in.
The v2 server ships with a companion skills layer (github.com/thisrohangupta/harness-skills) that turns raw MCP tool access into guided, multi-step workflows. Skills are IDE-native agent instructions that teach the AI how to use the MCP server effectively — without the developer having to explain Harness concepts or orchestration patterns.
How Skills Work
Skills operate at three levels:
Level 1: Shared Agent Instructions
Every IDE gets a base instruction file, loaded automatically when the agent starts:
- CLAUDE.md for Claude Code (auto-loaded)
- AGENTS.md for OpenAI Codex / generic agents
- .cursor/rules/harness.mdc for Cursor (auto-loaded as project rule)
- .github/copilot-instructions.md for VS Code GitHub Copilot
These files teach the agent: what the 11 tools do, how Harness scoping works (account → org → project), dependency ordering (always verify referenced resources exist before creating dependents), and how to extract context from Harness UI URLs.
Level 2: Prompt Templates (Server-Side)
The 26 MCP prompt templates registered directly in the server. Any MCP client can invoke them. They encode multi-step workflows with phase gates, e.g., build-deploy-app structures a 4-phase workflow (clone → scan → CI pipeline → deploy) with explicit "do not proceed until this step is done" checkpoints.
Level 3: Individual Skills (Slash Commands)
Specialized SKILL.md files that function as slash commands in the IDE. Each skill includes YAML frontmatter (trigger phrases, metadata), phased instructions, worked examples, performance notes, and troubleshooting steps.
- Pipeline & Execution: /create-pipeline, /run-pipeline, /debug-pipeline, /create-trigger, /create-template, /migrate-pipeline
- Infrastructure: /create-service, /create-environment, /create-infrastructure, /create-connector, /create-secret
- Access Control: /manage-users, /manage-roles
- Specialized: /analyze-costs, /audit-report, /chaos-experiment, /create-policy
The Interaction Pattern
Without skills, a developer says "deploy my Node.js app" and the agent has to figure out the right Harness concepts, the correct ordering, and the proper API calls from scratch. With skills, the flow is:
- IDE auto-loads shared instructions (tool reference, scoping rules, dependency ordering)
- Agent matches intent to a skill via trigger phrases in skill descriptions
- Skill provides ordered, phase-gated execution steps (what to check, what to ask, what to generate)
- MCP server executes the actual
harness_list/harness_create/harness_executecalls
Performance Benefits
The skills layer delivers three measurable improvements:
Fewer Round-Trips
Without skills, the agent typically needs 3–5 exploratory tool calls to understand Harness's resource model before starting real work. Skills encode this knowledge upfront — the agent knows to check for existing connectors before creating a pipeline, to verify environments exist before deploying, and to use harness_describe for schema discovery instead of trial-and-error.
Correct Ordering on First Attempt
Harness resources have strict dependency chains (connector → secret → service → environment → infrastructure → pipeline → trigger). Skills encode the 7-step "Deploy New Service" and 8-step "New Project Onboarding" workflows as ordered sequences. The agent doesn't discover dependencies through failures, it follows the prescribed order.
Reduced Token Waste
Each failed API call and retry burns tokens. Skills eliminate the most common failure modes (wrong scope, missing dependencies, incorrect parameter formats) by teaching the agent the patterns before execution. The combination of 11 tools (minimal context overhead) plus skills (minimal wasted calls) means more of the context window is available for the developer's actual task.
IDE-Specific Integration
The first Harness MCP server (harness/mcp-server) pioneered the IDE-native pattern with a review-mcp-tool command that works across Cursor, Claude Code, and Windsurf via symlinked definitions:
- .claude/commands/ → Claude Code slash commands
- .cursor/commands/ → Cursor Agent commands
- .windsurf/workflows/ → Windsurf workflows
One canonical definition in .harness/commands/, symlinked to all three. Update once, propagate everywhere.
The v2 skills layer extends this pattern from developer-tool commands to full DevOps workflows, the same "define once, deploy to every IDE" architecture, applied to pipeline creation, deployment debugging, cost analysis, and security review.
Operational Safety: Designed for Production
MCP servers that can create, update, and delete resources need safety guardrails. We built them in from the start.
Human-in-the-loop confirmation: All write operations use MCP elicitation to request explicit user confirmation before executing. The agent presents what it intends to do; the developer approves or rejects.
Fail-closed destructive operations: harness_delete is blocked entirely if the MCP client doesn't support elicitation. No silent deletions.
Read-only mode: Set HARNESS_READ_ONLY=true for shared environments, demos, or when you want agents to observe but not act.
Secrets safety: The secret resource type exposes metadata (name, type, org, project) but never the secret value itself.
Rate limiting and retries: Configurable rate limits (default: 10 req/s), automatic retries with backoff for transient failures, and bounded pagination to prevent runaway list operations.
Deployment: Local to Team-Scale
The v2 server supports two transports:
- Stdio (default): Direct integration with Claude Desktop, Cursor, Windsurf, Gemini CLI. Zero network configuration.
- Streamable HTTP: Session-based remote deployment. Kubernetes manifests included. Sessions reaped after 30 minutes. CORS restricted. Rate limited to 60 req/min per IP.
For team deployments, the HTTP transport is compatible with MCP gateways like Portkey, LiteLLM, and Envoy-based proxies, enabling shared control planes with centralized auth, observability, and policy enforcement.
# Local (Cursor, Claude Code)
npx harness-mcp-v2@latest
# Remote (team deployment)
npx harness-mcp-v2@latest http --port 3000
# Docker
docker run -e HARNESS_API_KEY=pat.xxx.yyy.zzz harness-mcp-v2
Why This Architecture Matters
The shift from 130+ tools to 11 isn't about simplification for its own sake. It's about recognizing that the best MCP servers are capability-oriented agent interfaces, not API mirrors.
Building the first Harness MCP server taught us the same lesson the broader ecosystem is learning: when you expose one tool per API endpoint, you're asking the LLM to be a routing layer. You're consuming context on definitions that could be used for reasoning. And you're fighting against the LLM's actual strengths, reasoning, planning, and multi-step problem solving, by forcing it to do something a switch statement does better. That first server made the cost concrete. The v2 is our answer.
The registry pattern inverts this. The tool vocabulary is stable: 11 verbs today, 11 verbs when Harness ships 50 more resource types. The registry is extensible. The skills layer is composable. The LLM reasons about what to do, and the server handles how to do it. That's not just an efficiency win — it's the correct division of labor between an LLM and a server.
This is the pattern we think more MCP servers should adopt, especially platforms with broad API surfaces. The MCP specification itself is built on the idea that servers expose capabilities, not endpoints. We took that literally.
Real Life Use Cases
The efficiency gains from the v2 architecture translate directly into concrete, time-saving use cases for developers operating within their IDEs. The combination of a minimal tool surface (11 tools), deep resource knowledge (125+ resource types), and pre-encoded workflows (Harness Skills) allows the agent to handle complex DevOps tasks with minimal guidance.
See it in action:
Some other use cases:
Debug a Failed CI Pipeline: Get root cause and logs for a pipeline run.
Onboard New Service: Create a Service, Environment, Infrastructure, and initial Connector.
Review Cloud Cost Anomaly: Investigate a sudden spike in cloud spend.
Check Compliance Status: Verify a service's SBOM compliance against OPA policies.
Deploy App to Prod: Execute a canary deployment pipeline.
Get Started
npx harness-mcp-v2@latest
Configure with your Harness PAT (account ID is auto-extracted):
HARNESS_API_KEY=pat.<accountId>.<tokenId>.<secret>
Full source: github.com/thisrohangupta/harness-mcp-v2
Official Harness MCP Server: github.com/harness/mcp-server
---
FAQs
What is the Harness MCP server?
The Harness MCP server is an MCP-compatible server that lets AI agents interact with Harness resources using a small set of generic tools.
Why does MCP tool count matter?
Each exposed tool adds metadata to the model context. A smaller tool surface leaves more room for reasoning and task execution.
How is the Harness MCP server different from a traditional MCP server?
Instead of exposing one tool per API endpoint, it uses 11 generic tools plus a registry that maps resource types to the correct API operations.
Which AI clients work with the Harness MCP server?
The post mentions Cursor, Claude Code, Claude Desktop, Windsurf, Gemini CLI, and other MCP-compatible clients.
Is the Harness MCP server safe for production use?
The design includes write confirmations, fail-closed delete behavior, read-only mode, and controls for retries, rate limiting, and deployment transport.
.jpg)
CI/CD Tools: Basics, Features & How to Choose
CI/CD tools are software platforms that automate code integration, testing, release preparation, and deployment. They connect source control, build systems, test frameworks, and runtime environments into a repeatable delivery pipeline.
CI/CD tools sit at the center of how modern teams ship software. Instead of pushing risky, manual releases once a month, you automate builds, tests, and deployments so every change follows the same, reliable path to production. Done right, CI/CD turns release day from an “all‑hands fire drill” into just another commit.
In this guide, we will walk through what ci cd tools are, the key features that actually matter, and how to choose the right platform for your stack.
Along the way, we will show how platforms like Harness Continuous Integration and Harness Continuous Delivery & GitOps bring AI, governance, and deep insights together so you can ship faster without losing control.
What Are CI/CD Tools?
CI/CD tools are the backbone of modern software delivery. They automate the process of building, testing, and deploying code, so changes can move from commit to production with minimal friction.
At a minimum, effective CI/CD tools:
- Watch your source code for changes and trigger builds automatically.
- Run unit, integration, and other automated tests on each change.
- Package artifacts and deploy them to test, staging, and production environments.
- Provide fast feedback when something breaks so developers can fix it quickly.
- Record what was deployed, where, and by whom for compliance and audits.
To go deeper on pipelines themselves, see our guide on the basics of CI/CD pipelines.
Why CI/CD Tools Are Essential
The importance of CI/CD tools in today's software development ecosystem is hard to ignore. They address several challenges teams face every day:
- Faster time to market. Automation shortens the gap between writing code and running it in production.
- Better code quality. Continuous integration and automated testing catch bugs early, before they reach production.
- Real collaboration. Shared pipelines and shared dashboards break down walls between development, QA, security, and operations.
- Lower release risk. Smaller, more frequent deployments make problems easier to spot and safer to roll back.
- Higher productivity. Developers spend more time writing code and less time babysitting manual deployments or waiting on slow builds.
What Is Continuous Integration?
Martin Fowler defined Continuous Integration (CI) as “a software development practice where each member of a team merges their changes into a codebase together with their colleagues' changes at least daily.” Each integration triggers automated builds and tests, allowing teams to detect and address integration issues early. This approach helps maintain a consistently stable codebase and reduces the time and effort required for integration at later stages of development.
Modern CI/CD tools extend this by making those builds faster and more insightful, surfacing exactly which tests or components were impacted by a given change.
What Is The "CD" In CI/CD?
The "CD" in CI/CD can stand for either Continuous Delivery or Continuous Deployment. While closely related, these concepts have distinct implications for the software release process.
What Is Continuous Delivery?
Continuous Delivery is an extension of continuous integration. It automates the process of preparing code changes for release to production. In continuous delivery, every change that passes automated tests is kept in a production-ready state and can be deployed at any time, often with a manual approval step before release. Additional tests and security scans are run in these test environments. This allows for manual approval and additional testing before the final push to production.
Teams often rely on CI/CD tools with strong approval workflows and policy controls here, so releases stay safe without turning into ticket‑driven bottlenecks.
What Is Continuous Deployment?
Continuous Deployment takes automation a step further. In this model, every change that passes the automated tests is automatically deployed to production without manual intervention.
This approach requires a high degree of confidence in the testing process and can significantly reduce the time between writing code and seeing it live in production.
In practice, only teams with mature testing, monitoring, and rollback capabilities should aim for full continuous deployment.
Key Features To Compare In CI/CD Tools
Not all CI/CD tools solve the same problems. When you compare options, focus on a few core dimensions:
- Automation depth. Does the tool cover only build and test, or can it also orchestrate complex multi‑service deployments and rollbacks?
- Ecosystem integrations. How well does it connect to your Git provider, issue tracker, security scanners, cloud, and observability stack?
- Scalability and performance. Can it handle your concurrency needs and repository size without slowing builds to a crawl?
- AI and intelligence. Does it provide capabilities like intelligent test selection, root cause hints, and smart caching to cut feedback time?
- Security and compliance. Look for secrets management, auditable pipelines, RBAC, policy‑as‑code, and supply chain safeguards.
- Visibility and analytics. Can you easily see which pipelines are slow, which tests are flaky, and where deployments fail?
- Deployment flexibility. Support for containers, serverless, VMs, Kubernetes, and multiple clouds without heavy custom scripting.
- Cost and operations. Consider both licensing and the operational cost of maintaining the platform on your own infrastructure.
CI/CD And DevOps
While CI/CD and DevOps are often mentioned in the same breath, they are not synonymous. CI/CD refers to specific practices and tools within the software development lifecycle, while DevOps is a broader cultural and operational philosophy.
DevOps aims to break down barriers between development and operations teams, fostering collaboration and shared responsibility. CI/CD practices are a key component of DevOps, but DevOps encompasses a wider range of principles and practices aimed at improving overall software delivery and operational performance.
Think of CI/CD tools as the automation layer that makes DevOps ways of working real in day‑to‑day delivery.
Securing CI/CD
CI/CD security is a critical consideration in modern software development. It involves implementing security measures throughout the CI/CD pipeline to protect against vulnerabilities and ensure the integrity of the software delivery process. This includes:
- Secure code analysis
- Dependency scanning
- Container security
- Infrastructure as Code security
- Secrets management
- Access control and authentication
- SBOM generation
- Artifact signing
- SLSA framework
- Provenance tracking
By integrating security into the CI/CD pipeline, organizations can shift security left, addressing potential issues earlier in the development process and reducing the risk of security breaches in production environments. For more information, check out DevSecOps in the Harness Academy.
If you are building or modernizing pipelines today, plan security into your CI/CD tools selection from day one.
Advanced platforms also bring AI into this space. Harness, for example, offers AI‑assisted deployment verification that automatically analyzes metrics and logs during deployments to catch anomalies and trigger safe rollbacks.
Popular CI/CD Tools And Where They Fit
The CI/CD tooling landscape is diverse, offering solutions for various needs and preferences. Some common CI/CD tools include:
- Harness: An AI‑native software delivery platform that provides consistent pipelines for CI and CD, with strong governance and minimal scripting. Ideal for teams that want a single platform rather than a patchwork of scripts and plugins.
- Jenkins: An open-source automation server used widely for custom pipelines. Powerful and flexible, but often requires significant maintenance and plugin management.
- GitLab CI/CD: Built into GitLab, well-suited for teams that already standardize on GitLab for source control and want tightly coupled pipelines.
Each of these CI/CD tools has strengths. The right choice depends on your existing ecosystem, team skills, compliance needs, and appetite for maintaining tooling.
How To Choose The Right CI/CD Tools For Your Team
A practical evaluation process for CI/CD tools looks something like this:
- Clarify your constraints.
- Compliance and data residency.
- Cloud vs on‑premises preferences.
- Languages, frameworks, and target environments.
- Map your needs to capabilities.
- Do you need only CI, or CI plus sophisticated CD and release orchestration?
- How critical are AI features, governance, and analytics for you right now?
- Avoid tool sprawl.
- Prefer platforms that can standardize pipelines across teams instead of every team rolling their own scripts.
- This is where internal developer platforms and golden paths built on CI/CD tools start to pay off.
- Run a focused proof of concept.
- Pick one or two representative services.
- Measure build time, deployment frequency, failure rate, and onboarding time before and after.
- Look beyond day one.
- Ask what upgrades, plugin maintenance, and infrastructure management will look like in year two.
- Evaluate how well the platform surfaces data and insights so you can keep improving.
If you are comparing cloud‑hosted vs self‑managed approaches, our article on cloud-based CI/CD options outlines trade‑offs across control, cost, and operational overhead.
How Harness Can Help
Harness stands out in the CI/CD tooling landscape as a comprehensive Software Delivery Platform that addresses the complexities of modern software development. Here's how Harness can elevate your CI/CD processes:
- Integrated DevOps platform: Harness provides consistent pipelines for CI/CD, ensuring a seamless workflow from code commit to production deployment.
- Exceptional speed: Harness CI leverages test intelligence, intelligent caching, and optimized hardware for cloud builds, significantly reducing build and deployment times.
- Minimal scripting: With excellent out-of-the-box capabilities for builds and deployments, Harness minimizes the need for extensive scripting, allowing developers to focus on writing code rather than maintaining complex pipeline configurations.
- Strong governance: Harness offers granular Role-Based Access Control (RBAC) and policy-as-code approaches, enabling organizations to implement robust governance measures across their CI/CD pipelines.
- Scalability: Designed to handle enterprise-scale deployments, Harness can grow with your organization, supporting complex microservices architectures and multi-cloud environments.
In practice, that looks like:
- Faster, smarter CI. Harness CI uses Test Intelligence to run only the tests impacted by a change and incremental builds to avoid rebuilding what has not changed. Combined with analytics and insights, teams see exactly where time is spent and which tests are noisy.
- Flexible, reliable CD. Harness CD gives you powerful pipelines that support canary, blue‑green, and rolling strategies with little to no custom scripting. With deploy anywhere, you can target Kubernetes, VMs, functions, and multiple clouds from a single model.
- Built‑in governance and insight. Features like DevOps pipeline governance provide policy‑as‑code controls and approvals without turning every deployment into ticket‑ops. With DevOps data visualization, leaders get clear views into DORA metrics, bottlenecks, and trends across teams.
By adopting Harness as your CI/CD tools platform, you can streamline software delivery, improve code quality, and accelerate time to market while still meeting strict security and governance requirements.
CI/CD Tools: Frequently Asked Questions (FAQs)
What are CI/CD tools?
CI/CD tools are software systems that automate how code is built, tested, and deployed. They connect your source control, test suites, and runtime environments into a repeatable pipeline so every change follows the same path to production.
How are CI/CD tools different from a full DevOps platform?
Many CI/CD tools focus just on automation for builds and deployments. DevOps platforms go further with governance, security, cost controls, and developer self‑service. Harness combines both, so you do not need a separate stack of ad‑hoc scripts and point tools.
Do small teams really need CI/CD tools?
Yes. Even very small teams benefit from automated builds and tests. Manual steps are fragile and do not scale. Starting with CI/CD tools early keeps quality high and avoids painful rewrites of your delivery process later.
How do CI/CD tools improve security?
They provide consistent places to run security scans, enforce policies, and control who can deploy what. When combined with DevSecOps practices and capabilities like AI‑assisted verification, CI/CD tools help catch vulnerabilities before they hit customers.
What should I prioritize when evaluating CI/CD tools?
Look for fast feedback, strong integration with your Git provider, clear governance stories, and evidence that the tool can handle your scale. AI‑driven insights and good observability into pipelines are now table stakes for serious teams.
How is Harness different from traditional CI/CD tools?
Traditional tools often require heavy scripting and manual integration. Harness focuses on intelligent automation, policy‑driven governance, and a unified platform that covers CI, CD, and insights in one place, so platform teams can standardize delivery without slowing developers down.
How can I automate rolling deployments and rollbacks?
With Harness Continuous Delivery & GitOps, you can create reusable templates for rolling deployment pipelines, link them to observability tools, and use AI to help with verification. Harness checks metrics and logs at every step of a rollout and can automatically pause or roll back if there are any problems. This makes rolling deployment a low-effort, repeatable process.
How do rolling deployments fit into GitOps and Argo CD workflows?
In GitOps, manifests stored in Git describe how rolling deployments should work, and tools like Argo CD make sure that the desired state is reflected in Kubernetes clusters. Platforms like Harness GitOps add enterprise-level visibility, governance, and promotion workflows to Argo CD. This makes it easier to run rolling deployments on a large scale across many services and clusters.
.png)
Resilience Testing Is Non-Negotiable in the Enterprise SDLC
Modern software delivery has dramatically accelerated. AI-assisted development, automated CI/CD pipelines, and cloud-native architectures have made it possible for teams to deploy software dozens of times per day.
But speed alone does not guarantee reliability.
At Conf42 Site Reliability Engineering (SRE) 2026, Uma Mukkara, Head of Resilience Testing at Harness and co-creator of LitmusChaos, delivered a clear message: outages are inevitable. In modern distributed systems, assuming your design will always work is not just optimistic—it’s risky.
In fact, as Uma put it, failure in distributed systems is a mathematical certainty.
That’s why resilience testing must become a core, continuous practice in the Software Development Life Cycle (SDLC).
The Reality of Inevitable Outages
Even the most reliable cloud providers experience outages.
Uma illustrated this with examples that highlight how unpredictable failures can be:
- Physical disruption such as drone strikes affecting AWS Middle East data centers
- Policy or configuration errors that triggered cascading outages on cloud platforms like Azure
- Retry storms and load spikes where services collapse under unexpected demand
These incidents demonstrate an important reality: the types of failures constantly evolve.
A system validated during design may not be resilient against tomorrow’s failure scenarios. Architecture may stay the same, but the failure patterns surrounding it continuously change.
This is why resilience cannot rely on assumptions.
Hope is not a strategy—verification is.
For a deeper look at this broader approach to resilience, see how chaos engineering, load testing, and disaster recovery testing work together.
What Resilience Really Means
Resilience is often misunderstood as simply keeping systems online.
But uptime alone does not make a system resilient.
Uma defines resilience more precisely:
Resilience is the grace with which systems handle failure and return to an active state.
In practice, a resilient system must handle three categories of disruption:
1. System Failures
Pod crashes, node failures, infrastructure disruptions, or network faults.
2. Load Conditions
Traffic spikes or sudden demand that pushes systems to their limits.
3. Disasters
Regional outages, multi-AZ failures, or infrastructure loss that require recovery mechanisms.
If teams test only one of these dimensions, they leave significant risks undiscovered.
True resilience requires verifying how systems behave across all three scenarios.
Continuous Verification in the SDLC
One of the biggest challenges Uma highlighted is how organizations treat resilience.
Many teams still see it as a “day-two problem”—something SREs will handle after systems are deployed.
Others assume that once resilience has been validated during system design, the problem is solved.
In reality, resilience must be continuously verified.
As systems evolve with each release, so do their failure modes. The most effective strategy is to:
- Test resilience continuously
- Verify resilience with every delivery
- Document results across releases
This approach shifts resilience testing into the outer loop of the SDLC, alongside functional and performance testing.
Instead of waiting for production incidents, teams proactively identify weaknesses before customers experience them.
Understanding Resilience Debt
Uma introduced an important concept: resilience debt.
Resilience debt is similar to technical debt. When teams postpone resilience validation, they leave hidden risks unresolved in the system.
Over time, that debt accumulates.
And when failure eventually occurs—which it inevitably will—the business impact grows proportionally to the resilience debt that was ignored.
The only way to reduce this risk is to steadily increase resilience testing coverage over time.
As testing matures across multiple quarters, organizations gain better feedback about system behavior, uncover more risks earlier, and continuously reduce the likelihood of severe outages.
A Holistic Approach to Resilience Testing
Another key takeaway from Uma’s session is that resilience testing should not happen in silos.
Many organizations treat chaos testing, load testing, and disaster recovery validation as separate initiatives owned by different teams.
But the most meaningful risks often appear when these scenarios intersect.
For example:
- A resource bottleneck might only appear when high traffic coincides with a service failure.
- Chaos experiments developed for reliability testing can also be reused in disaster recovery workflows.
- Combining chaos and load tests helps teams observe system behavior at failure limits under real-world conditions.
That’s why resilience testing must be approached as a holistic practice combining:
- Chaos Engineering
- Load Testing
- Disaster Recovery (DR) Validation
You can explore the fundamentals of resilience testing in the Harness documentation.
Collaboration Across Teams
Resilience testing also requires collaboration across multiple roles.
Developers, QA engineers, SREs, and platform teams all contribute to validating system reliability.
Uma pointed out that many organizations already share infrastructure for testing but run different experiments independently. By coordinating these efforts, teams can:
- reuse testing environments
- share chaos experiments across testing scenarios
- validate DR workflows more frequently
- improve testing efficiency across teams
Resilience becomes significantly stronger when personas, environments, and test assets are shared rather than siloed.
The Role of AI in Resilience Testing
As systems become more complex, another challenge emerges: knowing what to test and when.
Large organizations may have hundreds of potential experiments, making it difficult to prioritize testing effectively.
Uma described how agentic AI systems can help address this challenge.
By analyzing internal knowledge sources such as:
- incident data
- CI/CD pipeline history
- infrastructure configuration
- operational documentation
AI systems can recommend:
- the most relevant chaos experiments
- appropriate load testing scenarios
- disaster recovery tests that should run at a given time
These recommendations allow teams to run the right tests at the right moment, improving resilience coverage without overwhelming engineering teams.
A Unified Platform for Resilience Testing
To support this holistic approach, Harness has expanded its original Chaos Engineering capabilities into a broader platform: Harness Resilience Testing.
The platform integrates multiple testing disciplines in a single environment, enabling teams to:
- design chaos experiments
- run load tests
- validate disaster recovery workflows
- observe system risk patterns in one place
By combining these capabilities, teams gain a single pane of glass for identifying resilience risks across the SDLC.
This unified view allows organizations to track trends in system reliability and proactively address weaknesses before they turn into production incidents.
Resilience Is a Core Practice for Modern SRE Teams
Uma closed the session with a clear conclusion.Resilience testing is not optional.
Outages will happen. Infrastructure will fail. Traffic patterns will change. Dependencies will break.
What matters is whether organizations have continuously validated how their systems behave when those failures occur.
The more resilience testing coverage teams build over time, the more feedback they receive—and the lower the potential business impact becomes.
In modern software delivery, resilience is no longer just a reliability practice.
It is a core discipline of the enterprise SDLC.
Ready to start validating your system’s resilience?
Explore Harness Resilience Testing and start validating reliability across your SDLC.
.png)
The Art of Prompting in AI Test Automation
E2E Testing Has a New Bottleneck, and It's Not the Code
End-to-end (E2E) testing has always been the hardest part of a QA strategy. You're simulating real users, navigating real flows, validating real outcomes across browsers, environments, and data states that never hold still.
Traditional test automation tackled this with scripts: rigid, deterministic sequences tied to element selectors and hard-coded values. They worked until the UI changed. Or the data changed. Or a new team member touched the wrong locator. The result: flaky, expensive test maintenance cycles that teams quietly stopped trusting.
AI-driven testing/AI Test Automation promised to fix this. And it has, but only for teams who figured out the new bottleneck. It's not the model. It's not the tooling. It's the prompt engineering.
In AI test automation, you don't write scripts anymore; you write instructions. And the quality of those instructions determines everything that follows.
What Is a Prompt in the Context of E2E Testing?
In general AI usage, a prompt is the input you give to get an output. In intelligent test automation, it's much more specific: a prompt is a natural language instruction that tells the AI testing engine what to do, what to verify, and how to handle what it finds.
A complete, well-formed test prompt for E2E automation includes five ingredients:
Goal
What business outcome is being tested? (e.g., 'User completes checkout with a promo code applied')
Context
Where does the test start? What preconditions exist? What user state or data should be assumed?
Specifics
Exact values, field names, amounts, account types, formats, and no ambiguity about inputs or expected data.
Assertion
What does success look like? A confirmation message? A balance update? A redirect to a specific URL?
Boundaries
What should the AI NOT do? What's out of scope for this particular test step?
Miss any one of these, and you've handed the AI a half-built blueprint. It will fill in the gaps, just not necessarily the way you intended.
Why Prompt Quality Directly Determines Test Stability
Here's the fundamental truth of AI-driven testing: non-deterministic prompts produce non-deterministic tests. And non-deterministic tests are worse than no tests at all; they create false confidence and burn engineering time chasing phantom failures.
The good news: prompt quality is entirely within your control. Unlike flaky network conditions or unpredictable UI re-renders, a badly written prompt is just a rewrite away from being a reliable one. This is the foundation of self-healing tests. Better prompts dramatically increase the likelihood that the tests can self-heal. Let's break down where prompts go wrong and right.
The Most Common Prompt Failures in E2E Testing
✅ EFFECTIVE PROMPT
"Navigate to the checkout page, apply promo code SAVE20, and verify the order total shows $80.00 after the discount is applied from $100.00."
❌ WEAK PROMPT
"Go to checkout and check the discount works."
✅ EFFECTIVE PROMPT
"Click on the row in the Orders table where the Status column shows 'Completed,' and the Order ID matches the ORDER_ID parameter."
❌ WEAK PROMPT
"Click on the completed order."
✅ EFFECTIVE PROMPT
"After the payment confirmation spinner disappears, assert: Is the text 'Payment Successful' visible on screen?"
❌ WEAK PROMPT
"Check that payment worked."
5 Prompt Patterns That Make E2E Tests Reliable
Pattern 1: The Intent + Outcome Pattern
Lead with the business intent, end with the verifiable outcome. This structure forces you to be clear about both what you're doing and how you'll know it worked.
"Complete a standard checkout as a guest user with item SKU-4421, shipping to postcode 90210, and verify the order confirmation page displays an order number."
Why it works: The AI knows the starting intent, the data to use, and exactly what constitutes success. No room for interpretation.
Pattern 2: The Precondition Guard
State what must be true before the test action begins. This prevents cascading failures caused by the AI attempting steps when the application isn't in the right state.
"Given the user is logged in and has at least one saved payment method, navigate to the subscription renewal page and click 'Renew Now'."
Why it works: Guards against false failures. If the precondition isn't met, the test fails meaningfully, not mysteriously.
Pattern 3: Content-Based References (Not Positions)
Never reference UI elements by their position on screen. Reference them by their visible content, label, or semantic role. This is the single biggest driver of self-healing tests and reduces test maintenance dramatically.
✅ EFFECTIVE PROMPT
"Select the product named 'Wireless Mouse' from the search results."
❌ WEAK PROMPT
"Select the second item in the search results."
Why it works: Lists reorder. Pages change. Content-based references survive both.
Pattern 4: Atomic Assertions
One assertion should test one condition. Compound assertions ('check that X is visible AND says Y AND the button is enabled') are harder for the AI to evaluate cleanly and produce confusing failure messages.
"Is the error message 'Invalid credentials' visible below the login form?"
Not: 'Is the error message visible and does it say Invalid credentials and is the login button still enabled?', split these into three separate assertions.
Pattern 5: The Fallback Instruction
For data that may not always exist (discounts, optional fields, conditional UI elements), always specify what the AI should do when that data is absent.
"Extract the promotional banner text into PROMO_TEXT, or set PROMO_TEXT to 'none' if no promotional banner is displayed on the page."
Why it works: Tests that handle absence are far more stable across different data states and environments.
Spotlight: Harness AI Test Automation
Harness AI Test Automation (AIT) is one of the most complete implementations of prompt-driven E2E testing available today. It reduces the need to manually script Selenium/Playwright flows with an intent-driven model: you describe what a user wants to achieve, and Harness AI figures out how to test it.
The platform is built on an agentic AI testing architecture, an autonomous testing system that blends LLM reasoning with real-time application exploration, DOM analysis, and screenshot-based visual validation. What makes it especially relevant to this discussion is that Harness AIT exposes the quality of your prompts directly: write a vague intent, get an unreliable test. Write a precise one, get a test that runs stably in your CI/CD testing pipeline.
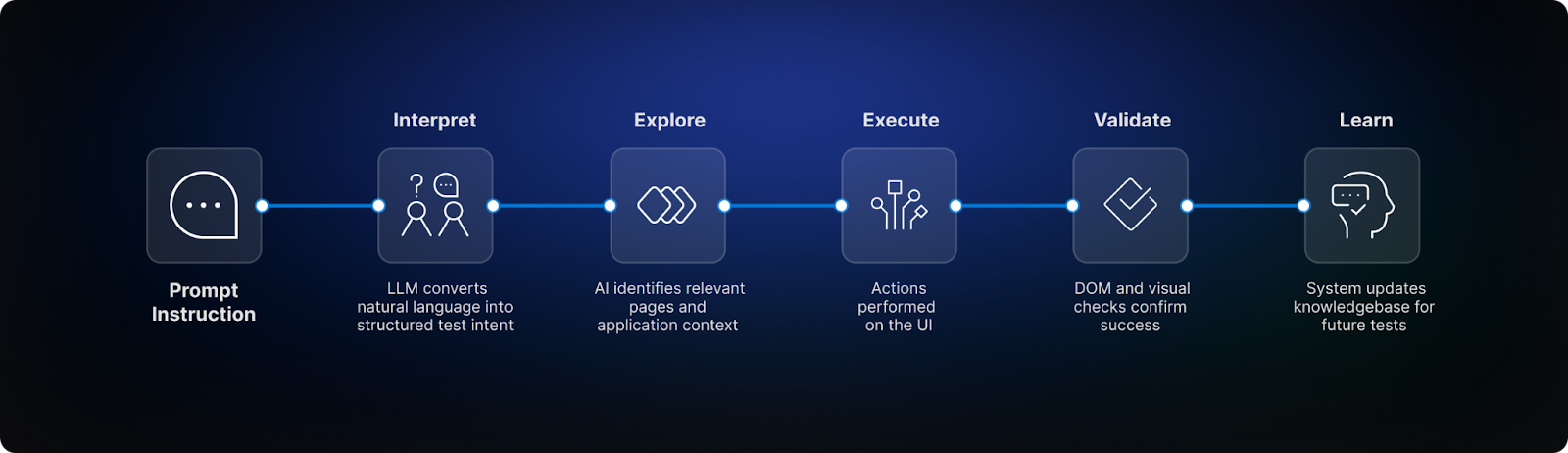
"Rather than scripting every step of 'add item to cart and checkout,' a tester writes: Verify that a user can add an item to the cart and complete checkout successfully. The AI testing tool interprets the intent and executes the full flow, including assertions."
The 4 Harness AI Command Types
Harness structures AI instructions into four command types for codeless test automation. Each has its own prompting rules; get them right and your tests become dramatically more stable.
AI Assertion - Verify application state at a specific point in execution
Write it like this:
"In the confirmation dialog, is the deposit amount displayed as $100.00?"
Avoid this:
"Is the amount correct?" AI has no memory of what amount was entered.
AI Command - Perform a specific, discrete UI interaction
Write it like this:
"After the loading spinner disappears, click the 'Continue' button in the payment form."
Avoid this:
"Click Continue." Which Continue? What if it's not ready yet?
AI Task - Execute a complete multi-step business workflow
Write it like this:
"Transfer $500 from Savings to Checking, confirm the transaction and verify both balances are updated correctly."
Avoid this:
"Transfer money between accounts.", missing values, accounts, and success criteria.
AI Extract Data - Capture dynamic values for use in subsequent test steps
Write it like this:
"Create parameter ORDER_ID and assign the order number from the confirmation message on this page."
Avoid this:
"Get the order number.", stored where? from which element?
Harness AIT: How the Agentic Workflow Uses Your Prompts
When you submit an intent-driven prompt to Harness AIT, it goes through a five-stage pipeline, and the quality of your prompt shapes every stage:
1. Interpret
The LLM Interface Layer reads your natural language prompt and formulates a structured test intent. Vague prompts produce ambiguous intents.
2. Explore
The AI queries its App Knowledgebase (Application Context) to find relevant pages and flows. Specific context in your prompt narrows this search dramatically.
3. Execute
Each step is translated into an executable action. Content-based references in your prompt produce resilient steps. Positional ones produce fragile ones.
4. Validate
DOM and screenshot-based validation confirms both functional and visual state. Your assertion prompts define exactly what gets checked.
5. Learn
Each run updates the App Knowledgebase. Better prompts produce richer, more accurate knowledge, improving future test case generation and reducing test maintenance.
The Prompt Mistakes That Break E2E Tests
These are the most common prompt antipatterns seen in AI-driven E2E testing, each one a reliable way to introduce flakiness:
Positional References
Saying 'click the third row' or 'select the first option' creates tests that break every time data changes or UI reorders.
Missing Context
Assertions like 'Is the amount correct?' fail because the AI might not have any memory of previous steps. Restate the expected values in assertions. Every prompt must be self-contained.
Compound Assertions
Checking multiple conditions in one assertion makes failures ambiguous. One assertion, one condition, always.
No Success Criteria
Tasks like 'register a new user' without specifying what success looks like leave the AI guessing when to stop.
Assumed Data Formats
Not specifying 'extract the total as a number without a currency symbol' means you might get '$1,234.56' when you needed '1234.56'.
Ignoring Timing
Not accounting for loading states ('after the spinner disappears') is one of the top causes of intermittent test failures.
The Takeaway: Prompts Are Your New Test Scripts
End-to-end testing has always required precision. The medium has changed, from XPath selectors and coded steps to natural language testing instructions, but the requirement for precision hasn't. If anything, the stakes are higher because a poorly written prompt now fails invisibly: the AI will attempt something, just not what you intended.
The teams getting the most out of AI test automation are not the ones with the most sophisticated models. They're the ones who've learned to write clear, specific, self-contained instructions through effective prompt engineering. Who knows the difference between 'click the third button' and 'click the Submit button in the payment form.' Who ends every assertion with a question mark and every task with a success criterion.
Platforms like Harness AI Test Automation are built to reward exactly this kind of precision, turning well-crafted prompts into stable, self-healing tests that are CI/CD testing-ready and survive the real world with minimal test maintenance.
"The art of prompt engineering isn't about clever wording. It's about transferring your intent, completely and unambiguously, to an autonomous testing system that will act on every word you write."
Write with that precision, and your intelligent test automation will finally be the safety net it was always meant to be.
Ready to Transform Your Testing with AI?
Harness AI Test Automation empowers teams to move faster with confidence. Key benefits include:
- Faster test creation: Write robust, intent-driven tests in minutes rather than hours
- Reduced test maintenance: Self-healing tests adapt to UI changes automatically, slashing maintenance by up to 70%
- Improved collaboration: Align developers, testers, and product managers around shared intent with natural language testing
- CI/CD ready: Seamlessly integrate with your existi+ng pipelines and accelerate software delivery
Harness AI Test Automation turns traditional QA challenges into opportunities for smarter, more reliable automation, enabling organizations to release software faster while maintaining high quality.
If you're ready to eliminate flaky tests, simplify maintenance, and improve test reliability with intent-driven, natural-language testing, try Harness AI Test Automation today or contact our team to see how it can transform your testing experience.
Knowledge Graphs: The Backbone of AI-First Software Delivery
---
Key Takeaways
- AI-generated code fails without a real delivery context
- Knowledge graphs turn fragmented DevSecOps data into operational truth
- Platform teams must move from AI-assisted to AI-operational DevOps
- Overmodeling kills ROI faster than missing data
- Context must be fresh, permissioned, and use-case driven
---
AI can generate code in seconds. It still can’t ship software safely.
That gap isn’t about model quality or prompt engineering. It’s about context, and most software organizations don’t have a system that accurately reflects how pipelines, services, environments, policies, and teams actually relate to each other.
Without that context, AI doesn’t automate delivery. It amplifies risk.
I am responsible for building the Knowledge Graph that powers Harness AI, and I see this every day, working on AI infrastructure and data platforms at Harness, and it’s a recurring theme. AI-first delivery fails not because of intelligence, but because of fragmentation.
AI Is Not the Bottleneck, Context Is
Modern engineering organizations already generate more data than any human can reason about:
- CI pipelines
- Deployment workflows
- Cloud environments
- Security policies
- Cost signals
- Incident data
Each system works. The problem is that none of them agree on what the system actually is.
When something breaks, we don’t query systems. We page people. That’s the clearest signal you’ve hit the context bottleneck. When your organization depends on a few humans to resolve incidents, you don’t have a tooling problem. You have a context problem.
From AI-Assisted DevOps to AI-Operational DevOps
Most teams today operate in AI-assisted DevOps:
- AI helps write code
- AI generates pipelines
- AI summarizes logs
That’s helpful, but shallow.
AI-operational DevOps is different. Here, AI doesn’t just assist tasks. It understands how software actually moves from commit to production, including constraints, dependencies, and governance.
The difference is a platform problem. Without a shared context layer, AI remains a collection of point optimizations. With one, it becomes an operator.
What “Context” Actually Means in Software Delivery
Context is not dashboards. It’s not a data lake. And it’s definitely not another CMDB.
In practice, context means entities and relationships.
Core entities that matter
In DevSecOps environments, the most critical entities are:
- Pipelines (the workflow backbone)
- Services and artifacts
- Environments and clusters
- Policies and approvals
- Identities and permissions
Pipelines are often the natural center — not because they’re special, but because they express intent.
Relationships are where value emerges
A pipeline alone isn’t context.
A pipeline links to:
- the cluster it deploys to
- The policies it must pass
- The identity running it
- the services it affects
That's the operational truth.
This is why knowledge graphs matter. They don’t store more data; they preserve meaning.
To truly transform the software development lifecycle, AI needs more than just intelligence, it needs deep, operational context. Harness AI uses a purpose-built Software Delivery Knowledge Graph to make AI fast, efficient, and exceptionally accurate. By bridging the gap between raw data and real-world delivery pipelines, we ensure that your AI operates with complete situational awareness from day one, allowing teams to ship faster without breaking things.
Why Knowledge Graphs Fail in Practice
I’ve seen three failure modes repeat across organizations:
- Overmodeling: Teams model everything before solving anything. The graph becomes academic and unused.
- Undermodeling: Teams skip key relationships, then wonder why AI gives shallow or incorrect answers.
- Stale context: Perfectly modeled data that’s a week old is useless during an outage.
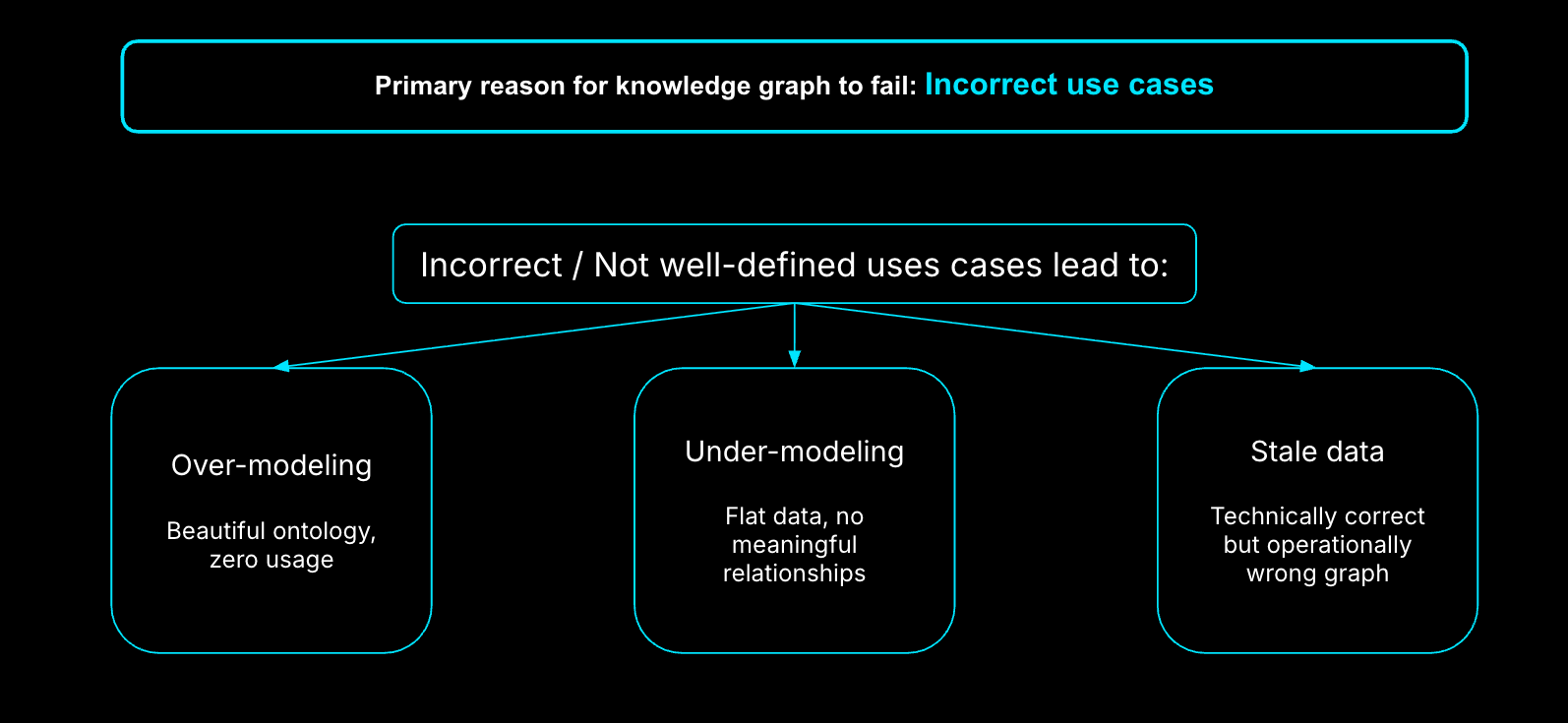
A knowledge graph only works when it’s use-case driven, minimal, and fresh.
The Minimum Viable Knowledge Graph
The fastest way to see value is not breadth, it’s focus. Start with one use case that cannot be solved by a single system.
A strong starting point:
- Root cause analysis for failed pipelines
To support that, you need:
- Git metadata
- CI/CD execution state
- Environment and access data
That’s often fewer than 10 entities. Everything else is enrichment, not day one requirements.
Freshness, Not Completeness, Determines Value
AI agents don’t need perfect context. They need the current context.
For delivery workflows, near real-time synchronization is often mandatory. When a deployment fails, an engineer doesn’t want last month’s answer; they want why it failed now. This is why the semantic layer matters. AI agents should interact with meaning, not raw tables.
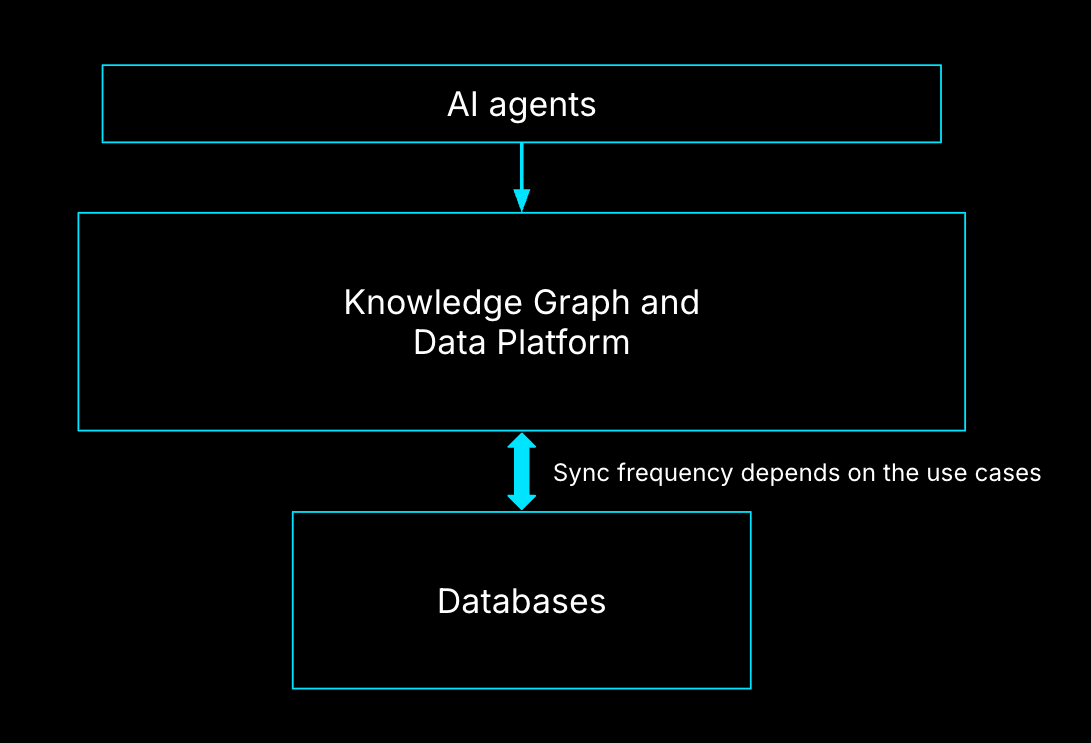
Guardrails by Default: Policies, RBAC, and Trust
AI agents must be treated as extensions of humans, not superusers.
That means:
- RBAC applies to agents exactly as it does to people
- Policies define what context can be surfaced
- Least privilege is non-negotiable
At Harness, Policy as Code and native policy agents ensure AI can’t bypass governance — even when it’s acting autonomously.
How to Measure Whether Context Is Working
You don’t measure a knowledge graph by node count. You measure it by outcomes.
Four metrics matter:
- Answer quality (often validated using a secondary model)
- Human validation (does this reduce toil?)
- Evaluation over time (across models and versions)
- Cost efficiency (context without ROI is technical debt)
If context doesn’t improve decisions, it’s noise.
A Real AI-Driven Deployment Example
Imagine a developer says, in natural language: “Deploy this service to QA and production.”
Behind the scenes, an AI agent:
- Identifies the service and repo
- Generates a pipeline aligned with org standards
- Inserts approvals, security scans, and policies
- Validates access to target environments
If the pipeline fails, the same graph enables automated remediation:
- Was access revoked?
- Did a policy change?
- Did the artifact differ?
That’s not automation. That’s operational reasoning.
Why Cost, Rollbacks, and Incidents Demand Graph Context
Traditional dashboards tell you what happened. Knowledge graphs tell you why.
Cost spikes only make sense when linked to:
- deployment decisions
- environment selection
- service dependencies
Rollbacks are only safe when dependency graphs are understood. Rolling back a service without knowing the upstream and downstream impact is how outages cascade.
Guidance to Get Started (and What to Avoid)
Do this:
- Pick 1–2 high-impact use cases
- Model only what’s required
- Iterate through the semantic layer first
Avoid this:
- Modeling your entire SDLC upfront
- Treating the graph as a data dump
- Chasing completeness over usefulness
Context is a product, not a schema.
Conclusion
AI-first software delivery doesn’t fail because models aren’t smart enough. It fails because platforms don’t understand themselves.
Knowledge graphs give AI the one thing it can’t generate on its own: context grounded in reality, thus making them the primary pillar in AI-first software delivery context.
The future of software delivery isn't just automated; it's intelligently orchestrated. Because Harness AI uses a Software Delivery Knowledge Graph to make AI fast, efficient, and accurate, your teams can finally trust AI to handle complex operational workflows without adding risk. We’ve done the heavy lifting of mapping your operational truth so your AI can act with absolute precision.
FAQs
What’s the difference between observability and a knowledge / context graph?
Observability shows what’s happening. Knowledge/Context graphs explain what it means.
Do knowledge graphs replace existing tools?
No. They connect them.
Who owns the knowledge graph?
Everyone: platform, SRE, security, and application teams.
Is this only for large enterprises?
No. Smaller teams benefit faster because tribal knowledge is thinner.
Can AI work without a knowledge graph?
Yes, but only at the task level, not the system level.
Securing AI and Securing With AI: AI Security from Code to Runtime With Harness
AI is changing both what you build and how you build it - at the same time. Today, Harness is announcing two new products to secure both: AI Security, a new product to discover, test, and protect AI running in your applications, and Secure AI Coding, a new capability of Harness SAST that secures the code your AI tools are writing. Together, they further extend Harness's DevSecOps platform into the age of AI, covering the full lifecycle from the first line of AI-generated code to the models running in production.
In November, Harness published our State of AI-Native Application Security report, a survey of hundreds of security and engineering leaders on how AI-native applications are changing your threat surface. The findings were stark: 61% of new applications are now AI-powered, yet most organizations lack the tools to discover what AI models and agents exist in their environments, test them for vulnerabilities unique to AI, or protect them at runtime. The attack surface has expanded dramatically — but the tools to defend it haven't kept up.
The picture is equally concerning on the development side. Our State of AI in Software Engineering report found that 63% of organizations are already using AI coding assistants - tools like Claude Code, Cursor, and Windsurf - to write code faster. But faster isn't safer. AI-generated code has the same vulnerabilities as human-written code, but now with larger and more frequent commits. AppSec programs that were already stretched thin are now breaking under the volume and velocity.
The result is a blind spot on both sides of the AI equation - what you're building, and what you're building with. Today, Harness is closing that gap.
What Makes Harness Different?
Most security vendors are stuck in their lane. Shift-left tools catch vulnerabilities in code before they reach production. Runtime protection tools block attacks after applications are deployed. And the two rarely talk to each other.
Harness was built on a different premise: real DevSecOps means connecting every stage of the software delivery lifecycle, and closing the loop between what you find in production and what you fix in code.
That's what the Harness platform does today. Application Security Testing brings SAST and SCA directly into the development workflow, surfacing vulnerabilities where they're faster and cheaper to fix. SCS ensures the integrity of artifacts from build to deploy, while STO provides a unified view of security posture — along with policy and governance — across the entire organization.
As code ships to production, Web Application & API Protection monitors and defends applications and APIs in real time, detecting and blocking attacks as they happen. And critically, findings from runtime don't disappear into a security team's backlog — they flow back to developers to address root causes before the next release.
The result is a closed loop: find it in code, protect it in production, fix it fast. All on a single, unified platform.
Today, we're extending that loop into AI - on both sides. AI is reshaping what you build and how you build it simultaneously. A platform that can only address one side of that equation leaves you exposed on the other. Harness closes both gaps.
Introducing AI Security
In the State of AI-Native Application Security, 66% of respondents said they are flying blind when it comes to securing AI-native apps. 72% call shadow AI a gaping chasm in their security posture. 63% believe AI-native applications are more vulnerable than traditional IT applications. They’re right to be concerned.
Harness AI Security is built on the foundation of our API security platform. Every LLM call, every MCP server, every AI agent communicating with an external service does so via APIs. Your AI attack surface isn't separate from your API attack surface; it's an expansion of it. AI threats introduce new vectors like prompt injection, model manipulation, and data poisoning on top of the API vulnerabilities your teams already contend with. There is no AI security without API security.
With the launch of AI Security, we are introducing AI Discovery in General Availability (GA). AI security starts where API security starts: discovery. You can't assess or mitigate risk from AI components you don't know exist. Harness already continuously monitors your environment for new API endpoints the moment they're deployed. Recognizing LLMs, MCP servers, AI agents, and third-party GenAI services like OpenAI and Anthropic is a natural extension of that. AI Discovery automatically inventories your entire AI attack surface in real time, including calls to external GenAI services that could expose sensitive data, and surfaces runtime risks, such as unauthenticated APIs calling LLMs, weak encryption, or regulated data flowing to external models.
Beyond discovering and inventorying your AI application components, we are also introducing AI Testing and AI Firewall in Beta, extending AI Security across the full discover-test-protect lifecycle.
AI Testing actively probes your LLMs, agents, and AI-powered APIs for vulnerabilities unique to AI-native applications, including prompt injection, jailbreaks, model manipulation, data leakage, and more. These aren't vulnerabilities that a traditional DAST tool is designed to find. AI Testing was purpose-built for AI threats, continuously validating that your models and the APIs that expose them behave safely under adversarial conditions. It integrates directly into your existing CI/CD pipelines, so AI-specific security testing becomes part of every release — not a one-time audit.
AI Firewall actively protects your AI applications from AI-specific threats, such as the OWASP Top 10 for LLM Applications. It inspects and filters LLM inputs and outputs in real time, blocking prompt injection attempts, preventing sensitive data exfiltration, and enforcing behavioral guardrails on your models and agents before an attack can succeed. Unlike traditional WAF rules that require manual tuning for every new threat pattern, AI Firewall understands AI-native attack vectors natively, adapting to the evolving tactics attackers use against generative AI.
Harness AI Security with AI Discovery is now available in GA, while AI Testing and AI Firewall are available in Beta.
Introducing Secure AI Coding
"As AI-assisted development becomes standard practice, the security implications of AI-generated code are becoming a material blind spot for enterprises. IDC research indicates developers accept nearly 40% of AI-generated code without revision, which can allow insecure patterns to propagate as organizations increase code output faster than they expand validation and governance, widening the gap between development velocity and application risk."
— Katie Norton, Research Manager, DevSecOps, IDC
AI Security addresses the risks inside your AI-native applications. Secure AI Coding addresses a different problem: the vulnerabilities your AI tools are introducing into your codebase.
Developers are generating more code than ever, and shipping it faster than ever. AI coding assistants now contribute to the majority of new code at many organizations — and nearly half (48%) of security and engineering leaders are concerned about the vulnerabilities that come with it. AI-generated code arrives in larger commits, at higher frequency, and often with less review than human-written code would receive.
SAST tools catch vulnerabilities at the PR stage — but by then, AI-generated code has already been written, reviewed, and often partially shipped. Harness SAST's new Secure AI Coding capability moves the security check earlier to the moment of generation, integrating directly with AI coding tools like Cursor, Windsurf, and Claude Code to scan code as it appears in the IDE. Developers never leave their workflow. They see a vulnerability warning inline, alongside a prompt to send the flagged code back to the agent for remediation — all without switching tools or even needing to trigger a manual scan.
"Security shouldn't be an afterthought when using AI dev tools. Our collaboration with Harness kicks off vulnerability detection directly in the developer workflow, so all generated code is screened from the start." — Jeff Wang, CEO, Windsurf
What sets Secure AI Coding apart from simpler linting tools is what happens beneath the surface. Rather than pattern-matching the AI-generated code in isolation, it leverages Harness's Code Property Graph (CPG) to trace how data flows through the entire application - before, through, and after the AI-generated code in question. That means Secure AI Coding can surface complex vulnerabilities like injection flaws and insecure data handling that only become visible in the context of the broader codebase. The result is security that understands your application - not just the last thing an AI assistant wrote.
We Had the Same Problem
When we deployed AI across our own platform, our AI ecosystem grew faster than our visibility into it. We needed a way to track every API call, identify sensitive data exposure, and monitor calls to external vendors — including OpenAI, Vertex AI, and Anthropic — without slowing down our engineering teams.
Deploying AI Security turned that black box into a transparent, manageable environment. Some milestones from our last 90 days:
- We now track 111 AI assets and monitor over 4.76 million monthly API calls, giving our security team a granular, real-time map of our entire AI attack surface.
- We now run 2,500 AI testing scans a week and have remediated 92% of the issues found, including critical weak authentication and encryption gaps in MCP tools.
- We identified and blocked 1,140 unique threat actors attempting more than 14,900 attacks against our AI infrastructure.
The shift wasn't just operational — it was cultural. We moved from reactive monitoring to proactive defense. As our team put it: "Securing AI is foundational for us. Because our own product runs on AI, it must be resilient and secure. We use our own AI Security tools to ensure that every innovation we ship is backed by the highest security standards."
Ready to Secure Your AI?
AI is moving fast. Your attack surface is expanding in two directions at once - inside the applications you're building, and inside the code your teams are generating to build them.
Harness AI Security and Secure AI Coding are available now. Whether you're trying to get visibility into the AI running in your environment, test it for vulnerabilities before attackers do, or stop insecure AI-generated code from reaching production, Harness’ platform is ready.
Talk to your account team about AI Security. Get a live walkthrough of AI Discovery, AI Testing, and AI Firewall, and see how your AI attack surface maps against your existing API security posture.
Already a Harness CI customer? Start a free trial of Harness SAST - including Secure AI Coding. Connect it to your AI coding assistant, and see what's shipping in your AI-generated code today.

The Agent-Native Repo: Why AGENTS.MD is the New Standard
This is part 1 of a five-part series on building production-grade AI engineering systems.
Across this series, we will cover:
- How to make your repository agent-native
- How to prevent context decay in long AI sessions
- How to orchestrate tools, subagents, and external systems
- How to survive the multi-model reality with gateway layers
- How to measure and enforce quality with AI evals
Most teams experimenting with AI coding agents focus on prompts.
That is the wrong starting point.
Before you optimize how an agent thinks, you must standardize what it sees.
AI agents do not primarily fail because of reasoning limits. They fail because of environmental ambiguity. They are dropped into repositories designed exclusively for humans and expected to infer structure, conventions, workflows, and constraints from scattered documentation.
If AI agents are contributors, then the repository itself must become agent-native.
The foundational step is introducing a standardized instruction layer that every agent can read.
That layer is AGENTS.md.
The Real Problem: Context Silos
Every coding agent needs instructions. Where those instructions live depends on the tool.
One IDE reads from a hidden rules directory.
Another expects a specific markdown file.
Another uses proprietary configuration.
This fragmentation creates three systemic problems.
1. Tool-dependent prompt locations
Instructions are locked into IDE-specific paths. Change tools and you lose institutional knowledge.
2. Tribal knowledge never gets committed
When a developer discovers the right way to guide an agent through a complex module, that guidance often lives in chat history. It never reaches version control. It never becomes part of the repository’s operational contract.
3. Inconsistent agent behavior
Two engineers working on the same codebase but using different agents receive different outputs because the instruction surfaces are different.
The repository stops being the single source of truth.
For human collaboration, we solved this decades ago with READMEs, contribution guides, and ownership files. For AI collaboration, we are only beginning to standardize.
What AGENTS.md Is
AGENTS.md is a simple, open, tool-agnostic format for providing coding agents with project-specific instructions. It is now part of the broader open agentic ecosystem under the Agentic AI Foundation, with broad industry adoption.
It is not a replacement for README.md. It is a complement.
Design principle:
- README.md is for humans.
- AGENTS.md is for agents.
Humans need quick starts, architecture summaries, and contribution policies.
Agents need deterministic build commands, exact test execution steps, linter requirements, directory boundaries, prohibited patterns, and explicit assumptions.
Separating these concerns provides:
- A predictable location for agent instructions
- Cleaner, human-focused READMEs
- Reduced duplication
- Cross-tool compatibility
Several major open source repositories have already adopted AGENTS.md. The pattern is spreading because it addresses a real structural gap.
Recent evaluations have also shown that explicit repository-level agent instructions outperform loosely defined “skills” systems in practical coding scenarios. The implication is clear. Context must be explicit, not implied.
A Real Example: OpenAI’s Agents SDK
A practical example of this pattern can be seen in the OpenAI Agents Python SDK repository.
The project contains a root-level AGENTS.md file that defines operational instructions for contributors and AI agents working on the codebase. You can view the full file here: Github.
Instead of leaving workflows implicit, the repository encodes them directly into agent-readable instructions. For example, the file requires contributors to run verification checks before completing changes:
Run `$code-change-verification` before marking work complete.It also explicitly scopes where those rules apply, such as changes to core source code, tests, examples, or documentation within the repository.
Rather than expecting an agent to infer these processes from scattered documentation, the project defines them as explicit instructions inside the repository itself.
This is the core idea behind AGENTS.md.
Operational guidance that would normally live in prompts, chat history, or internal knowledge becomes version-controlled infrastructure.
Designing an Effective Root AGENTS.md
A root AGENTS.md should be concise. Under 300 lines is a good constraint. It should be structured, imperative, and operational.
A practical structure includes four required sections.
1. Project Overview
This section establishes the mental model.
Include:
- Project purpose and high-level architecture
- Directory structure and key components
- Technology stack and critical dependencies
Agents are pattern matchers. The clearer the structural map, the fewer incorrect assumptions they make.
2. Build, Test, and Push Instructions
This section must be precise.
Include:
- Exact build commands
- Test execution commands
- Linter and formatting requirements
- Pre-push validation steps
Avoid vague language. Replace “run tests” with explicit commands.
Agents execute what they are told. Precision reduces drift.
3. Development Workflow
This section defines conventions.
Rather than bloating AGENTS.md, reference a separate coding standards document for:
- Naming conventions
- Logging patterns
- Security requirements
- Repository-specific architectural constraints
The root file should stay focused while linking to deeper guidance.
4. Common Pitfalls and Prohibited Patterns
This is where most teams underinvest.
Document:
- Anti-patterns specific to the codebase
- Deprecated APIs
- Incorrect assumptions agents commonly make
- Areas where public APIs must not change
Agents tend to repeat statistically common patterns. Your codebase may intentionally diverge from those patterns. This section is where you enforce that divergence.
Think of this as defensive programming for AI collaboration.
Hierarchical AGENTS.md: Scaling Context Correctly
Large repositories require scoped context.
A single root file cannot encode all module-specific constraints without becoming noisy. The solution is hierarchical AGENTS.md files.
Structure example:
root/
AGENTS.md
module-a/
AGENTS.md
module-b/
AGENTS.md
sub-feature/
AGENTS.mdAgents automatically read nested AGENTS.md files when operating inside those directories. Context scales from general to specific.
Root defines global conventions.
Module-level files define local invariants.
Feature-level files encode edge-case constraints.
This reduces irrelevant context and increases precision.
It also mirrors how humans reason about codebases.
Compatibility Across Tools
A standard file location matters.
Some agents natively read AGENTS.md. Others require simple compatibility mechanisms such as symlinks that mirror AGENTS.md into tool-specific filenames.
The key idea is a single source of truth.
Do not maintain multiple divergent instruction files. Normalize on AGENTS.md and bridge outward if needed.
The goal is repository-level portability. Change tools without losing institutional knowledge.
Best Practices for Agent Instructions
To make AGENTS.md effective, follow these constraints.
Write imperatively.
Use direct commands. Avoid narrative descriptions.
Avoid redundancy.
Do not duplicate README content. Reference it.
Keep it operational.
Focus on what the agent must do, not why the project exists.
Update it as the code evolves.
If the build process changes, AGENTS.md must change.
Treat violations as signal.
If agents consistently ignore documented rules, either the instruction is unclear or the file is too long and context is being truncated. Reset sessions and re-anchor.
AGENTS.md is not static documentation. It is part of the execution surface.
Ownership and Governance
If agents are contributors, then their instruction layer requires ownership.
Each module-level AGENTS.md should be maintained by the same engineers responsible for that module. Changes to these files should follow the same review rigor as code changes.
Instruction drift is as dangerous as code drift.
Version-controlled agent guidance becomes part of your engineering contract.
Why Teams Are Adopting AGENTS.md
Repositories across the industry have begun implementing AGENTS.md as a first-class artifact. Large infrastructure projects, developer tools, SDKs, and platform teams are standardizing on this pattern.
The motivation is consistent:
- Eliminate tool lock-in
- Preserve institutional knowledge
- Reduce hallucination caused by ambiguous workflows
- Enable predictable agent behavior across environments
AGENTS.md transforms prompt engineering from a personal habit into a shared, reviewable, versioned discipline.
Vercel published evaluation results showing that repository-level AGENTS.md context outperformed tool-specific skills in agent benchmarks.
Why This Matters Now
AI agents are rapidly becoming embedded in daily development workflows.
Without a standardized instruction layer:
- Output quality varies by developer setup
- Context decays across sessions
- Hidden assumptions leak into production code
- Scaling agent usage multiplies inconsistency
The repository must become the stable contract between humans and machines.
AGENTS.md is the first structural step toward that contract.
It shifts agent collaboration from ad hoc prompting to engineered context.
Foundation Before Optimization
In the next post, we will examine a different failure mode.
Even with a perfectly structured AGENTS.md, long AI sessions degrade. Context accumulates. Signal dilutes. Hallucinations increase. Performance drops as token counts rise.
This phenomenon is often invisible until it causes subtle architectural damage.
Part 2 will focus on defeating context rot and enforcing session discipline using structured planning, checkpoints, and meta-prompting.
Before you scale orchestration.
Before you add subagents.
Before you optimize cost across multiple model providers.
You must first stabilize the environment.
An agent-native repository is the foundation.
Everything else builds on top of it.

From Shadow AI to Full Visibility: Operationalising AI Security at Scale
AI is proliferating across enterprise environments faster than security teams can govern it. From third-party LLM integrations to agentic frameworks like Model Context Protocol (MCP), most organisations have limited visibility into how many AI systems are running, what data they process, or what risks they introduce.
Why AI Security Posture Management Matters Now
Three realities are driving this to the top of the security agenda:
- Rapid, ungoverned adoption: AI integrations enter production through multiple vectors simultaneously - developer experiments, third-party SaaS with embedded LLM capabilities, and MCP servers that expose tools and data sources to autonomous AI agents - often without security review.
- Systemic lack of visibility: Most CISOs cannot accurately answer how many AI APIs are running in their environment. AI integrations do not announce themselves to security teams; they surface in compliance audits and incident investigations months after deployment.
- Sensitive data exposure at the AI layer: Every AI API is a potential data exposure point. Prompts carry confidential business context and personal information. Model responses can surface training data or infer sensitive attributes. Traditional API security tools were not built to address this risk.
Example: Shadow AI in a financial services firm
A quantitative analyst team integrates an LLM into their research workflow. The integration ships as a product feature. Six months later, a compliance review finds the endpoint is externally accessible, processes client PII, and transmits data to a third-party model provider outside the scope of the firm's data processing agreements. The AI system existed, processed regulated data, and created regulatory exposure - entirely outside the security programme's awareness.
The Framework: Discover - Understand - Assess Risk - Operationalise
Effective AI security is not a single capability - it is a continuous workflow across four phases:
01 Discover: Build the Complete AI Asset Inventory
Harness continuously discovers and classifies every AI asset from live traffic and API specifications - no manual registration required:
- AI APIs: endpoints connecting to external LLM providers (OpenAI, Google, Anthropic, Azure OpenAI)
- MCP servers and tools: discrete capabilities exposed to AI agents, including database queries and external API calls
- MCP resources: data sources exposed to AI agents, including files, documents, and structured data that provide context to AI workflows.
- Non-AI APIs: APIs that interact with AI infrastructure - including calls to vector databases and RAG (Retrieval-Augmented Generation) data stores - that form part of the AI data pipeline
Shadow AI found by Harness is risk-scored, ownership-flagged, and surfaced for immediate security review. The finding moves directly into the vulnerability lifecycle with a URL, environment classification, and traffic record.
02 Understand: Map Sensitive Data Flows Across the AI Data Plane
Harness continuously analyzes AI API & MCP traffic to identify sensitive data types flowing through every discovered endpoint:
- Request payloads: prompts, user context, and input parameters carrying PII, financial data, or health information
- Response payloads: model outputs and generated content that may surface training data or infer sensitive attributes
- Third-party boundaries: every inference call to an external LLM provider is a data transfer event; Harness monitors exactly what data crosses the model provider boundary
When sensitive data appears in an AI endpoint for the first time, or is transmitted to an external provider, Harness surfaces a real-time Posture Event - giving privacy and compliance teams the window to act before an exposure becomes a breach notification obligation.
03 Assess Risk: AI-Specific Vulnerability Detection and Risk Scoring
Harness detects AI API & MCP tool vulnerabilities passively from live traffic - no active scanning, no disruption to production AI workloads. Detection covers:
- OWASP API Top 10: applied specifically to AI traffic patterns, including auth weaknesses, excessive data exposure in model responses, and missing rate limiting on LLM endpoints
- MCP-specific risks: tools exposed to the public internet without authentication
- Specification drift: shadow endpoints (traffic but no spec) and orphan endpoints (spec but no traffic) identified by continuous conformance analysis
Risk scoring applies AI-specific weighting: an unauthenticated, externally exposed LLM endpoint is simultaneously a prompt injection target, a data extraction vector, and a compute abuse surface. Scores are dynamic, recalculating as traffic patterns and sensitive data classifications change.
04 Operationalise: Integrate AI Posture into Security Workflows
Harness Posture Events feed connects AI security signals to the workflows security teams already run:
- Jira: vulnerabilities auto-generate tickets pre-populated with endpoint details, CVSS score, and mitigation guidance
- SIEM / SOC: real-time AI threats - prompt injection attempts, DLP alerts, anomalous model behaviour - flow into the SIEM for correlation; Harness provides the characterised asset context before the alert reaches the analyst
- Compliance evidence: every Posture Event is timestamped, filterable, and CSV-exportable, building a continuous audit trail without manual assembly
Custom notifications: privacy teams can alert on sensitive data to 3rd parties; SOC on risk score spikes; governance on new shadow AI assets
Maturity Model: Day 1 - Day 30 - Day 90
AI security posture management is a journey, not a deployment. Here is how organisations evolve:
Enterprise Extension: ServiceNow CMDB Integration
For organisations where CMDB governs asset lifecycle, Harness’s Service Graph Connector extends AI-SPM into ServiceNow. Key use cases:
- Change management: new AI APIs discovered by Traceable trigger a ServiceNow change request in 'Pending Review' state before accumulating production traffic
- Vendor risk: third-party AI providers are represented as vendor CIs linked to DPAs and risk assessment records
- Incident response: SOC analysts work on AI incidents with Traceable's threat intelligence and CMDB's organisational context simultaneously
- Compliance evidence: AI compliance questions answered directly from CMDB records populated by Traceable - no manual assembly
- Decommissioning: orphaned AI endpoints identified by Traceable's conformance analysis trigger governed retirement workflows; Traceable confirms the endpoint has gone dark
The Bottom Line
Operationalising AI security is not about scanning prompts. It is about continuously discovering AI systems, understanding how they access sensitive data, assessing the risks they introduce, and integrating AI posture into the security operations that already exist.
The organisations that build this capability now will govern what others are still trying to find, detect exposures before they become incidents, and answer regulatory questions with data rather than approximation - continuously, not periodically.
When Faster Code Starts to Break the Delivery System
Over the last few years, something fundamental has changed in software development.
If the early 2020s were about adopting AI coding assistants, the next phase is about what happens after those tools accelerate development. Teams are producing code faster than ever. But what I’m hearing from engineering leaders is a different question:
What’s going to break next?
That question is exactly what led us to commission our latest research, State of DevOps Modernization 2026. The results reveal a pattern that many practitioners already sense intuitively: faster code generation is exposing weaknesses across the rest of the software delivery lifecycle.
In other words, AI is multiplying development velocity, but it’s also revealing the limits of the systems we built to ship that code safely.
The Emerging “Velocity Paradox”
One of the most striking findings in the research is something we’ve started calling the AI Velocity Paradox - a term we coined in our 2025 State of Software Engineering Report.
Teams using AI coding tools most heavily are shipping code significantly faster. In fact, 45% of developers who use AI coding tools multiple times per day deploy to production daily or faster, compared to 32% of daily users and just 15% of weekly users.
At first glance, that sounds like a huge success story. Faster iteration cycles are exactly what modern software teams want.
But the data tells a more complicated story.
Among those same heavy AI users:
- 69% report frequent deployment problems when AI-generated code is involved
- Incident recovery times average 7.6 hours, longer than for teams using AI less frequently
- 47% say manual downstream work, QA, validation, remediation has become more problematic
What this tells me is simple: AI is speeding up the front of the delivery pipeline, but the rest of the system isn’t scaling with it. It’s like we are running trains faster than the tracks they are built for. Friction builds, the ride is bumpy, and it seems we could be on the edge of disaster.
The result is friction downstream, more incidents, more manual work, and more operational stress on engineering teams.
Why the Delivery System Is Straining
To understand why this is happening, you have to step back and look at how most DevOps systems actually evolved.
Over the past 15 years, delivery pipelines have grown incrementally. Teams added tools to solve specific problems: CI servers, artifact repositories, security scanners, deployment automation, and feature management. Each step made sense at the time.
But the overall system was rarely designed as a coherent whole.
In many organizations today, quality gates, verification steps, and incident recovery still rely heavily on human coordination and manual work. In fact, 77% say teams often have to wait on other teams for routine delivery tasks.
That model worked when release cycles were slower.
It doesn’t work as well when AI dramatically increases the number of code changes moving through the system.
Think of it this way: If AI doubles the number of changes engineers can produce, your pipelines must either:
- cut the risk of each change in half, or
- detect and resolve failures much faster.
Otherwise, the system begins to crack under pressure. The burden often falls directly on developers to help deploy services safely, certify compliance checks, and keep rollouts continuously progressing. When failures happen, they have to jump in and remediate at whatever hour.
These manual tasks, naturally, inhibit innovation and cause developer burnout. That’s exactly what the research shows.
Across respondents, developers report spending roughly 36% of their time on repetitive manual tasks like chasing approvals, rerunning failed jobs, or copy-pasting configuration.
As delivery speed increases, the operational load increases. That burden often falls directly on developers.
What Organizations Should Do Next
The good news is that this problem isn’t mysterious. It’s a systems problem. And systems problems can be solved.
From our experience working with engineering organizations, we've identified a few principles that consistently help teams scale AI-driven development safely.
1. Standardize delivery foundations
When every team builds pipelines differently, scaling delivery becomes difficult.
Standardized templates (or “golden paths”) make it easier to deploy services safely and consistently. They also dramatically reduce the cognitive load for developers.
2. Automate quality and security checks earlier
Speed only works when feedback is fast.
Automating security, compliance, and quality checks earlier in the lifecycle ensures problems are caught before they reach production. That keeps pipelines moving without sacrificing safety.
3. Build guardrails into the release process
Feature flags, automated rollbacks, and progressive rollouts allow teams to decouple deployment from release. That flexibility reduces the blast radius of new changes and makes experimentation safer.
It also allows teams to move faster without increasing production risk.
4. Remember measurement, not just automation
Automation alone doesn’t solve the problem. What matters is creating a feedback loop: deploy → observe → measure → iterate.
When teams can measure the real-world impact of changes, they can learn faster and improve continuously.
The Next Phase of AI in Software Delivery
AI is already changing how software gets written. The next challenge is changing how software gets delivered.
Coding assistants have increased development teams' capacity to innovate. But to capture the full benefit, the delivery systems behind them must evolve as well.
The organizations that succeed in this new environment will be the ones that treat software delivery as a coherent system, not just a collection of tools.
Because the real goal isn’t just writing code faster. It’s learning faster, delivering safer, and turning engineering velocity into better outcomes for the business.
And that requires modernizing the entire pipeline, not just the part where code is written.

From Artifact Storage to Supply Chain Control: Rethinking Artifact Management with Harness
From Artifact Storage to Supply Chain Control: Rethinking Artifact Management with Harness
Harness Artifact Registry marks an important milestone as it evolves from universal artifact management into an active control point for the software supply chain. With growing enterprise adoption and new security and governance capabilities, Artifact Registry is helping teams block risky dependencies before they reach the pipeline, reduce supply chain exposure, and scale artifact management without slowing developers down.
In little over a year, Harness Artifact Registry has grown from early discovery to strong enterprise adoption, supporting a wide range of artifact formats, enterprise-scale storage, and high-throughput CI/CD pipelines across both customers and internal teams. What started as a focused initiative inside Harness has evolved into a startup within a startup, quickly becoming a core pillar of the Harness platform.
Today, we’re sharing how Artifact Registry is helping organizations scale software delivery by simplifying artifact management, strengthening supply chain security, and improving developer experience and where we’re headed next.
Building a Modernized, Cloud Native Artifact Management
In customer conversations, one theme came up repeatedly: as organizations scale CI/CD, artifacts multiply fast. Containers, packages, binaries, Helm charts, and more end up spreading across fragmented tools with inconsistent controls. Teams don't want just another registry. They want one trusted system, deeply integrated with CI/CD, that can scale globally and enforce policy by default. That's exactly what the Artifact Registry was built to be. By embedding artifact management directly into the Harness platform, it reduces tooling sprawl while giving platform engineering, DevOps, and AppSec teams centralized visibility and control, without slowing developers down.
Artifact Registry: A Unified Home for Every Artifact
Today, Artifact Registry supports a growing ecosystem of artifact types, with Docker, Helm (OCI), Generic, Python, npm, Go, NuGet, Dart, Conda, PHP Composer, and AI artifacts now available, and more on the way. With Artifact Registry, teams can:
- Centralize all artifacts across CI and CD in one platform-native registry
- Scale globally with multi-region replication for performance and resilience
- Simplify migration with built-in tooling to move from existing registries
- Deliver faster, more reliable artifact pulls across environments
The business impact is already clear. Artifact Registry has quickly gained traction with several enterprise customers, driven by strong platform integration, low-friction adoption, and the advantage of having artifact management natively embedded within the CI/CD platform.
One early customer managing artifacts across Docker, Helm, Python, NPM, Go, and more has standardized on Harness Artifact Registry, achieving 100% CI adoption across teams and pipelines.
“Harness Artifact Registry is stable, performant, and easy to trust at scale, delivering faster and more reliable artifact pulls than our previous vendor”
— SRE Lead
By unifying artifact storage with the rest of the software delivery lifecycle, Artifact Registry simplifies operations while helping teams focus on shipping software.
Shifting from Passive Storage to Active Governance
Software supply chain threats have become both more frequent and more sophisticated. High-profile incidents like the SolarWinds breach, where attackers injected malicious code into trusted update binaries affecting thousands of organizations, exposed how deeply a compromised artifact can penetrate enterprise systems. More recently, the Shai-Hulud 2.0 campaign saw self-propagating malware compromise hundreds of npm packages and tens of thousands of downstream repositories, harvesting credentials and spreading automatically through development environments.
As these attacks show, risk doesn’t only exist after a build, it can be embedded long before artifacts reach CI/CD pipelines. That’s why Harness Artifact Registry was designed with governance at its core.
Blocking Risky Dependencies Before They Reach Your Pipeline
Harness Artifact Registry includes Dependency Firewall, a control point that allows organizations to govern which dependencies are allowed into their environment in the first place. Rather than relying on downstream scans after a package has already been pulled into CI/CD, Dependency Firewall evaluates dependency requests at ingest using policy-based controls.
This allows teams to proactively block risky artifacts before they are ever downloaded. Organizations can prevent the use of dependencies with known CVEs or license violations, blocking risky dependencies before they reach your pipeline, and restrict access to untrusted or unsafe upstream sources by default. The result is earlier risk reduction, fewer security exceptions later in the pipeline, and stronger alignment between AppSec and development teams without slowing delivery.
[Dependency Firewall Explainer Video]
Automatically Blocking Risky Artifacts Before Deployment
To further strengthen supply chain protection, Artifact Registry provides built-in artifact quarantine, allowing organizations to automatically block artifacts that fail security or compliance checks. Quarantined artifacts cannot be downloaded or deployed until they meet defined policy requirements, helping teams stop risk before it moves downstream. All quarantine actions are policy-driven, fully auditable, and governed by RBAC, ensuring that only authorized users or systems can quarantine or release artifacts.
Integrating Security into Existing Scanning Workflows
Rather than forcing teams to replace the tools they already use, Harness Artifact Registry is built to fit into real-world security workflows by unifying scanning and governance at the registry layer. Today, Artifact Registry includes built-in scanning powered by Aqua Trivy for vulnerabilities, license issues, and misconfigurations, and integrates with over 40 security scanners, including tools like Wiz, for container, SCA, and compliance checks. Teams can orchestrate these scans directly in their CI pipelines, with scan results feeding into policy evaluation to automatically determine whether an artifact is released or quarantined.
Artifact Registry also exposes APIs that allow external security and ASPM platforms to trigger quarantine or release actions based on centralized policy decisions. Together, these capabilities enable organizations to enforce consistent, policy-driven controls early, stop risky artifacts before they move downstream, and connect artifact governance to broader enterprise security workflows all without slowing down developers.
How Artifact Registry Is Transforming Software Delivery
As organizations scaled, legacy registries have become bottlenecks disconnected from CI/CD, security, and governance workflows. Harness takes a different approach. Because Artifact Registry is natively integrated into the Harness platform, teams benefit from:
- Native CI/CD integration with no extra tooling
- Fast and seamless adoption for existing Harness customers
- Shared visibility across Platform, DevOps, and AppSec teams
- Security enforced early through built-in governance and Dependency Firewall
This tight integration has accelerated adoption by removing friction from day-to-day workflows. Teams are standardizing how artifacts are secured, distributed, and governed across the software delivery lifecycle, while keeping developer workflows fast and familiar.
What’s Next for Artifact Registry?
Harness Artifact Registry was built to modernize artifact management for the enterprise, combining high-performance distribution with built-in security, governance, and visibility. We’ve continued to invest in a platform designed to scale with modern delivery pipelines and we’re just getting started.
Looking ahead, we’re expanding Artifact Registry in three key areas:
Package Ecosystem Expansion
Support is coming for Alpine, Debian, Swift, RubyGems, Conan, and Terraform packages, enabling teams to standardize more of their software supply chain on a single platform.
Governance, Security, and Operational Control
We’re investing in artifact lifecycle management, immutability, audit logging, storage quota controls, and deeper integration with Harness Security Solutions.
AI, Visibility, and Integrations
Upcoming capabilities include semantic artifact discovery, custom dashboards, AI-powered chat, OSS gatekeeper agents, and deeper integration with Harness Internal Developer Portal.
Modern software delivery demands clear control over how software is built, secured, and distributed. As supply chain threats increase and delivery velocity accelerates, organizations need earlier visibility and enforcement without introducing new friction or operational complexity.
We invite you to sign up for a demo and see firsthand how Harness Artifact Registry delivers high-performance artifact distribution with built-in security and governance at scale.

API Failure: 7 Causes and How to Fix Them
What Is an API Failure?
An API failure is any response that doesn’t conform to the system’s expected behavior being invoked by the client. One example is when a client makes a request to an API that is supposed to return a list of users but returns an empty list (i.e., {}). A successful response must have a status code in the 200 series. An unsuccessful response must have either an HTTP error code or a 0 return value.
What Are the Common API Error Codes?
An API will raise an exception if it can’t process a client request correctly. The following are the common error codes and their meanings:
- 400 Bad Request: This error occurs when the client request is malformed or cannot be processed by your API.
- 401 Unauthorized: This error occurs when an API key is missing or incorrectly entered.
- 403 Forbidden: This error occurs when a user tries to access a resource they don’t have permission to see.
- 404 Not Found: This error, also known as a File Not Found error, rarely has anything to do with the API itself but instead with the underlying system (for example, if trying to access a file that doesn’t exist on the server). This is usually related to something else and not directly related to your API code.
- 500 Internal Server: This error occurs when your server can’t respond to a request from a user or can’t find some data (for example, you’re trying to access any post, but none of the posts exist for the given ID).
What Causes API Failure?
An API failure can happen because of issues with the endpoints like network connectivity, latency, and load balancing issues. The examples below may give you a good understanding of what causes an API failure.
1. Incorrect API Permissions
Some APIs are better left locked down to those who need access and are only available to those using an approved key. However, when you don’t set up the correct permissions for users, you can impede the application’s basic functionality. If you’re using an external API, like Facebook, Twitter, or even Google Analytics, make sure you’re adding the permissions for your users to access the data they need. Also, keep on top of any newly added features that can increase security risks.
How to Fix Incorrect API Permissions
If you’re leveraging external APIs requiring extra configuration, get the correct API key so the app has the proper permissions. Also, provide your clients with API keys relevant to their authorization levels. Thus, your users will have the correct permissions and will seamlessly access your application.
2. Unsecured Endpoints and Data Access Tokens
We’ve all seen it happen a million times: someone discovers an API that’s exposed to everyone after gaining user consent. Until now, this was usually reasonably benign, but when credentials are leaked, things can get ugly fast, and companies lose brand trust. The biggest problem here is keeping admins from having unsecured access to sensitive data.
How to Fix Unsecured Endpoints and Data Access Tokens
Using a secure key management system that includes the “View Keys” permission for the account will help mitigate this risk. For example, you could use AWS Key Management Service (AWS KMS) to help you manage and create your encryption keys. If you can’t protect your keys, then at the very least, include a strong master password that all users can access, and only give out these keys when needed.
3. Invalid Session Management
Untrusted tokens and session variables can cause problems for how a website functions, causing timing issues with page loads and login calls or even creating a denial of service, which can harm the end-user experience and your brand.
How to Fix Invalid Session Management
The best way to secure sensitive data is by using token authentication, which will encode user data into the token itself based on time/date stamps. You can then enforce this to ensure that whenever you reissue tokens, they expire after a set amount of time or use them for API requests only. As for session variables, these are usually created based on your authentication keys and should be handled the same way as your privileged keys—with some encryption. And keep the source of your keys out of the hands of anyone who can access them.
4. Expiring APIs
If you’re using an API to power a website, you must upload new data in real time or save it to a cache for later use. When you set an expiry time for an API and fail to update, you make it unavailable. When a user or application tries to access it after the expiry, they get a 404 or 500 error.
How to Fix Expiring APIs
You should use a middle ground option—a proxy API. This will allow you to cache your data before you make it available and only allow access to the correct bits of the APIs as needed. You should also schedule tasks that run daily to import updated data and bring it into your system.
5. Bad URLs
This one isn’t necessarily a mistake, but it happens from time to time when developers aren’t careful about how they name things or if they’re using an improper URL structure for their API endpoints. When the URL structure is too complex or has invalid characters, you will get errors and failures. Look at some examples of bad URL structure: “http://example.com/api/v1?mode=get” The above structure is bad because the "?" character filters a single parameter, not the type of request. The default request type is GET; thus, a better URL would look like this: “http://example.com/api/v1”
How to Fix Bad URLs
Remove any unsafe characters in your URL, like angle brackets (<>). You use angle brackets as delimiters in your URL. Also, design the API to make it more friendly for users. For example, this URL "https://example.com/users/name" tells users they’re querying the names of users, unlike this URL "https://example.com/usr/nm" It’s also good practice to use a space after the “?” in your API URL because otherwise, people can mistakenly think that the space is part of a query string.
6. Overly Complex API Endpoints
This happens when trying to build multiple ways of accessing multiple applications. You do this by relying on generic endpoints instead of target audiences and specific applications. Creating a lot of different paths for the same data results in non-intuitive routes.
How to Fix Overly Complex API Endpoints
There are several ways to go about this, but for most, you want to use a network proxy system that can handle the different data access methods and bring it all into one spot. This will help minimize potential issues with your APIs routes and help with user confusion and brand damage.
7. Exposed APIs on IPs
This can happen when organizations are not properly securing their public IP addresses, or there is no solid monitoring process. This exposes your assets by providing easy access to anyone. Exposed IPs make your application vulnerable to DDoS attacks and other forms of abuse or phishing.
How to Fix Exposed APIs on IPs
Make sure you properly manage your IP addresses and have a solid monitoring system. You must block all IPv6 traffic and enforce strict firewall rules on your network. You should only allow service access through secure transport methods like TLS.
Conclusion
API errors are a plague on the internet. Sometimes they come as very poor performance that can produce long response times and bring down APIs, or they can be network-related and cause unavailable services. They’re often caused by problems such as inconsistent resource access errors, neglect in proper authentication checks, faulty authentication data validation on endpoints, failure to read return codes from an endpoint, etc. Once organizations recognize what causes API failures and how to mitigate them, they seek web application and API protection (WAAP) platforms to address the security gaps. Harness WAAP by Traceable helps you analyze and protect your application from risk and thus prevent failures.
About Traceable
Harness WAAP is the industry’s leading API security platform that identifies APIs, evaluates API risk posture, stops API attacks, and provides deep analytics for threat hunting and forensic research. With visual depictions of API paths at the core of its technology, its platform applies the power of distributed tracing and machine learning models for API security across the entire software development lifecycle. Book a demo today.
The Modern Software Delivery Platform®
Need more info? Contact Sales