Harness Blog
Featured Blogs

AI is writing more of the code. Software delivery, the work between writing code and running it in production, is where most of the day still goes. Building, testing, scanning, deploying, remediating, and operating still require the same, if not more, effort as before AI.
Today, we're introducing Autonomous Worker Agents for software delivery: the platform for enterprises to build and safely run AI agents that handle the work between writing code and shipping it to production.
Autonomous Worker Agents execute as pipeline steps and produce auditable outputs. Their memory is the organization: services, pipelines, deployments, incidents, policies, all connected through the Harness Knowledge Graph, and their capability is powered by the Harness MCP. They operate in production and support the deployment, security, remediation, and validation of your code.
They join Harness Expert Agents, which have been available to customers for some time, to form a complete AI layer across the platform.
Each agent runs as a step inside a Harness pipeline, on customer-controlled infrastructure, with full governance: scoped credentials, OPA policy enforcement, approval gates, and complete audit trails.
Safe to Run in Production
Autonomous Worker Agents are invoked as pipeline steps or independently. They inherit the governance Harness pipelines already provide. Instead of trying to teach an AI agent a massive list of corporate rules, the agent operates entirely within the constraints of your existing software delivery pipelines.
- OPA Policies that gate production deployments gate the agents.
- RBAC that controls who can push to production controls who can trigger an agent.
- Approval Gates apply before an agent's fix ships, just as they do before any release.
Safety is architected in as well. Workloads execute on Harness Delegates, lightweight runtimes installed inside the customer's own Kubernetes cluster or VPC. An agent that "shouldn't be able to merge to main" cannot merge to main, even if its prompt asks it to. The architecture enforces it.
We built RiskSentinel, a Harness Autonomous Worker Agent, to demonstrate that governed AI can move beyond identifying security issues to safely remediate them while maintaining enterprise controls, auditability, and compliance. When building with Harness, what stood out most was how intuitive the experience was — it enabled our team to move from an initial idea to a production-ready agent in just four days, allowing us to focus on solving a real enterprise challenge rather than the underlying platform. That combination of developer experience and enterprise-ready capabilities is what will enable organizations to confidently scale AI across software delivery.
- Ratna Devarapalli, Director IT, United Airlines
Six additional controls make Autonomous Worker Agents production-safe.
1. Sandboxing
Agents are run containerized, with non-root execution (UID 65534, "nobody"). Their filesystem is read-only except for the workspace. Network access is configurable per agent: unrestricted, restricted to allowed MCP servers, or fully disabled.
An agent that produces a malicious bash command has nowhere to send the data.
2. Scoped Credentials
When a pipeline triggers, Harness mints an ephemeral scoped token. Its scope is the intersection of the agent's permissions and the triggering user's RBAC.
Token deletes on completion. TTL as a failsafe. MongoDB TTL index as final backstop.
3. Policy Enforcement
OPA policies, the same framework Harness customers use to govern deployments, apply to agents. Policies govern the agent at runtime and during configuration.
4. Audit Trails
Every execution is captured in the Harness Audit Trail. This includes a full provenance chain: who or what triggered the agent, template version, every action taken, and final outcome.
Prompts and reasoning chains are sanitized before persistence: secrets stripped, and PII is stripped.
5. Cost Tracking
Token consumption and costs are surfaced per execution, per agent, and per pipeline. Running totals are shown live in the step header.
6. Chaining
Agents are architected to run within pipelines and can be naturally composed into multi-step workflows.
- Sequential: Agent B consumes Agent A's output.
- Parallel: agents run simultaneously.
- Conditional: an agent runs only if a previous step meets a condition.
- Matrix: same agent across repos, environments, or services.
Output handoff happens via pipeline expressions and shared workspace files.
Three ways to create an agent
Using YAML
A Worker Agent is defined in a single file. Here's a complete agent that reviews every pull request for security issues:
agent:
group:
steps:
- name: Run Code Coverage Agent
id: runCodeCoverageAgent
if: <+Always>
run:
container:
image: pkg.harness.io/vrvdt5ius7uwygso8s0bia/harness-agents/harness-ai-agent:latest
env:yam
ANTHROPIC_MODEL: ${{inputs.model_name}}
PLUGIN_HARNESS_CONNECTOR: ${{inputs.llm_connector.id}}
PLUGIN_MAX_TURNS: "150"
PLUGIN_MCP_FORMAT: harness
PLUGIN_MCP_SERVERS: <+connectorInputs.resolveList(<+inputs.mcp_connectors>)>
PLUGIN_TASK: |
Autonomous Harness Code Coverage Agent; no prompts. Resolve branch/repo/clone_url/account/org/project/execution strictly: input -> env -> MCP, never guess; branch must exist via SCM MCP or fail.
Use /harness first, else $HARNESS_WORKSPACE; if repo missing, clone (SCM MCP preferred, git fallback) and checkout resolved branch.
Detect language/test/coverage stack, run baseline coverage (overall + per-file), and target >=90% overall and >=80% per-file.
Add meaningful tests for critical uncovered paths (happy/edge/error/boundary); allow only minimal production testability tweaks.
Re-run full tests + coverage + lint + build; all must pass before continuing.
Review full diff (SCM MCP preferred, git diff fallback); allow only tests + minimal testability tweaks (+ COVERAGE.md only if it already exists; never create it).
Build report with overall before->after, per-file before/after for touched files, and key improvements.
Stage files one-by-one only; never use git add -A or git add .; verify staged diff is clean and in-scope.
Create exactly one commit: "Code coverage: automated test additions by Harness AI"; push plain to origin <branch> (no pull/rebase/merge/force).
If push fails, print rejection, git reset --hard HEAD~1, exit non-zero; never commit unrelated changes, never weaken existing tests, never log secrets.YAML frontmatter on top. Natural language below ---. The same convention Jekyll, Hugo, and AI agent definitions across the industry use.
Save the file, commit it to the repo, and the agent is live, governed, and in the catalog. Every PR triggers it. Every run is audited. Every action is scoped by RBAC. From a blank file to a live governed agent in minutes.
The Harness pipeline engine handles container runtime, scoped credentials, MCP server integration, audit logging, and cost tracking.
Using the UI
The Harness Agent Builder is a simple form for configuring your Agents. Define your prompts in plain English, referencing Harness constructs through common expressions. This experience makes it easy to see what you need to provide and set up your agent in minutes.
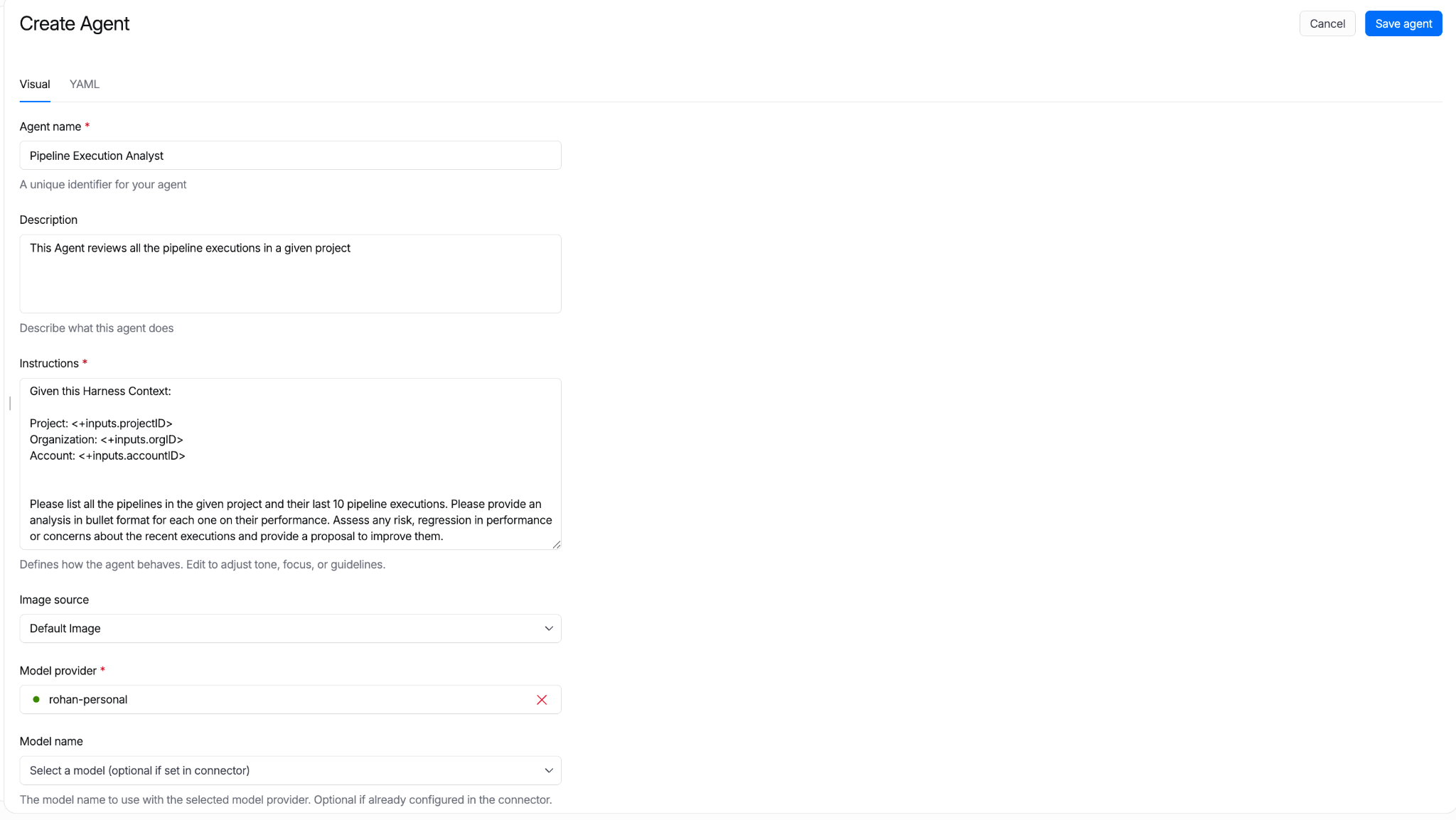
All agent definitions are stored in Harness. Their reference in pipelines can be managed in Git. Approval gates apply. Pipeline Branch-based versions let teams test new agent behavior in feature branches before merging to main.
"We built an agent that handles log analysis directly inside Harness. No tool switching, no context loss. The ability to stay on one platform and have the agent surface what's happening and review it for us was the biggest immediate win. We're planning to use it in production."
- Mandy Pearce, Senior Engineer, Cloud Automation, Verint
Create with MCP
Using your favorite coding agent, you can connect to Harness over the MCP. The MCP bridges the AI Coding agents’ inner-loop context and the outer-loop context and the constructs in Harness.
Agents as Pipeline Steps
Most software delivery workflows have more than one step. Autonomous Worker Agents compose with shell scripts, plugins, approval gates, and other agents to make full pipelines.
Referencing an Agent in a Pipeline
pipeline:
stages:
- steps:
- name: Feature Agent
template:
uses: ca_feature_triage_agent@1.0.2
- name: Plan Agent
template:
uses: ca_work_planning_agent@1.0.2
- name: Build Feature Agent
template:
uses: ca_builder_agent@1.0.2uses: references a Worker Agent template by name and version. The agent runs as one step alongside everything else a Harness pipeline can run.
Sequential: Output Handoff
Agent B consumes Agent A's output. The pipeline expression ${{ steps.<agent_id>.output }} carries the result forward.
pipeline:
stages:
- steps:
- name: spec design
parallel:
steps:
- name: Feature Agent
template:
uses: ca_feature_triage_agent@1.0.2
- name: PR Body
template:
uses: pr_body_writer
with:
artifactPath: ${{featureagent.output.artifact}}
issueKey: cds-1234Parallel
Multiple agents run simultaneously:
parallel:
steps:
- name: Feature Agent
template:
uses: ca_feature_triage_agent@1.0.2
- name: PR Body
template:
uses: pr_body_writer
with:
artifactPath: ${{featureagent.output.artifact}}
issueKey: cds-1234
Step Groups
A Step Group bundles agents and deterministic steps into a single reusable unit:
group:
steps:
- name: feature anaylzer
template:
uses: feature_ingester_agent@1.0.2
- name: work planner
template:
uses: ca_work_planning_agent@1.0.4Save the group as a template. Reference it from any pipeline. The PR Autofix workflow ships as a Step Group template.
Conditional and Matrix
An agent runs only when a condition is met:
- steps:
group:
steps:
- name: feature ingest
template:
uses: feature_ingester_agent
- name: work planner
template:
uses: ca_work_planning_agent
name: Spec Driven Development
if: <+OnPipelineSuccess>The same agent runs across multiple targets:
- name: work planner
template:
uses: ca_work_planning_agent
strategy:
fail-fast: true
for:
iterations: 3Approval gates, failure strategies, retry policies, and rollback work the same way they do for any other pipeline step.
Introducing the Harness Agent Marketplace
The Harness Agent Marketplace is where teams discover, install, fork, customize, and publish Autonomous Worker Agents.
Three publisher tiers anchor it:
- Harness Managed: Built and maintained by Harness. SLA-backed. Versioned. Pinnable (e.g., harness.autofix@1.2).
- Harness Certified: Partner-built. Reviewed and certified by Harness engineering and security. Examples: dependency vendors with their own scanning agents, cloud providers with cloud-specific deployment agents.
- Community: Published by the broader Harness community. Validated for schema, no secrets in prompt. Enterprise accounts can restrict via OPA policy. Allow only Managed and Certified in production, for instance.
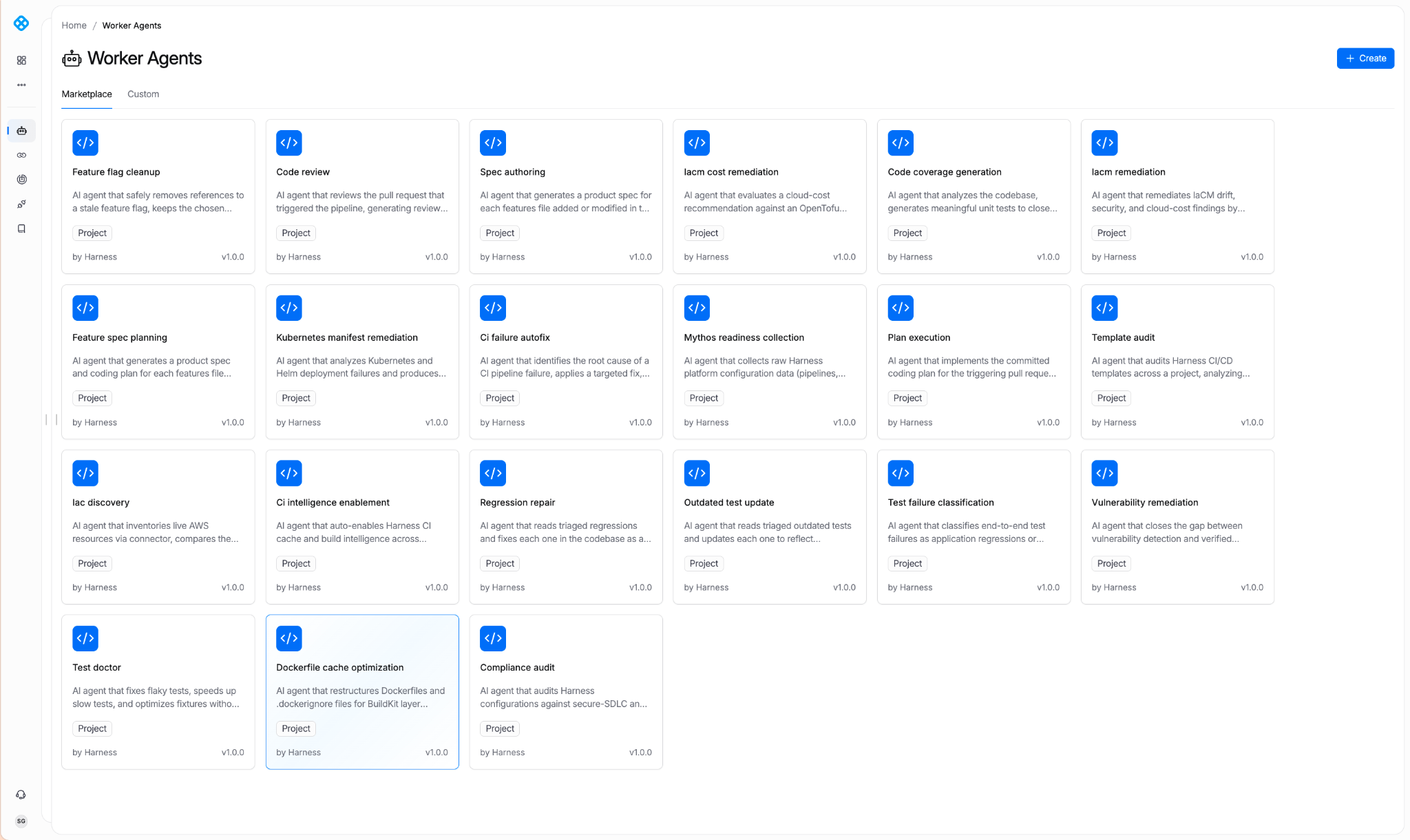
Harness Managed Agents
With today’s launch, Harness has pre-built agents for the most requested use cases. Here are some examples of what’s currently available:
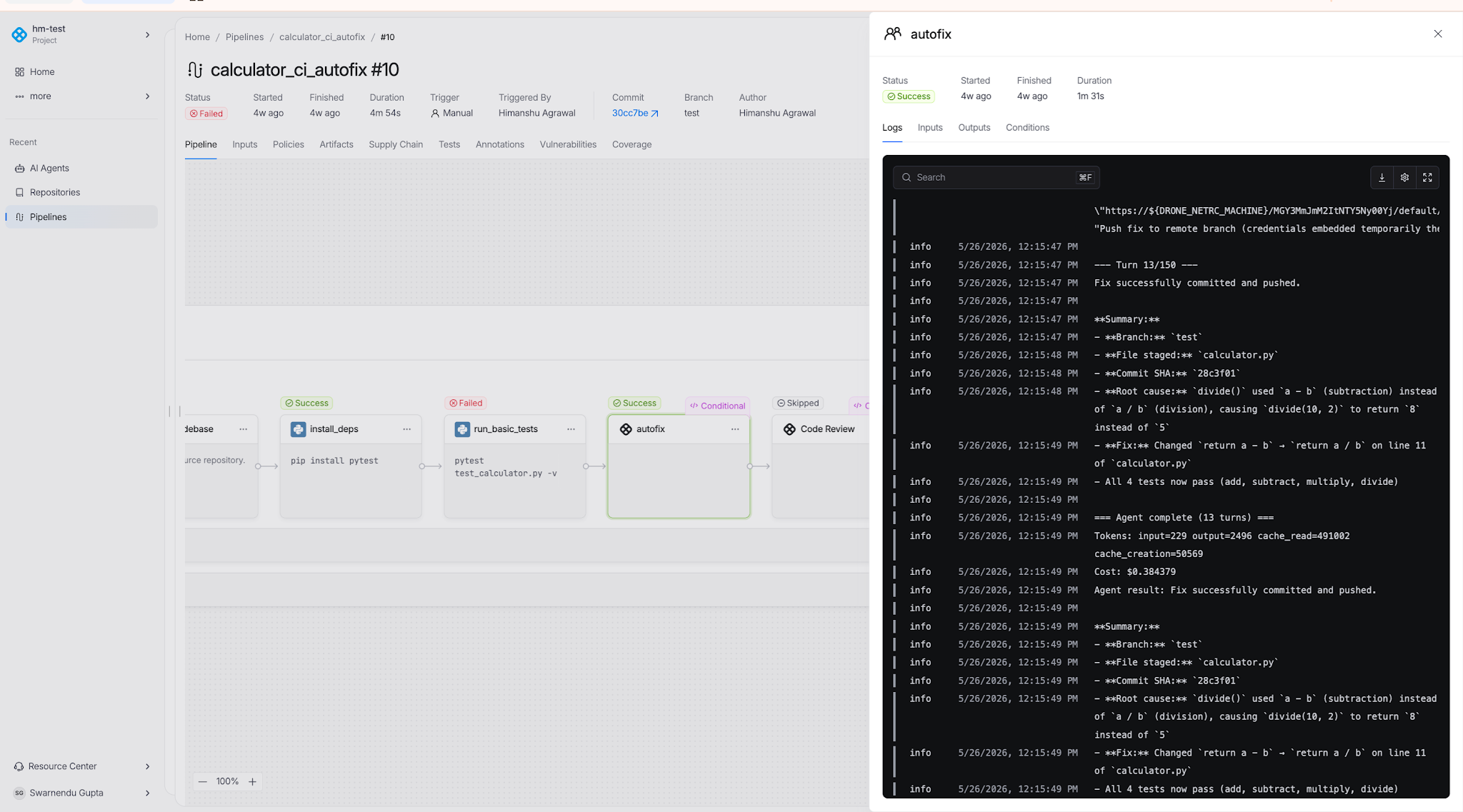
CI Autofix
Reads build logs from a failed PR build, identifies the root cause, commits a fix to the PR branch, re-triggers the build, and repeats until the build passes or the configured max-turns limit is reached.
Manifest Remediator
Analyzes failed Kubernetes deployments. Identifies whether the issue is the manifest, the cluster, or the workload. Fixes manifest issues. Used by teams managing dozens of services across multiple clusters.
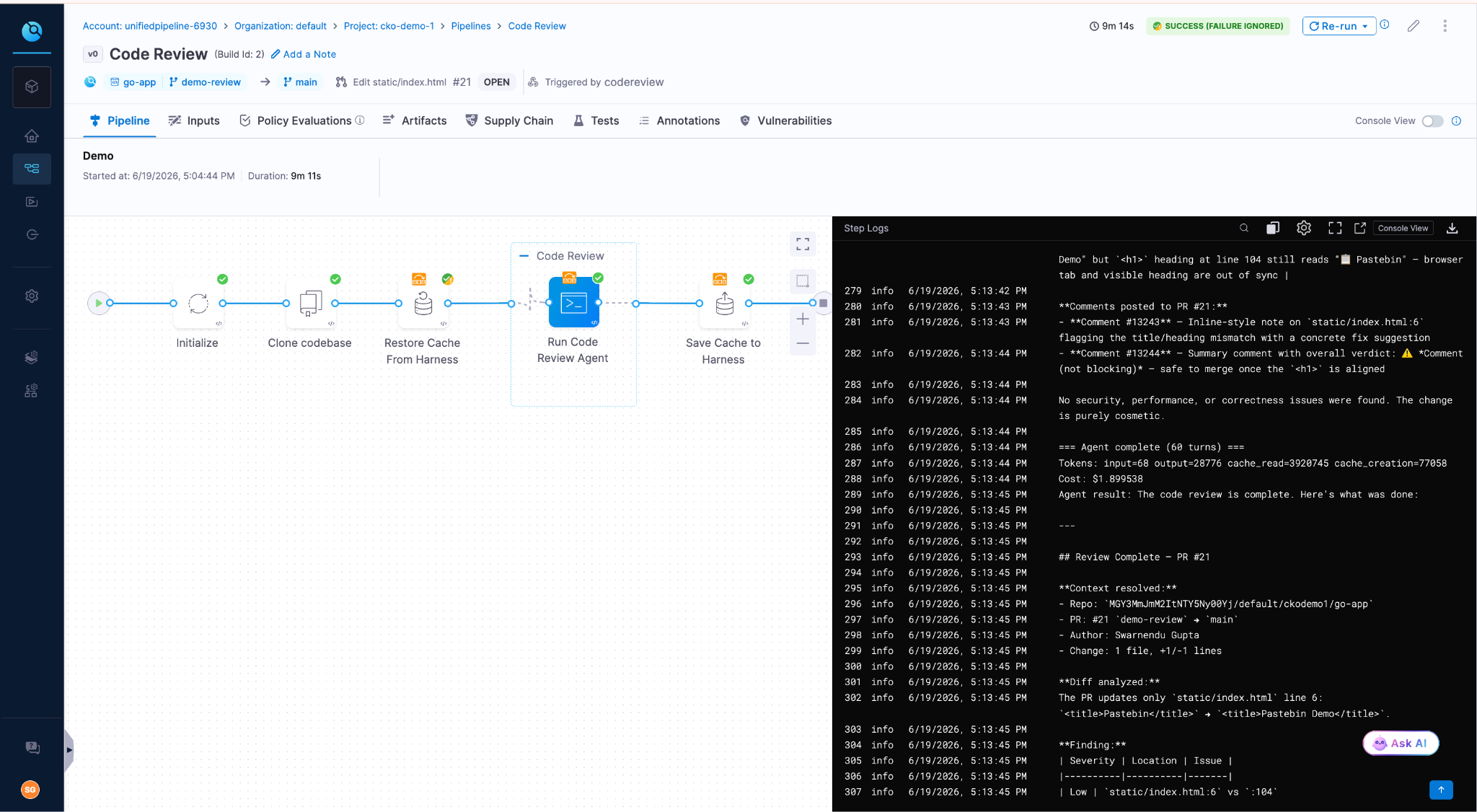
Code Review
Reviews PR diffs across security, quality, and test coverage. Outputs structured findings with severity ratings and concrete remediation. Grounded in the Harness Knowledge Graph, the agent knows which services are production-critical, which have had recent incidents, and which historical anti-patterns have caused outages.
Feature Flag Cleanup
Reads code, config, and flag-system state to identify feature flags that are fully rolled out or fully off. Once it validates removal is safe, the agent generates a cleanup PR. With this agent, the status of your experiments automatically informs you when flags are cleaned up, reducing flag debt and the drudgery of cleaning up old flags.
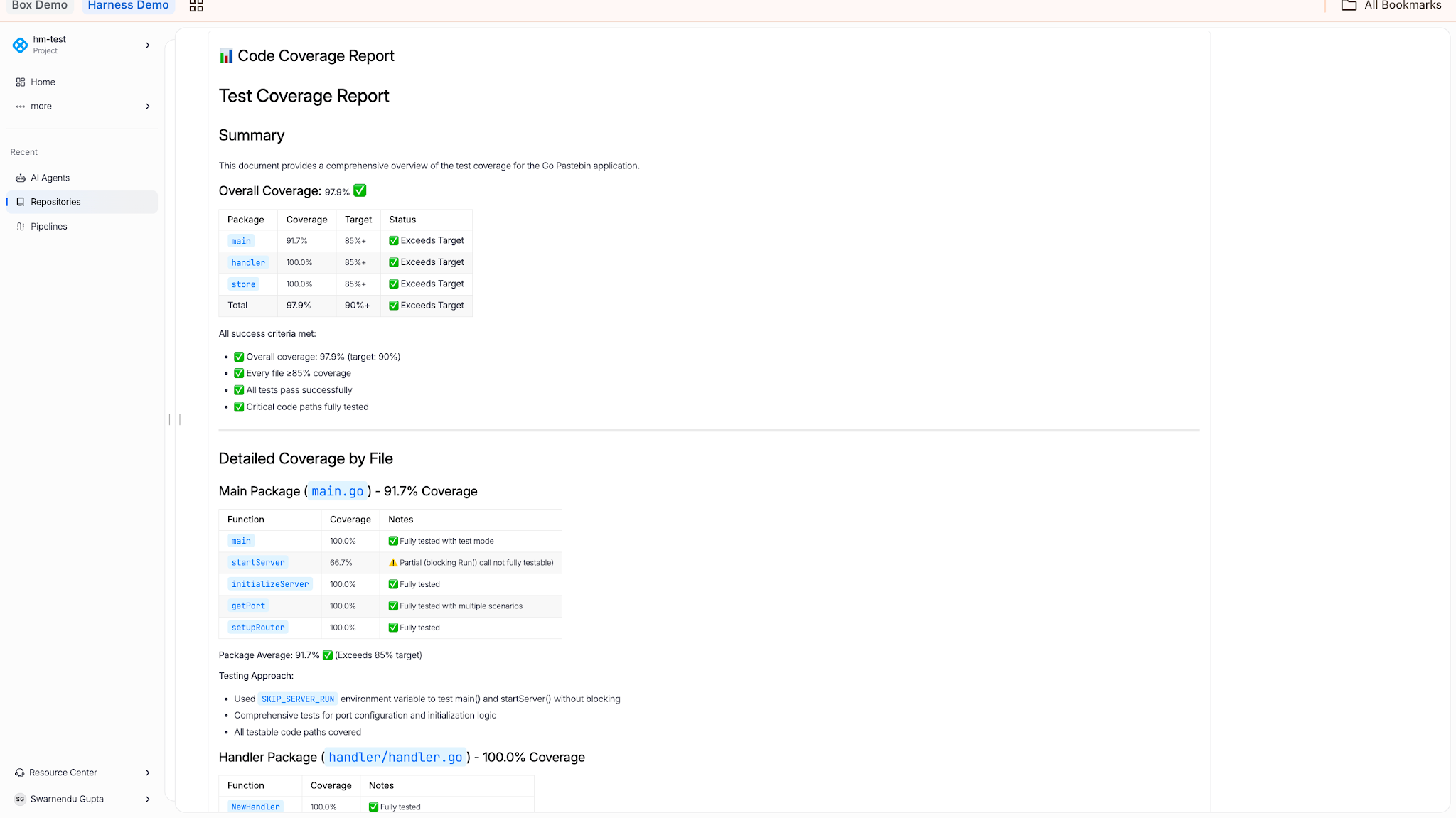
Code Coverage
Reads coverage reports, identifies untested lines, branches, and functions, and generates tests to close gaps. Used when a team has inherited a codebase with weak coverage and needs to lift it before a release.
IaCM Remediation
Fixes configuration drift, security findings, and cloud cost issues by editing infrastructure configurations.
Bring Your Own Model
Autonomous Worker Agents are model-agnostic. Connect LLM providers through Harness connectors:
- OpenAI: Direct to Provider
- Anthropic: AWS Bedrock, Direct to Provider
The model can be specified at three levels: in the agent template, at the pipeline step level (overriding the template), or at the account level via environment variable defaults. Switch models per agent, per environment, or per pipeline without changing agent logic.
Three reasons this matters:
- Cost. Different models have different price points. Routing high-volume work through cheaper models is a common pattern.
- Compliance. Some teams require AWS-routed Bedrock for billing consolidation, VPC routing, or Bedrock-specific compliance attestations.
- Future-proofing. Model leaders change. The enterprise decides which model today, which model tomorrow.
Getting Started
Autonomous Worker Agents are available today for all Harness customers. Learn more about Harness Autonomous Worker Agents or request a demo to see them in production.
Visit the in-app Harness Marketplace in app to try out any of the Worker Agents. Add it to your pipeline and watch it run.

Harness has been recognized as a Leader in the 2026 Gartner® Magic Quadrant™ for DevSecOps Platforms for the third consecutive year. Harness was also positioned furthest on the Completeness of Vision axis in the report.
Our Key takeaways:
- Harness is named a Leader for the third consecutive year
- Harness is positioned furthest on the Completeness of Vision axis
- Harness continues investing in governed, AI-powered DevSecOps
Harness is the AI platform for engineering, security, and operations teams to build, secure, deploy, govern, and optimize software delivery across the SDLC.
We believe our recognition in the Gartner Magic Quadrant for DevSecOps Platforms reflects the continued evolution of the Harness platform and our commitment to helping teams deliver software faster, safer, and with greater governance across the software delivery lifecycle.
We’re thrilled to share this recognition, which we believe reflects the strength of our product strategy, the breadth of our platform, and our continued investment in helping enterprises modernize software delivery with security, reliability, cost management, and AI built into the development lifecycle.
Today, organizations across industries like United Airlines, Ancestry, and Citi rely on Harness to reduce delivery complexity, improve developer productivity, strengthen governance, and accelerate innovation across increasingly complex software environments.
Why This Matters Now
Software delivery has entered a new era. AI coding assistants are helping teams create software faster than ever, but faster code generation also means more changes, more tests, more vulnerabilities, more deployments, and more incidents for organizations to manage. The next era of DevSecOps will not be defined by who can generate code faster. It will be defined by who can safely convert that speed into reliable business outcomes.
Our view is that the future of DevSecOps is autonomous AI agents, governed and directed by expert engineers. As humans and AI agents both contribute to software change, enterprises will need one connected platform to understand, validate, secure, deploy, observe, optimize, roll back, and prove every change across the software delivery lifecycle.
Our Journey
As a pioneer in modern software delivery, Harness offers over 15 platform products and has built one of the industry’s most comprehensive platforms to support the full spectrum of application development, deployment, security, reliability, feature management, cost management, and operations.
Harness has evolved through a combination of product innovation, internal entrepreneurship, open source investment, and strategic acquisitions. We believe our recognition as furthest on the Completeness of Vision axis in the 2026 Gartner® Magic Quadrant™ for DevSecOps Platforms is proof that Harness is solving problems for our customers in a measurable way.
Over the past year, Harness has continued to expand platform capabilities and AI agents across:
- Security and risk management
- AI-native testing capabilities including flaky test detection and AI impact testing
- Feature Management and Experimentation
- Cloud and AI Cost Management
- AI DLC insights
- Resilience Testing, and more
This matters because software delivery is no longer just about building and deploying code. Teams must now manage security risk, release complexity, infrastructure cost, compliance requirements, production reliability, and the growing impact of AI-generated software. The Harness platform allows teams to adopt what they need, when they need it, in one place.
With operations across North America, Europe, APAC, Latin America, and India, Harness serves organizations of all sizes across industries. Customers choose Harness not only for the breadth of the platform but also for the flexibility to adopt individual modules or the full platform based on their needs, maturity, and business priorities.
What’s Next for Harness
This recognition in our opinion is a milestone, and we’re proud, but we’re even more excited by the road ahead.
We build security in the software delivery lifecycle natively, not as a separate stage or disconnected toolchain. As AI increases the volume of code, changes, and security findings, enterprises will need platforms that connect detection, prioritization, policy, remediation, deployment, and runtime defense into a single, governed workflow.
Harness is focused on helping enterprises meet that moment. We will continue investing in AI software delivery to help teams move faster without losing control. Our goal is to help every organization deliver software that is faster to build, safer to release, easier to govern, and more resilient in production.
Thank you to our customers, partners, employees, and community for your continued trust. We’re excited about the journey ahead and can’t wait to show you what’s next.
Learn More
Get a complimentary copy of the 2026 Gartner® Magic Quadrant™ for DevSecOps Platforms.
Or, to talk to someone about Harness, please contact us.
Gartner Disclaimer
Gartner, Magic Quadrant for DevSecOps Platforms, 2026, Keith Mann, Thomas Murphy, Bill Holz, 15 June 2026
Gartner does not endorse any vendor, product, or service depicted in its research publications and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.
GARTNER is a registered trademark and service mark of Gartner, and Magic Quadrant is a registered trademark of Gartner, Inc. and/or its affiliates in the U.S. and internationally, and is used herein with permission. All rights reserved.

TLDR: Today, Harness is introducing the Harness Cursor Plugin, bringing the power of the Harness AI-native software delivery platform directly into Cursor. This integration, along with the Harness Secure AI Coding hook for Cursor, allows developers and AI agents to move from code changes to vulnerability detection, CI/CD execution, security validation, approvals, deployments, and operational insight without leaving the editor.
AI has completely changed how we write code. You can spin up functions, refactor entire files, and generate tests in seconds. The inner loop, writing and iterating on code, has never been faster. But the moment you try to ship that code, everything slows down. This is what we call the AI Velocity Paradox.
You are suddenly back to juggling pipelines, waiting on approvals, checking security scans, debugging failed runs, and bouncing between tools just to get a change into production.
That gap, between fast code and slow delivery, is what we kept running into. So we built something to fix it.
Today, we are introducing the Harness Plugin for Cursor, a way to go from PR to production without leaving your editor.
AI Made Coding Faster, But Delivery Did Not Catch Up
If you are using agentic coding tools, such as Cursor, you have probably felt this.
You can:
- Generate code instantly
- Understand unfamiliar repos faster
- Fix bugs and open PRs in minutes
But shipping still depends on everything outside your editor:
- CI/CD pipelines
- Security checks
- Approval flows
- Policy enforcement
- Deployment tooling
- Monitoring and debugging
And none of that got simpler just because AI showed up. In fact, AI makes the problem more obvious.
Now you can create changes faster than your delivery process can safely handle. And if those controls are not tight, you are introducing a whole new category of risk. Fast-moving code with fragmented governance.
AI did not break software delivery. It exposed how disconnected it already was.
What If You Could Just Ask
Instead of jumping between tools, what if you could just tell your editor what you want to happen?
Something like:
“Deploy PR #4821 to staging once the security scan passes, and Slack me if anything fails.”
That is the idea behind the Harness Cursor Plugin.
It connects Cursor directly to Harness, so you can trigger and manage your entire delivery workflow using natural language, right inside Cursor.
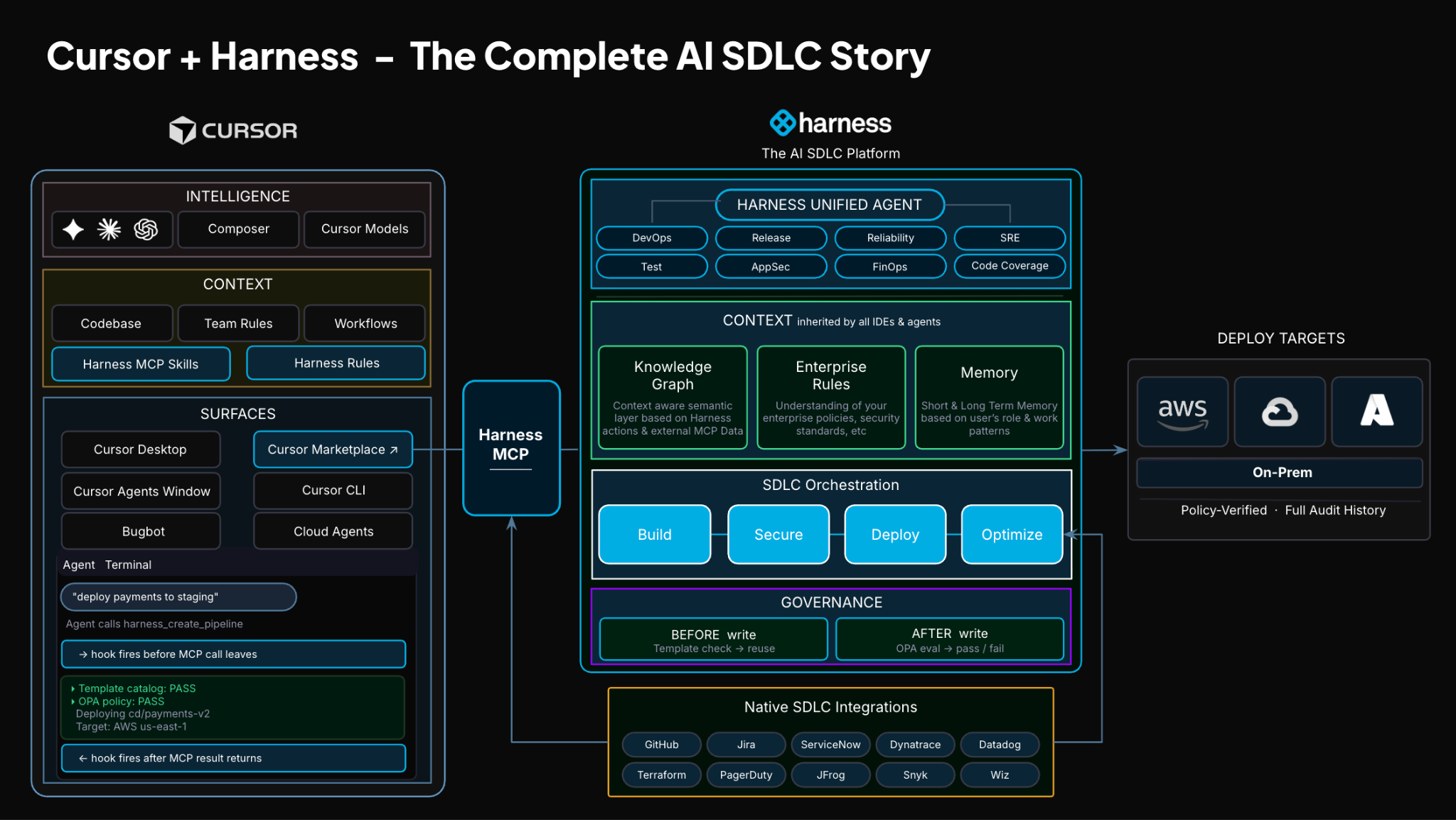
No tab switching. No manual orchestration. No guessing what is happening in the pipeline.
Some Sample Use Cases
Once connected, you can use Cursor to interact with your delivery system just as you do with your code.
For example, you can:

This builds on what we introduced last month, Secure AI Coding, which integrates directly with Cursor and scans code at the moment of generation rather than waiting for a PR review. Developers see inline vulnerability warnings with the option to send flagged code back to the agent for remediation, without leaving their workflow. Under the hood, it leverages Harness's Code Property Graph (CPG) to trace data flows across the entire codebase, surfacing complex vulnerabilities that simpler linting tools would miss.
The key thing is that you are no longer just interacting with code. You are interacting with the entire delivery system from the same place.
The Important Part: This Is Not Skipping Control
One of the biggest concerns with AI in delivery is obvious:
“Are we about to let agents push code to production without guardrails?”
No.
With Harness, everything runs through the controls that you can rely on:
- Granular RBAC permissions
- OPA policies
- Approval gates
- Audit logs
Instead of being manual checkpoints spread across tools, they are enforced automatically as part of the workflow while you stay in flow.
So AI can help move things faster, but it cannot bypass the governance that matters.
Why We Built It This Way
Most integrations today expose APIs or bolt AI onto existing systems. That is not what we wanted to do.
We designed the Harness Cursor Plugin specifically for how AI agents actually work:
- It is built around actions and workflows, not raw endpoints
- It spans the full delivery lifecycle, not just one step
- It gives agents enough context to reason about what to do next
Because shipping software is not a single action. It is a chain of decisions across CI, CD, security, approvals, and operations. If AI is going to help here, it needs access to that full picture. That’s where the Harness Software Delivery Knowledge Graph comes into play. It provides the necessary context for AI to take actions for you.
The knowledge graph models the relationships between services, pipelines, environments, policies, and operational signals in real time. Instead of treating each step in delivery as an isolated task, it creates a connected system of record that AI can reason over. This allows agents to understand not just what to do, but when and why to do it, based on dependencies, risk signals, and historical behavior.

In practice, this means smarter automation: deployments that adapt to context, approvals that are triggered based on policy and impact, and faster root cause analysis because the system already understands how everything is connected.
This Changes How Ideas Move To Prod
This is not just about convenience. It is a shift in how software actually moves from idea to production.
Instead of:
- Writing code in one place
- Managing delivery somewhere else
- And stitching it all together manually
You get a single, connected workflow:
- Code to pipeline to validation to deployment to operations
All accessible from your editor. Cursor accelerates the building. Harness governs the shipping. And the handoff between the two disappears.
Watch the demo:
Getting Started
If you want to try it:
- Install the Harness Cursor Plugin from the Cursor Marketplace
- Authenticate with Harness using OAuth. No API keys or setup headaches
- Start using natural language to run pipelines, debug issues, and manage deployments
For example:
“Run the CI pipeline for this branch, check if the security scan passed, and promote to staging if it did.”
That is it.
AI is not just changing how we write code. It is changing expectations for how fast we should be able to ship it. But speed without control does not work in real environments. What we are building toward is something simpler:
A world where every step, from PR to production, is:
- Fast
- Governed
- Observable
- Auditable
Without forcing developers to leave their flow. This plugin is one step in that direction.
Latest Blogs
.png)
Infrastructure as Code Isn't Enough: Why Database Delivery Must Evolve
- Infrastructure as Code solved infrastructure provisioning, but it did not solve database schema change delivery.
- Database changes are fundamentally different because they modify persistent production state.
- Separate application and database deployment workflows increase operational risk.
- Modern platform teams need version-controlled database schema change delivery with rollback and governance built in.
- AI will accelerate software delivery, making unified delivery workflows increasingly important.
For more than a decade, Infrastructure as Code (IaC) has transformed how engineering organizations build and operate systems.
Infrastructure became programmable, provisioning became repeatable, and configuration became version-controlled.
Teams gained the ability to automate environment creation, enforce policy consistently, and scale infrastructure operations far beyond what manual processes could support.
Yet one critical part of software delivery never fully made the same transition, the database.
As Mrina Sugosh, Senior Product Marketing Manager at Harness, explained during a recent discussion on modern software delivery: infrastructure evolved into a declarative system while database delivery largely remained procedural.
That gap is becoming increasingly difficult to ignore.
Infrastructure Became Programmable. Database Changes Didn't.
Infrastructure as Code introduced a powerful operating model. Instead of manually configuring servers and cloud resources, teams could define desired state in code and let pipelines handle deployment. Tools like Terraform, OpenTofu, AWS CloudFormation, AWS CDK, and Terragrunt let organizations standardize infrastructure management and retire the fragile, hand-run processes that came before.
Platform engineering itself emerged from this shift. Version-controlled infrastructure, reproducible environments, and codified policy became foundational capabilities for modern engineering organizations.
Databases followed a different path. Schema changes, migrations, rollback logic, and data management frequently stayed outside that same delivery framework. The result is a split operating model: infrastructure is automated, applications are automated, and database changes are still done by hand. That separation is where the risk lives.
The Hidden Gap in Modern Software Delivery
Modern systems are no longer simple applications running on servers. They're interconnected ecosystems of applications, databases, APIs, queues, caches, event systems, and infrastructure services, each one depending on the others behaving correctly.
Yet many organizations still deploy these components through separate workflows. A database engineer manages schema changes, a DevOps engineer manages infrastructure, an application team manages deployments, and success depends on those people coordinating rather than those systems coordinating.
Wyatt Munson, Product Education Engineer at Harness, described what that looks like in practice: sitting shoulder to shoulder with a software engineer during a deployment, one person ready to roll back the application and the other ready to roll back the database, both watching for the moment to click at the same time. It worked. But a release that hinges on two people and their timing isn't a delivery model that scales.
Why Database Delivery Is Fundamentally Different
Many organizations assume database delivery should behave like IaC, but the reality is more complicated. Infrastructure provisioning is generally additive and reconstructable: if a virtual machine fails, you recreate it; if a Kubernetes cluster is misconfigured, you rebuild it.
Database changes operate differently because they carry persistent business state. They represent years of accumulated data, application assumptions, indexing strategies, access patterns, and operational dependencies. A schema migration isn't provisioning infrastructure. It's modifying a live system, and even seemingly small changes can ripple outward:
- Dropping a column removes information permanently.
- Index changes affect query performance.
- Schema migrations can impact application behavior.
- Data migrations may create consistency issues across services.
As Munson put it: "At the end of the day, it's the data that's the most important." Losing infrastructure is disruptive. Losing data is catastrophic.
The GitHub Incident That Exposed the Problem
The risks of database delivery aren't theoretical. One example discussed during the webinar was a GitHub production database migration. A migration removed a column believed to be unused, but parts of the application still referenced that column through a separate ORM path. After the change deployed, GitHub saw elevated error rates across pull requests, push operations, notifications, webhooks, and API traffic.
The failure wasn't really the migration itself. It was that the database change and the application that depended on it were validated separately rather than together. The migration was checked as a migration and the application was checked as an application, but the two were never exercised as one system before the change reached production. So the dependency stayed invisible until it broke in front of customers.
This is the gap a unified delivery model is built to close, and it closes it in two places:
- Catch it in pre-prod. Had the schema change and the application deployed together into a production-like environment, spun up on demand with Infrastructure as Code, the same errors that surfaced in production would have shown up there first, against real application behavior, where they cost nothing.
- Gate it before prod. A destructive change like dropping a production column should pass through a policy gate before it ever reaches production, held for explicit review and ideally backed by proof that it cleared QA without breaking anything.
Three Requirements for Modern Database Delivery
1. Version Control Database Changes
Database changes should be managed like application code, through version control and GitOps. That gives every change traceability, auditability, and a documented history: who made it, why, and when it shipped. The same properties that make application code reviewable and repeatable apply just as well to a schema migration.
2. Automate Validation and Rollback
Database delivery needs more than deployment automation. Before a change reaches production it should go through:
- Validation against a realistic environment, so problems surface in pre-prod, not prod.
- Schema and migration testing as part of the pipeline.
- Environment promotion, the same staged path application code follows.
- A defined reverse path: a reviewed rollback where the change can be cleanly undone, a tested forward-fix where it can't.
The goal is to remove uncertainty before a change ships, not to rely on an emergency undo after it's already in production.
3. Unify Delivery Workflows
The biggest opportunity is bringing infrastructure, application, and database delivery into a single operational framework. Instead of coordinating separate workflows by hand, platform teams orchestrate them through one pipeline, so application deployment, infrastructure provisioning, and database migration run as a single coordinated motion, governed consistently rather than stitched together by hand.
From Infrastructure as Code to Delivery as Code
The next phase of platform engineering extends the code-driven model beyond infrastructure to delivery itself. Call it Delivery as Code: the principles that made infrastructure programmable, applied to how every change ships, databases included.
In practice that means three things.
Database Pipelines
Database changes move through controlled promotion workflows rather than ad hoc scripts, so each one is reviewed, tested, and promoted environment to environment like application code.
Policy Enforcement
Governance gets codified through policy engines such as Open Policy Agent, so the rules that used to live in someone's head become enforceable at the pipeline:
- No dropping production tables
- No violating naming standards
- No deploying unapproved schema changes to prod
AI-Assisted Operations
AI begins to absorb the repetitive operational work, helping draft migration definitions and validation checks so engineers spend less time on boilerplate and more on the changes that actually need judgment.
The goal isn't replacing engineers. It's removing the repetitive operational toil so they can focus on higher-value work.
Building a Unified Delivery Platform
Platform teams are facing a new reality. AI-generated code is increasing development velocity dramatically, and more changes are entering delivery systems than ever before. When application deployment is automated but database delivery stays manual, the database becomes the bottleneck, and the fix isn't more coordination meetings. It's a unified delivery model where:
- Infrastructure changes are version-controlled.
- Database changes are version-controlled.
- Governance is codified.
- Testing is automated.
- Rollbacks are built into workflows.
That's a delivery system that can scale alongside modern software development. Infrastructure as Code was the first step. Database DevOps is the next one.
Conclusion
Infrastructure as Code fundamentally changed software delivery by making infrastructure programmable.
But modern systems are more than infrastructure.
Applications, databases, policies, and delivery workflows must operate as a coordinated system.
As software delivery accelerates—particularly with the rise of AI-generated code—database delivery can no longer remain a separate operational process.
Platform teams that unify infrastructure, application, and database workflows will be better positioned to deliver software faster, safer, and with greater operational confidence.
Ready to see how Harness helps platform teams bring database delivery into the modern software delivery lifecycle? Explore Harness Database DevOps and Infrastructure as Code Management.
FAQ
What is Database DevOps?
Database DevOps applies DevOps principles to database changes, including version control, automation, testing, governance, and CI/CD workflows.
Why isn't Infrastructure as Code enough for databases?
Infrastructure as Code manages infrastructure state but does not address schema changes, data migrations, rollback workflows, or database governance.
Why can database changes be riskier than infrastructure changes?
Database changes modify persistent production data. Unlike infrastructure resources, databases often cannot be recreated without business impact.
How does Database DevOps improve software delivery?
It enables automated testing, version-controlled changes, rollback capabilities, and coordinated application and database deployments.
What role does GitOps play in database delivery?
GitOps provides version control, auditability, and workflow automation for database schema changes and migration management.
Can Harness DB DevOps be integrated into CI/CD pipelines?
Yes. Database DevOps integrates natively with Harness Continuous Delivery, so schema management, validation, and rollback run as steps in the same pipeline as your application deployments. If you run a different CI/CD tool, those same capabilities can be invoked from your existing pipelines instead.
How does Harness AI help database delivery?
Harness has an AI powered schema authoring capability, which can assist with migration generation, so engineers spend less time on boilerplate and more on the changes that need real judgment. Governance and approval controls stay in place regardless of how a change was authored.

Zero-Downtime Database Migrations: Patterns for Safe Schema Evolution
Database migrations are rarely just about changing schema. In real production systems, every migration has to preserve three things at the same time: application availability, data consistency, and compatibility across versions. That is the hard part.
When teams say they want “100% uptime,” what they usually mean is no planned downtime during deployments and no user-visible interruption while the application and database are evolving. That goal is realistic, but only if the migration strategy is designed around compatibility from the start.
The Real Objective: Compatibility First, Cleanup Later
A migration should never assume that the new application version is the only code touching the database. During a rolling deployment, blue-green cutover, or staged rollout, both versions may run side by side for a period of time.
That creates a simple rule: “Every schema change must be safe for the current app version and the next app version.” If your schema is not designed for this overlap, you introduce:
- Runtime failures
- Data inconsistencies
- Forced downtime
The solution is not complex tooling, it's the correct migration strategy. Since the safe database migration is not just “correct” - it must be compatible across versions.
- Old application must continue to work
- New application must start working immediately
- Database must support both during rollout
- Database must ensure both versions of the application always see the same data, must ensure data integrity even while writing in it.
This is the foundation of zero downtime database migration.
Migration Patterns that Work in Production
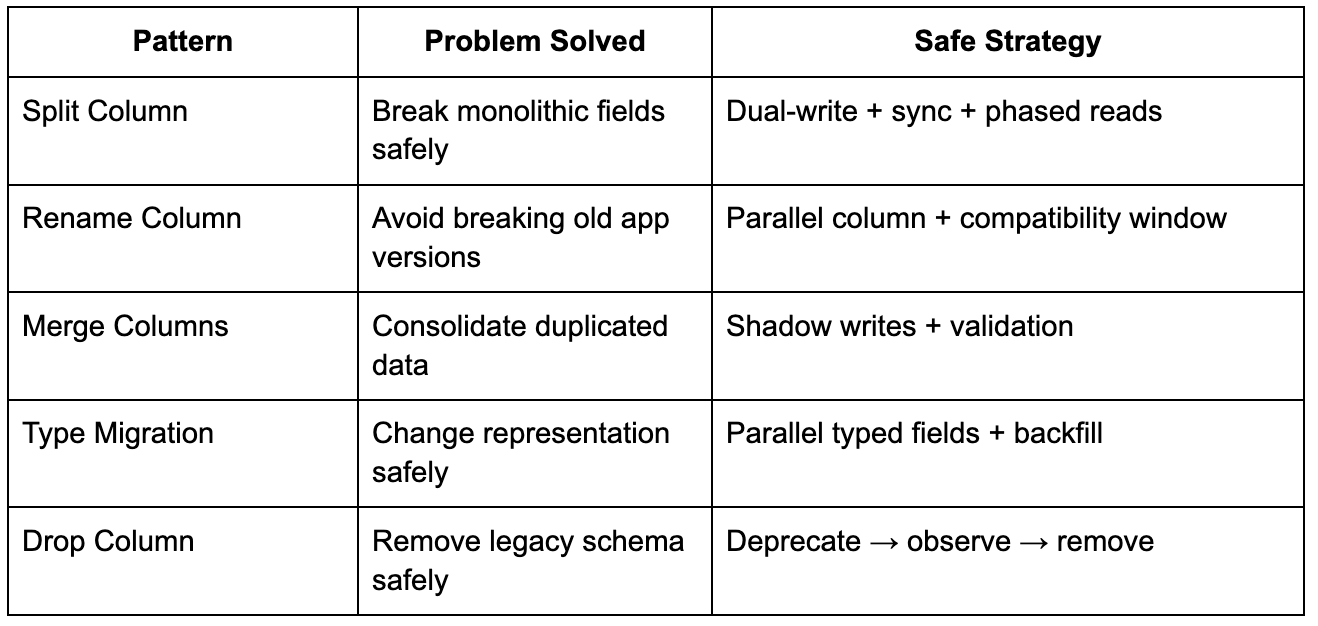
These patterns follow the same rule: never break existing reads or writes during transition.
The Safest Rollout Sequence
This is the real test of a safe migration. The old version may still:
- Read a deprecated column,
- Expect a legacy enum value,
- Or write a field that the new version no longer prefers.
The new version may:
- Depend on a new column,
- Expect a new constraint,
- Or write into a split schema.
To support both, design the transition so that:
- The old app still sees valid data,
- The new app can start using new structures immediately,
- And the schema does not force an all-or-nothing deployment.
That is why additive changes and compatibility windows matter more than raw speed. This aligns with real-world pipelines where schema and application changes are decoupled but coordinated.
Keeping Old and New Structures in Sync
During migration, both schema versions may remain active simultaneously.
This creates a synchronization window where:
- Old application versions may still write legacy fields,
- New versions may write updated structures,
- And both new and old representations must remain consistent.
Common synchronization approaches include:
- Database triggers,
- Change data capture (CDC),
- Tansactional dual writes,
- Event-driven synchronization pipelines.
Without synchronization safeguards, post-migration edits can cause data divergence between old and new schemas.
A Practical Deployment Pattern That Mirrors Real Pipelines
Your pipeline example reflects the same deployment philosophy: application rollout, schema application, and controlled progression are separated into explicit steps rather than collapsing everything into one risky event. That is exactly the kind of sequencing needed for production-safe migrations.
In a mature release process, a database migration stage should be treated as a release gate, not a side effect. The schema change should happen only when the release pipeline has proven that the next application version can coexist with the previous one.
That is how you preserve uptime without gambling on runtime behavior.
What Is the Expand-and-Contract Pattern?
The expand-and-contract pattern is a phased migration strategy used to evolve database schemas safely without downtime. It works in three stages:
- Expand - Introduce new schema structures without removing old ones.
- Migrate - Keep old and new structures synchronized while applications transition.
- Contract - Remove deprecated schema only after all traffic has migrated.
This allows both old and new application versions to operate safely during deployment.
Best Practices for Zero Downtime Database Migrations
Key best practices for zero downtime database migrations include:
- Use the expand-and-contract pattern
- Avoid destructive changes during active deployments
- Ensure backward and forward compatibility and ensure both versions of the app will always see the same data.
- Run idempotent, incremental backfills
- Monitor and validate data consistency continuously
These practices minimize risk and ensure smooth production rollouts.
Frequently Asked Questions
1. How can I migrate a database without downtime?
To migrate a database without downtime, use a phased, backward-compatible approach:
- First, apply non-breaking schema changes (add columns, avoid deletions)
- Perform background data backfills in small batches
- Release the updated service version utilizing synchronized dual-write operations.
- Gradually shift reads to the new schema
- Remove old schema only after all traffic is migrated
This approach ensures continuous availability during the migration process.
Application-layer dual writes alone do not guarantee consistency. Failures between writes, retries, or partial transaction completion can still introduce divergence between old and new structures. In relational systems, teams often use triggers, CDC pipelines, or transactional synchronization to reduce drift risk during migration windows.
2. What is backward compatible schema design in database migrations?
Backward compatible schema design means structuring database changes so that existing application versions continue to function without modification.
For example:
- Adding a nullable column is backward compatible
- Renaming or dropping a column is not
This is critical during rolling deployments where multiple application versions interact with the database simultaneously.
3. What are the risks of database schema changes in production?
Common risks of database schema changes in production include:
- Breaking compatibility with running application versions
- Causing downtime due to locks or blocking queries
- Data inconsistency can also occur when edits continue in the old schema after migration, but synchronization mechanisms fail to propagate those updates into the new structure.
- Making rollback difficult or unsafe
These risks can be mitigated by using safe migration patterns, staged rollouts, and compatibility-first database design. For example, if a trigger, CDC stream, or synchronization process misses an update, the old and new representations may diverge silently.

DevOps Tools List: The Only Stack You Need in 2026
What is a DevOps tools list (and what should it include)?
A DevOps tools list is the set of tool categories spanning the software delivery lifecycle, source, build, test, secure, deploy, and operate, that a team assembles into a working stack. A complete list covers every stage from code to production; a good one covers them with as few disconnected tools as possible. In 2026, the useful question is not how long the list is, but how few seams sit between the tools on it.
A new engineer joins a team and asks for the DevOps tools list. What comes back is a 22-line inventory: a source host, two CI systems, an IaC engine, a registry, three scanners, a deployment tool, a couple of dashboards, and nobody who can fully explain how they all connect. That inventory is the team's DevOps tools list, and its length is often mistaken for its strength.
A DevOps tools list is the connected set of tools spanning the software delivery lifecycle (source control, build, test, security, deployment, and operations) that a team assembles to move software from code to production safely and reliably. A useful DevOps tools list covers every stage with as few disconnected tools as possible. The goal is not the longest list. It is the smallest unified stack that lets teams ship faster and safer.
What is a DevOps tools list and what are the best DevOps tools and devops pipeline tools?
A functional DevOps tools list covers nine stages. Each stage has multiple options, but the principle is the same: choose devops pipeline tools that integrate well, then consolidate the integration points.
The categories matter less than the integration. CI that shares a policy layer with your CD platform and security testing is more valuable than three best devops tools with no shared context. The Internal Developer Portal is what surfaces these as golden paths developers self-serve on, rather than ticket queues they wait on.
What changed about the DevOps tool stack in 2026?
The categories above are not new. What changed in 2026 is the cost of how they are connected. AI moved into code creation, so more change flows through every stage—and the seams between separately chosen tools, each with its own access model and audit trail, became the place where governance and context break down. The list got longer; the gaps between its items got more expensive.
A useful DevOps tools comparison isn’t product-versus-product, it’s two ways of assembling the stack. The table below frames that DevOps tools comparison directly: the longer list against the right stack.
Why the longest DevOps tools list slows teams down
It is tempting to read a long tools list as a mature one. But each tool added to the list is another integration to maintain, another audit trail to reconcile, and another point where a security or quality check can be skipped. As AI raises the volume of change moving through the stack, those seams are exactly where speed turns into risk—the pattern Harness calls the AI Velocity Paradox.
Key data: Harness research (State of AI in Software Engineering 2025) shows 71% of teams say context-switching between tools drains productivity, and 73% of engineering leaders report barely any teams have standardized golden paths.
So the honest answer to "what's the best DevOps tools list" is not a longer list. It is a list short enough to govern consistently and complete enough to cover every stage—which usually means consolidating, not collecting.
What does the only DevOps CI CD tools stack you need in 2026 look like?
The answer is not a specific list of vendor names. It is a set of principles that any good DevOps tools list should satisfy.
- One policy engine across all stages. Governance should not vary by tool. A deploy gate in CD should enforce the same rules as a security gate in CI.
- One audit trail. Every change, approval, and rollback should be traceable in one place, not reconstructed from five different log systems.
- One data model. Delivery insights should span the full lifecycle so you can answer questions like why did deployment frequency drop this sprint without crossing four dashboards.
- Self-service with guardrails. Platform teams define the golden paths; developers execute them without filing tickets. This is what the Internal Developer Portal exists to provide.
- AI that acts on the pipeline. Not an AI sidebar you paste answers from but a system that selects tests, diagnoses failures, generates pipelines, and remediates incidents within governed guardrails.
Key Distinction: The only stack you need is not the longest tools list—it's the smallest set of governed categories that covers the lifecycle without sprawl. A consolidated stack that shares governance beats a longer one whose tools don't.
How Harness approaches the DevOps stack
The challenge
Platform teams are asked to give developers fast, self-service delivery while maintaining governance and reliability. As AI accelerates code output and tools accumulate, the after-code stages (testing, securing, deploying, operating) fragment across products with no shared context or governance. The platform team ends up maintaining integration seams instead of improving delivery.
The approach
Harness is the AI-native Software Delivery Platform that automates and governs everything after code is written. The Software Delivery Knowledge Graph ties each build, deployment, and security event back to the service and commit it came from. On that foundation sit the after-code modules: Continuous Integration, Continuous Delivery and GitOps, the Internal Developer Portal, Infrastructure as Code Management, Application Security Testing, AI SRE, AI Test Automation, and Cloud and AI Cost Management. Each inherits shared access control, governance, and a single audit trail. Developer-friendly guardrails.
The outcome
Consolidating the stack onto one governed platform helps reduce the governance gaps and integration toil that sprawl creates, accelerates remediation when something breaks, and lets teams ship faster and safer as AI raises the volume of change. The aim is not the longest tools list, but the smallest one a team can govern with confidence.
See how teams have simplified their stacks.
What does a consolidated DevOps stack look like in practice?
Two teams, two different sprawl problems, one outcome: consolidation returns engineering time to the work that actually needs it.
How did OneAdvanced enable 700 engineers with one governed DevOps tools list?
OneAdvanced managed over 100 product teams and 700-plus engineers deploying across six data centers, each with a different combination of Jenkins, CloudFormation, Octopus Deploy, Puppet, and Bash scripts. Pipelines took 3 to 30 hours to execute. Consolidating onto Harness CD gave every team self-service deployment on one governed platform. Average deployment time fell 88% from 2 days to 2 hours.
“We've conservatively saved 50 to 60% of total DevOps and engineering time spent on deployments and our previous CI/CD process.”
Martin Reynolds, DevOps Manager, OneAdvanced
Source: OneAdvanced enables 700 engineers with Harness
How did Deluxe standardize CI/CD pipelines across a fragmented devops tool stack?
Deluxe, a payments and data leader, had grown a wide technology footprint. Teams relied on custom scripts, multiple tools, and no centralized governance. Adopting Harness gave Deluxe standardized CI/CD templates and centralized governance across teams. Pipeline setup time dropped from days to under 30 minutes using reusable templates.
“With Harness CD, one of the biggest improvements is the confidence we have in deployment. Gates ensure only the right things are deployed, and rollback scripts are already embedded.”
Pankaj Gupta, Executive Director of Enterprise Architecture, Deluxe
Source: Deluxe reduces CI/CD pipeline setup time with Harness
Build the DevOps tools list that scales, not the longest one
The best DevOps tools list is not the most comprehensive. It is the one where fewer, well-integrated devops pipeline tools replace fragmented point solutions, and where adding the hundredth team costs about what adding the tenth did. Start from the governance gaps: find the stages where your audit trails break, where approvals depend on a human remembering a step, where a deploy needs someone to watch a dashboard. Those are the integration seams worth removing.
A unified platform covering the after-code lifecycle with shared governance, golden paths, and AI-native automation is how teams absorb AI-generated code at machine speed without losing control of what ships.
See how Harness brings the full after-code lifecycle onto one platform.
FAQs about the DevOps tools list
What is a DevOps tools list?
A DevOps tools list is the connected set of tools spanning the software delivery lifecycle: source control, CI, artifact management, security testing, CD, infrastructure, observability, and cost management. The goal is not the longest list but the smallest unified stack with shared governance that lets teams ship faster and safer.
What tools are needed for a DevOps pipeline?
At minimum: source control, CI (to build and test), artifact registry, CD (to deploy), infrastructure automation, security scanning, and observability. Everything else is additive. Start with these and add based on actual pain in your devops pipeline tools, not theoretical coverage.
What are the best DevOps tools in 2026?
The best DevOps tools are the ones that reduce toil, integrate with your existing stack, enforce governance by default, and scale without requiring a complete overhaul. Tools that deliver automation, observability, and governance in one place outperform best-of-breed stacks that create integration seams between every stage.
Do you need a separate tool for every DevOps stage?
No. A separate tool for every stage was the default in 2015. In 2026, unified platforms cover multiple stages with shared context, shared access control, and shared audit trails. The integration toil between separate tools is often more expensive than any capability gap a platform might have.
What is the difference between a DevOps tools list and a DevOps platform?
A DevOps tools list is what you have: an inventory of tools covering different stages. A DevOps platform is what you want: a system where those stages share context, permissions, and governance so every team can self-serve safely. The platform makes the tools list smaller and the outcomes better.
How many DevOps tools does a team need?
Fewer than most teams currently run. The average team uses 8 to 10 AI tools and up to 30 across the full SDLC. The goal is sufficient coverage with minimal integration seams and one governance layer across all of them. Consolidating by two or three tools typically reclaims significant engineering time.

DevOps Platform Explained: Why Unified Wins Over Siloed Tools
What is a DevOps platform?
A DevOps platform is an integrated software delivery system that manages the entire software development lifecycle (SDLC)—from source code and continuous integration (CI) to deployment, security, infrastructure, and operations. Unlike standalone DevOps tools that solve individual problems, a DevOps platform connects teams, workflows, and delivery processes in a single environment, providing shared automation, governance, and visibility.
A DevOps platform is becoming the standard answer to a gap that keeps widening: software development is accelerating, but software delivery is not keeping pace. AI is helping engineering teams write code faster, yet moving that code safely from commit to production still depends on build pipelines, security checks, deployment workflows, governance, and cross-team collaboration.
This gap is becoming more apparent as organizations adopt AI. The 2025 DORA State of AI-assisted Software Development report finds that AI amplifies an organization's existing strengths and weaknesses. Teams see the greatest benefits not from AI alone, but from strong internal platforms, well-defined engineering workflows, and effective collaboration.
That is why organizations are rethinking fragmented DevOps toolchains. Instead of relying on disconnected tools stitched together with custom integrations, many are adopting DevOps platforms that unify software delivery into a single system. The result is faster releases, stronger governance, and better visibility across the software development lifecycle.
In this guide, you will learn what a DevOps platform is, how it differs from a standalone DevOps pipeline, and what capabilities to look for when evaluating one for your organization.
What is the difference between a DevOps pipeline and a DevOps platform?
A DevOps pipeline is a single automated workflow, such as building and deploying an application. A DevOps platform manages and orchestrates multiple pipelines while connecting the people, policies, tools, and processes required to deliver software reliably at scale.
The distinction becomes more apparent as engineering organizations grow. Individual DevOps pipeline tools can address specific stages of software delivery, but coordinating workflows, enforcing governance, and maintaining visibility across multiple teams becomes increasingly difficult when every capability operates in isolation.
Siloed Tools vs Unified DevOps Platform. What's the Real Difference?
Standalone DevOps tools are designed to solve specific challenges, whether it is source code management, CI/CD, security testing, or infrastructure automation. As engineering organizations grow, however, connecting these tools through custom integrations, scripts, and manual processes can increase operational complexity. A unified DevOps platform brings these capabilities together into a single software delivery system, creating consistent workflows, centralized governance, and shared visibility across teams.
Fragmented toolchains introduce accidental complexity. As engineering organizations scale, teams spend increasing amounts of time maintaining integrations, troubleshooting workflow failures, and synchronizing data across multiple systems instead of improving software delivery. Over time, this creates integration debt, increases operational overhead, and makes it harder to standardize software delivery across the organization.
What are the hidden costs of siloed DevOps tools?
Specialized DevOps tools solve specific problems well, but they are not designed to operate as a single software delivery system. As organizations adopt more tools, engineering teams must maintain integrations, synchronize data, enforce consistent policies, and switch between multiple interfaces to complete everyday tasks.
Over time, this creates integration debt and operational complexity. Instead of improving delivery processes, platform teams spend valuable engineering effort maintaining the toolchain itself. The result is slower releases, inconsistent governance, limited visibility, and a developer experience that becomes increasingly difficult to scale.
What does a unified platform change?
A unified DevOps platform shifts engineering effort from maintaining tools to improving software delivery. Instead of coordinating work across disconnected systems, teams operate from a common delivery framework with standardized workflows, consistent governance, and shared operational context.
The benefits extend beyond operational efficiency. For example, Ancestry reduced pipeline maintenance by 85%, increased deployment frequency 3x, and cut downtime by 50% after standardizing software delivery with a unified platform. Rather than adapting processes to fit individual tools, engineering teams can scale consistent delivery practices across applications, services, and environments, freeing up time to deliver more value to customers.
Key capabilities of a modern DevOps platform
A modern DevOps platform should do more than automate software delivery. It should provide the capabilities needed to build, secure, deploy, and govern applications consistently across teams, environments, and cloud providers.
- Automated software delivery: Support CI/CD pipelines, deployment automation, rollback strategies, and release orchestration.
- Integrated security: Embed security scanning and policy enforcement throughout the software delivery lifecycle instead of treating security as a separate process.
- Artifact management: Securely store, version, and manage build artifacts and container images from a central repository.
- Enterprise governance: Enforce role-based access control (RBAC), audit trails, compliance policies, and approval workflows.
- Multi-cloud operations: Deliver applications consistently across public cloud, private cloud, Kubernetes, and on-premises environments.
- AI-powered assistance: Accelerate software delivery with intelligent recommendations, pipeline optimization, and automated troubleshooting.
- Operational visibility: Track delivery performance, cloud costs, and engineering metrics from a unified view.
As engineering organizations grow, the challenge is no longer adopting individual DevOps capabilities. It is operating them efficiently at scale. That is driving a broader shift toward unified platforms that reduce operational complexity while improving governance, visibility, and software delivery performance.
Why enterprises are moving to a unified enterprise DevOps platform
As engineering organizations grow, software delivery often becomes more difficult to manage than software development itself. New tools improve individual stages of the delivery lifecycle, but they also introduce additional licensing costs, longer onboarding cycles, fragmented visibility, inconsistent governance, and a broader security surface to manage.
This growing complexity is reflected in industry research. Forrester's The Forrester Wave™: DevOps Platforms, Q2 2025 reflects the industry's shift from evaluating individual delivery tools to assessing integrated DevOps platforms that support end-to-end software delivery.
Performance research reinforces the shift. Elite engineering teams deploy 182x more frequently than low performers (DORA, State of AI-assisted Software Development 2025), and that gap tracks closely with whether delivery runs on a unified platform or a fragmented toolchain. Together, these trends explain why enterprises are increasingly consolidating their DevOps toolchains into unified platforms, but which one should you go for?
How do you evaluate the best DevOps platform for your team?
Choosing a DevOps platform is a strategic engineering decision, not just a software purchase. The platform you select will influence how your teams build, secure, deploy, and govern software for years to come. Rather than comparing feature checklists, evaluate how well each platform supports your delivery workflows, integrates with your existing ecosystem, and scales with your engineering organization. In practice, the best DevOps platform is rarely the one with the most features. It is the one that fits the way your teams deliver software.
What should you look for when evaluating a DevOps platform?
When evaluating DevOps platforms, look beyond individual capabilities. Consider whether the platform can:
- Support your end-to-end software delivery workflows, not just CI/CD.
- Integrate with your existing developer tools, cloud platforms, and infrastructure.
- Enforce security, governance, and compliance without slowing software delivery.
- Scale across multiple teams, applications, and environments.
- Provide visibility into software delivery performance, reliability, and operational costs.
What questions should you ask before you commit?
Before making a decision, involve engineering, security, platform, and operations teams in the evaluation process. The answers to these questions will often reveal whether a platform fits your organization better than a feature comparison alone.
- Will this platform simplify our software delivery process or add another layer of complexity?
- Can it replace multiple point solutions without disrupting existing workflows?
- How much customization and ongoing maintenance will it require?
- Will it scale with our engineering organization over the next three to five years?
- Does it improve the developer experience while meeting enterprise governance requirements?
How Harness Delivers a Unified DevOps Platform | 120–150 words
Modern software delivery requires more than CI/CD automation. Teams need a platform that unifies software delivery, security, governance, cost management, and engineering insights without increasing operational complexity. Harness delivers this through an AI-native DevOps platform that brings together:
- Continuous Integration (CI)
- Continuous Delivery (CD),
- GitOps,
- Software Supply Chain Security (SSCS),
- Cloud Cost Management,
- Infrastructure as Code Management (IaCM), and
- Engineering Insights in a single platform.
Beyond consolidating capabilities, Harness helps engineering teams work more efficiently. AI-powered pipeline generation and optimization reduce manual effort, built-in governance enforces organizational policies across delivery workflows, and unified dashboards provide real-time visibility into deployments, reliability, compliance, and engineering performance. The result is a software delivery platform designed to help organizations build, secure, and deploy software with greater speed and consistency that engineering teams trust.
Choose unified delivery before fragmentation chooses for you
Every additional point tool starts as a fix for one problem and ends as one more system someone has to maintain, secure, and explain to a new hire. The question is not whether your DevOps tool stack will need to consolidate eventually. It is whether you do it on your own timeline or after the integration debt has already slowed delivery.
Start by mapping your own delivery workflow against the criteria above: integration, governance, scalability, AI capability, and total cost.
See how Harness brings CI, CD, security, cost management, and engineering insights onto one AI-native platform.
FAQs about DevOps platforms
What is the difference between a DevOps platform and a DevOps pipeline?
A DevOps pipeline is a workflow that automates stages of software delivery, such as building, testing, and deploying applications. A DevOps platform is a broader system that connects multiple pipelines with security, governance, artifact management, infrastructure automation, and engineering insights to support the entire software delivery lifecycle.
What is the best DevOps platform for enterprise teams?
The best enterprise DevOps platform is one that aligns with your organization's software delivery workflows, security requirements, and long-term engineering strategy. Enterprise teams should prioritize unified governance, scalability, AI-assisted automation, and support for hybrid or multi-cloud environments over the number of individual features.
Can a small team benefit from a unified DevOps platform?
Yes. A unified DevOps platform can reduce the operational overhead of managing multiple tools, allowing smaller teams to automate software delivery, improve visibility, and scale more easily as engineering needs grow. The key is selecting a platform that matches the team's current requirements without adding unnecessary complexity.
How long does it take to adopt a new DevOps platform?
Implementation timelines vary depending on the size of the organization, existing toolchain, and migration strategy. Smaller teams may complete adoption within weeks, while enterprise deployments often take several months as workflows, governance policies, and integrations are standardized across teams.
Is a DevOps platform the same as a CI/CD platform?
No. A CI/CD platform focuses primarily on automating software builds, testing, and deployments. A DevOps platform includes CI/CD but also provides capabilities such as security, governance, artifact management, infrastructure automation, engineering insights, and policy enforcement within a unified software delivery system.
What are the limits of consolidating onto one DevOps platform?
A unified platform trades some flexibility for governance and simplicity, so teams that depend on a narrow best-of-breed tool for a specific workflow may find the built-in equivalent less specialized. The right test is whether the platform covers enough of your delivery lifecycle to retire the point tools it replaces, not whether every individual feature matches a specialist tool.

Identity and Permissions for AI Worker Agents in Harness
When we launched Autonomous Worker Agents, governance inherited, not integrated, was the core promise: agents run inside the same pipelines, and inherit the same RBAC, policy, and audit trails already governing production, rather than getting security bolted on after the fact. The first post in this series covered one half of how we back that promise: isolation, the four walls (image hardening, process isolation, secret isolation, network isolation) that contain a compromised agent, even if it turns hostile. We proved that model by replaying a real CVSS-9.0 breach against our own hardened image and watching it fail at every layer.
This post covers the other half. Isolation answers what happens when an agent is compromised. This post answers what an agent is allowed to do when it isn't, when it's running exactly as designed. Even a perfectly sandboxed Autonomous Worker Agent is still a liability if it runs with more access than the task requires. What identity does it run as, and which permissions does it hold? This is authorization and least privilege, applied to a caller that picks its own actions at runtime.
THE INVARIANT EVERYTHING ELSE ENFORCES
An agent holds no standing privilege of its own. Its effective access is a bounded subset of the triggering principal's, the minimum the task needs, and nothing more.
Key takeaways
Delegated identity: An agent authenticates as the principal that triggered it: same user, same audit trail. It is never a standing superuser or a shared service account with broad role bindings.
Least privilege by construction: Its access is a scoped subset of the triggering user's, on a token minted per run and deleted when the run ends. The mint step rejects any permission it can't prove the parent already holds.
Policy and RBAC, inherited: The RBAC and OPA governance that already guard Harness pipelines extend to agents, covering who may build one and what policy allows, because an agent is just a new kind of pipeline step.
Enforced, not assumed: Every check runs on the server: RBAC, the scope filter, and the gateway's tool intersection. A hidden UI button proves nothing; the console, the API, and the agent all resolve to the same decision.
Isolation bounds a compromise. Authorization bounds intent.
We split agent security into three categories. The first post covered isolation: it assumes the process is already compromised and asks what the kernel, the filesystem, and the network will refuse to do on its behalf, controls that hold even when everything above them fails.
This post is category two. It answers a question isolation never touches: when the agent is functioning exactly as designed, what is it authorized to reach? An agent that's perfectly sandboxed but runs with the triggering user's full role bindings is still over-privileged. Isolation bounds the blast radius of a breach; authorization bounds the blast radius of correct, intended execution.
The full model, with this post's category marked:

Governance moved from authoring time to runtime
Before agents, a pipeline step was explicit. Someone wrote create_issue(project="INFRA"), it went through review, and you could read the pipeline and know exactly what it would do to the outside world. The decision was in the code, and the code was checked before it ran.
Agents don't work that way. You hand an agent a goal. At runtime, the model decides which tools to call, in what order, with what parameters. The action isn't in the code anymore. You can't read it before it happens, and every control in this post exists because of that shift.
Credentials work the way they always did; the harder problem is accountability. The decision-maker moved from a human at authoring time to a model at runtime, so the guardrails move to runtime too. If you can't review an action before it runs, you're limited to bounding which actions are possible and recording every one that happens. Harness already governs pipelines with RBAC, Policy-as-Code, and an audit trail, and since an agent is just a new kind of pipeline step, that governance extends to it directly.
The sharpest example of the shift is the credential the agent runs with, because getting that wrong makes every other control irrelevant.
The credential the agent runs with
Same agent, same job: run one deploy pipeline on the user's behalf. The only thing that differs is the token it carries.
Two controls before it runs, three while it runs
That scoped token is one of five controls. On its own, it bounds which Harness resources the agent can reach, not who was allowed to build the agent, which tools it may call, or what it did afterward. The full picture spans five controls in two phases. Two apply before the agent runs, at authoring and save time, deciding who may build it and what policy allows. Three apply while it runs, bounding the identity it carries, the tools it can call, and the record it leaves. In order:
Walking the five, in order
Each one below stands on its own: the gap it closes, how it works, and the diagram that makes it concrete. None of them trusts the model to behave; each is enforced by the platform.
Control 1: RBAC on the agent resource
Author, publish, and execute are separate permissions
The gap it closes
An agent can hold a privileged connector and act across production. If anyone with module access could create, publish, or delete one, there's no boundary at all: a low-trust user could publish an agent other teams run in production, or bind a privileged connector to a brand-new agent.
How it works
> Author, publish, and execute are three permissions, not one. A developer can build agents in their project without being able to publish one account-wide or run someone else's; each is a separate grant.
> Attaching a connector is gated on its own. Binding a privileged MCP connector to an agent is a distinct permission, so a low-trust user can't smuggle broad access in the back door.
> Enforced server-side, across account, org, and project. The UI hiding a button is never the source of truth.
In plain terms. A print shop. One badge lets you design a poster. A different, harder-to-get badge lets you put it on the wall where everyone sees it. And a third decides who's allowed to run the press. Nobody gets all three just for walking in.

Control 2: Policy-as-Code governance (OPA)
Pipeline OPA policies, extended to agent definitions at save and trigger time
The gap it closes
RBAC says who may build and run an agent. But it can't express a rule about the agent's content: which model it uses, which connectors it may attach, how many turns it may take. A security team wants to write that rule once and have every agent obey it, no matter who authors it: "only approved models," "this connector is off-limits," "cap agents at ten turns," "names must follow our standard." Without it, every guardrail is per-agent and easy to miss.
How it works
Harness has governed pipelines with Open Policy Agent for years: Policy-as-Code that evaluates a pipeline against your rules at save and run time and blocks or warns on a violation. Agents are a pipeline construct, so they inherit the same engine. That policy surface now reads agent definitions too:
> Model restrictions: which model connectors an agent may use.
> Connector restrictions: which MCP connectors may be attached.
> Guardrail limits: caps like maximum turns, so it can't loop unbounded.
> Naming and sensitive variables: standards enforced, sensitive inputs kept out.
> Permission boundaries: flagging high-blast-radius verbs for explicit sign-off.
In plain terms. OPA is the building code that the plans must pass before construction. The gateway is the guard at the door once it's open. You want both: an illegal plan and a person walking out with something they shouldn't have are two different failures.

Keep one distinction straight, because a later control looks similar. OPA checks the definition up front, when the agent is saved or the pipeline is triggered. The MCP gateway (control 4) checks each call inline, as it happens. One stops a bad agent from shipping; the other stops a shipped agent from making a call it shouldn't.
Control 3: Scoped, ephemeral tokens
A subset of the parent's grants, on a key that expires with the run
The gap it closes
The easy thing to hand an automated job is a normal token, a personal or service-account key. But those carry every permission their owner has. Give one to an agent that only needed to run one pipeline and you've handed it the whole keyring, and a leak spills the entire account.
How it works
> You can't grant what you don't have. At mint time, every requested permission is checked against the parent's own access: ask for something the parent can't do and creation fails. A scoped token can only ever narrow, never widen.
> Scope is enforced server-side, on every check. After access control says "yes," a scope filter flips anything outside the token's slice back to "no." Effective access is the overlap of the two.
> Ephemeral, and still you. The token is minted at step start and deleted when the run ends, minutes, not months, yet it resolves to the human who triggered it, so the audit trail names a person, not a faceless bot.
In plain terms. Your building pass opens forty doors. Before an errand, the desk cuts a paper key that opens door twelve, expires tonight, and is logged under your name. The runner can open door twelve, nothing else. Tomorrow it's scrap.

Effective access = what the parent has AND what the token was cut for. Whichever is smaller wins.
The token comes in two shapes, with the same scoping rules but different lifespans. Ephemeral is the default for pipeline agents: born at step start, bulk-deleted when the run ends, with no cleanup to forget. Persistent is user-created for standing needs (a CI job that only pulls one registry): longer-lived, but still just its declared slice, and revocable like any key.
Control 4: Tool authorization at the MCP gateway
Connector and agent allow-lists, enforced as an intersection
The gap it closes
Say two agents share one Jira connector: CI AutoFix needs to create issues, Vulnerability Remediation only needs to read them. Left alone, both can call every tool the Jira MCP server exposes, including delete_issue and transition_issue, because a connector has no tool restrictions by default. The scoped token bounds that Harness resources the agent reaches; it says nothing about which tools it may call on a third-party server. That's a separate leash.
How it works
> The connector declares what may flow through it at all. An admin sets the connector's tool allow-list once (get_issue, add_comment, search_issues) plus the list of agents approved to use it.
> Each agent declares the narrower set it needs. On the same connector, the read-only agent lists only the read tools; the AutoFix agent lists the write ones, so the same bot has different reach depending on which agent is calling.
> The gateway allows only the intersection. The effective set for any call is connector.allowedTools ∩ agent.allowedTools. A tool in the overlap proceeds; anything outside is blocked and logged before the call ever leaves Harness.
In plain terms. The connector is the toolbox the shop owns; the agent's list is what this worker signed out today. The gate only lets out what's on both lists. Grab for anything else, and it stops you at the door.

allowed = connector.allowedTools ∩ agent.allowedTools. Only tools on both lists reach the server.
The check runs outside the agent, so a prompt injection that hijacks the agent can't switch it off. It's centrally governed: change a connector's allow-list once, and every agent picks it up. The agent never holds the connector's real credentials either; the gateway attaches it on the way out.
Control 5: Per-call attribution
Every tool call is bound to a principal, a run, and a result
The gap it closes
A pipeline runs at 2 am; the next morning, a few Jira tickets have changed. The run log says the pipeline ran and the agent step completed, but it does not say which tools it called, with what parameters, or which tickets it touched. Worse, the third-party system attributes the change to whoever created the connector months ago, not to this run. Authorization can be perfect, and you're still blind to what happened.
How it works
Authorization and attribution are different jobs: one decides whether an action is allowed, the other records who is answerable for it. A system can nail the first and fail the second, so every outbound tool call emits a structured record, not a buried log line, but fields you can query:
> Which agent made the call, and which run did it belong to?
> Which principal it acted as: the real human who triggered it, preserved through the scoped token.
> Which tool was called, with what parameters, and what result came back?

Because the scoped token carries the real identity all the way through, each record names the person behind the run, not just the agent. When something looks off, you read the record instead of cross-referencing timestamps by hand.
Grants are resource-type plus verb
Both the RBAC layer and the scoped token use the same grammar, and it isn't a coarse role like "deployer." A grant is a resource type bound to an explicit set of verbs, optionally narrowed to named resource IDs and a scope. It maps one-to-one onto Harness's existing permission identifiers, so an agent grant reads exactly like a human role binding.
Each grant is scoped to an account, org, or project, and can even name specific resource IDs. Amber verbs are the high-blast-radius ones (create, edit, delete, push); they're default-deny for agents and have to be asked for on purpose. The catalog spans every Harness module: deployments, GitOps, infrastructure-as-code, security, cost. A real agent grant is a handful of these lines, never the whole list.
Least privilege, made literal
Put the five together, and the model collapses into one sentence: an agent's real power is the overlap of everything that had to say yes, and everyone defaults to no. Miss any one, RBAC, OPA, the scoped token, the gateway intersection, attribution, and the action doesn't happen. That overlap is deliberately tiny: far smaller than the owner's full access, on a key that expires with the job.
This is the same instinct as the isolation post, applied to a different failure mode. Isolation shrinks what a compromised agent can reach; permissions shrink what a trusted one can reach. Both assume the reach will be abused and make it as small as the job allows, enforced by the platform, never by the model's judgment.
Five controls, two phases. An agent's effective reach is the intersection of all five, and every one defaults to deny.
The whole thing in one request
One tool call, from the agent's goal to the result. Two gates clear before it runs, two check the call itself, and one records what happened afterward, all five in sequence.
Two gates before the run, two on every call, one record after. None of them ask the model to be trustworthy.
The grant is declared on the stage
You don't mint tokens, configure scope filters, or wire the gateway by hand. You declare the agent's permission set and tool allow-list on the stage spec; the platform mints the ephemeral scoped token, enforces the intersection at the gateway, and revokes the token when the run ends. A least-privilege "deploy and reconcile" agent looks like this:

No create, no delete, no secret access, and only two Jira tools. The agent can ship, reconcile, and comment, but it can't rewrite a pipeline, read a credential, or delete an issue, even though the person who triggered it might. The grant is checked at save time against that person's access and your OPA policy, so an over-privileged agent never ships.
FAQs
Whose identity does the agent act as? The person who triggered the run. A scoped token still resolves to that user, so every action the agent takes is attributed to them in the audit log. The agent borrows the identity for reach; it doesn't get one of its own.
Can an agent ever end up with more access than the person running it? No. Its effective access is the overlap of what its grant asked for and what its triggering user actually has, whichever is smaller. The mint step verifies every requested permission against the parent's access first, so a grant can only ever subtract from what the human could already do, never add to it.
What happens to the token when the run ends? For a pipeline agent it's deleted. The token is ephemeral and tied to the execution: when the run finishes, every token it spawned is bulk-deleted. Lifetime is minutes, capped at a day, so a leaked one is expired and worthless almost immediately.
Is this enforced, or just hidden in the UI? Enforced on the server. Every permission check goes through one place, and the scope filter runs there, after normal access control, flipping anything outside the token's slice back to denied. Hiding a button changes nothing; the API, the console, and the agent all get the same answer.
How does a new team member avoid shipping an over-privileged agent? The grant is declarative YAML, checked before the agent runs. Ask for permission the triggering principal doesn't have, and it fails fast, naming the missing grant, instead of silently succeeding with too much or silently failing at runtime with too little.
Where does this sit next to isolation and the LLM gateway? Isolation (the first post) contains a compromised agent; permissions (this post) bound a well-behaved one. The behavioral layer, reading prompts and responses for injection and sensitive data, is the third part and its own post. Three parts, one goal: the agent's reach is decided by the system, not the model's judgment.

How to Troubleshoot and Debug Ansible Playbooks: A Complete Guide
- Structured, conditional debugging, using verbosity controls, targeted variable inspection, and context-aware output, dramatically reduces troubleshooting time and noise in Ansible playbooks.
- Integrating best practices such as reusable debug roles, failure taxonomies, and CI/CD-friendly log formatting enables teams to automate root cause analysis and artifact collection, making incidents easier to resolve and less likely to recur.
- Embedding these debugging patterns into your delivery pipelines with platforms like Harness unlocks AI-powered verification, automated rollbacks, and scalable governance, transforming manual debugging insights into proactive, automated deployment safety nets.
Infrastructure as Code (IaC) has transformed how teams manage environments, but let’s be honest: when something breaks, debugging can feel like searching for a needle in a YAML haystack.
If you’re working with Ansible, you already know its power: agentless automation, declarative playbooks, and consistent deployments. But even the most elegant playbooks can fail due to syntax issues, variable conflicts, or unexpected runtime behavior.
That’s where a structured debugging approach and modern platforms like Harness come in. With solutions like Harness Infrastructure as Code Management, teams gain visibility, governance, and control over IaC workflows at scale, enabling faster, more reliable troubleshooting.
Why Debugging Ansible Playbooks Matters
Ansible is designed for simplicity, but real-world environments are anything but simple. Debugging is essential because:
- Playbooks can fail silently or behave unexpectedly
- Variables and templates can produce inconsistent results
- Infrastructure differences across environments can cause drift
- Dependencies between tasks and roles can create hidden issues
Common challenges include variable interpolation problems, connection errors, and inconsistent execution across hosts.
Without proper debugging, these issues can slow down deployments, introduce risk, and waste engineering time.
How Ansible Executes Playbooks
Before debugging, you need to understand how Ansible works:
- A playbook contains plays
- Each play targets hosts
- Plays include tasks
- Tasks execute modules
When something fails, it’s crucial to pinpoint where in this hierarchy the issue occurs. Understanding execution flow helps you isolate problems faster and avoid guesswork.
How to Troubleshoot and Debug Ansible Playbooks
Step 1: Start with a Syntax Check
The fastest way to catch issues? Validate your YAML before execution.
ansible-playbook --syntax-check playbook.ymlThis catches:
- YAML formatting errors
- Missing colons or indentation issues
- Invalid structure
Syntax errors are one of the most common causes of failure, so never skip this step.
Step 2: Increase Verbosity for More Insight
Ansible provides built-in verbosity flags that reveal what’s happening under the hood:
ansible-playbook playbook.yml -v
ansible-playbook playbook.yml -vv
ansible-playbook playbook.yml -vvv
ansible-playbook playbook.yml -vvvvEach level gives you deeper visibility:
- -v: Basic task info
- -vv: Includes variable values
- -vvv: Task-level debugging
- -vvvv: Connection-level details
This is often the quickest way to identify where things go wrong.
Step 3: Use the Ansible Debug Module
The debug module is your best friend when troubleshooting.
It allows you to:
- Print variable values
- Inspect task outputs
- Track execution flow
Example:
- name: Debug variable
debug:
var: my_variableYou can also display custom messages:
- name: Print message
debug:
msg: "Deployment started"This helps you verify that variables are set correctly and tasks are executing as expected.
Step 4: Run in Check Mode (Dry Run)
Want to test changes without impacting systems?
Use check mode:
ansible-playbook playbook.yml --checkThis simulates execution and shows what would change without actually applying it.
It’s ideal for:
- Testing updates safely
- Validating logic
- Preventing unintended changes
Step 5: Use the Ansible Playbook Debugger
Ansible includes an interactive debugger that triggers when tasks fail.
You can enable it like this:
- name: Example task
command: /bin/false
debugger: on_failedWhen a task fails, the debugger allows you to:
- Inspect variables
- Modify arguments
- Re-run tasks
This eliminates the need to rerun the entire playbook repeatedly.
Step 6: Validate Variables and Templates
Many issues stem from incorrect variables or templating.
Common problems include:
- Undefined variables
- Incorrect variable precedence
- Jinja2 template errors
Use debug statements to inspect variables:
- debug:
msg: "{{ my_variable }}"Or check if variables exist:
when: my_variable is definedUnderstanding variable behavior is critical for reliable playbooks.
Step 7: Inspect Registered Variables
Registered variables capture task results, which can be incredibly useful.
Example:
- name: Run command
command: ls
register: result
- debug:
var: resultThis shows:
- Command output
- Exit status
- Execution metadata
It’s especially useful when debugging conditional logic or failures.
Step 8: Troubleshoot Connection Issues
Connection problems are another common culprit.
To debug:
- Use -vvvv for connection logs
- Verify SSH access
- Check inventory configuration
You can also enable:
ANSIBLE_KEEP_REMOTE_FILES=1This keeps temporary scripts on remote machines for inspection.
Step 9: Break Down Complex Playbooks
Large playbooks are harder to debug.
Best practice:
- Split playbooks into smaller roles
- Test individual components
- Run tasks step-by-step
You can use:
ansible-playbook playbook.yml --stepThis lets you execute tasks interactively, one at a time.
Step 10: Use Logging and Monitoring
Logging is essential for long-term debugging.
You can configure logging in Ansible.cfg:
[defaults]
log_path = /var/log/ansible.logLogs help you:
- Track execution history
- Identify recurring issues
- Debug production failures
Step 11: Apply Conditional Debugging
Sometimes, you only want debug output under certain conditions.
Example:
- debug:
msg: "Variable is set"
when: my_variable is definedThis reduces noise while still providing useful insights.
Step 12: Common Errors and How to Fix Them
Let’s look at frequent issues:
1. YAML Syntax Errors
- Cause: Incorrect indentation
- Fix: Use linting tools and syntax checks
2. Undefined Variables
- Cause: Missing or misspelled variables
- Fix: Use debug and validation
3. Task Failures
- Cause: Incorrect module usage
- Fix: Check module documentation and outputs
4. Connection Failures
- Cause: SSH or inventory issues
- Fix: Verify credentials and host access
5. Idempotency Issues
- Cause: Tasks not designed to be repeatable
- Fix: Use proper module parameters
Step 13: Build a Systematic Debugging Workflow
The most effective teams follow a structured approach:
- Run syntax check
- Execute with verbosity
- Add debug statements
- Validate variables
- Use check mode
- Inspect logs
- Use a debugger for failures
This ensures you move from simple checks to deeper analysis without wasting time.
How Harness Improves Ansible Debugging at Scale
While native Ansible tools are powerful, they can become difficult to manage at scale, especially across multiple environments and teams.
That’s where Harness Infrastructure as Code Management comes in.
With Harness, teams can:
- Centralize IaC workflows
- Visualize deployments and failures
- Enforce governance and compliance
- Detect drift across environments
- Debug faster with unified insights
Instead of chasing errors across logs and CLI outputs, Harness provides a single pane of glass for managing and troubleshooting infrastructure.
Best Practices for Debugging Ansible Playbooks
To avoid recurring issues, follow these best practices:
- Keep playbooks simple and modular
- Use descriptive task names
- Validate inputs early
- Leverage check mode before deployment
- Use version control for playbooks
- Add debug statements during development
- Monitor logs consistently
Consistency and structure are key to reliable automation.
Move From Guessing To Knowing, Then Automate It
Structured Ansible debug and delivery practices transform reactive firefighting into proactive problem-solving. When you standardize verbosity levels, conditional output, and failure analysis, you cut mean time to resolution and stop scrolling through endless logs hunting for clues.
Those same debugging patterns that help you isolate failures manually become the intelligence that drives automated pipeline decisions. Smart platforms use your codified failure conditions, rollback triggers, and health checks to make deployment decisions without human intervention. Teams that systematize their debugging insights can focus on building features instead of babysitting deployments.
Ready to turn those debugging skills into automated safety nets? Harness Infrastructure as Code Management delivers AI-powered verification, automatic rollbacks, and GitOps workflows that eliminate the guesswork from production deployments.
FAQ: Fast Answers To Common Ansible Debug Questions
These five questions address the debugging bottlenecks that turn 5-minute fixes into hour-long investigations. Each answer provides tested patterns that cut time-to-resolution.
How do I choose between -vv and -vvvv without flooding logs?
Use -vv for task-level details and connection info. Reserve -vvv for module arguments and package manager chatter. Use -vvvv only when you need SSH transport debugging. In CI, pair verbosity with --limit to constrain output and keep log budgets manageable.
What's the safest way to print secrets without exposing them in CI logs?
Never use debug: var= with secret variables directly. Instead, print only non-sensitive metadata, such as key names or lengths. Use Ansible Vault for encryption and use your CI platform's secret management. Harness handles secret injection safely in pipeline runs.
How do I debug a task that only fails on one host in a 59-host inventory?
Use --limit hostname to isolate the problematic host. Enable the task debugger with ANSIBLE_ENABLE_TASK_DEBUGGER=True for interactive inspection. Compare gathered facts between working and failing hosts to identify configuration drift or missing dependencies.
Why does my changed_when always show changed even when nothing updates?
Shell and command tasks default to changed: true regardless of whether there are actual changes. Define explicit changed_when conditions, such as changed_when: result.rc == 0 and 'updated' in result. stdout. Use --check and --diff modes to preview changes before execution.
How do I persist and attach Ansible logs and diffs as CI artifacts for PRs?
Structure output with JSON formatting and redirect to files. Archive stdout, stderr, and diff outputs as build artifacts. Harness pipelines can capture these automatically and attach them to PR checks. Harness CD extends this with AI verification and automated rollback based on deployment artifacts.

DevOps Solutions: How to Pick the Right Stack for Your Team
What are DevOps solutions?
DevOps solutions are the tools and platforms that help teams build, test, secure, deploy, monitor, and manage software throughout the software delivery lifecycle. While DevOps is often associated with CI/CD, modern DevOps software supports a much broader set of capabilities, including infrastructure automation, security, observability, testing, and developer self-service.
Organizations can adopt individual point tools for specific functions or use integrated DevOps platforms that bring multiple capabilities together. Point tools typically focus on a single capability, while integrated DevOps platforms combine multiple functions into a unified experience.
Quick Facts
Engineering teams have more DevOps solutions to choose from than ever before. CI/CD platforms, infrastructure automation tools, security scanners, observability platforms, and developer productivity solutions all promise faster software delivery. Yet for many organizations, adding tools has not necessarily made delivery simpler.
As software delivery environments grow, so does the operational burden of managing integrations, permissions, workflows, and governance across multiple systems. By 2027, most organizations will shift from multiple point solutions to unified platforms to streamline application delivery, reversing where the majority sat in 2023.
Choosing a DevOps stack is no longer just a tooling decision. It is an architectural decision that affects developer productivity, operational efficiency, governance, and the ability to scale software delivery over time. This guide explores the different types of DevOps solutions and the criteria teams should use when evaluating the right stack for their needs.
What to look for in DevOps software and what are DevOps tools worth keeping?
The capabilities listed above do not carry equal weight. Most teams already have access to CI/CD tools, security scanners, monitoring platforms, and infrastructure automation frameworks. The real question is whether those capabilities work together to improve software delivery.
When evaluating DevOps solutions, focus on six areas:
Beyond features, consider the long-term operational impact of each option. Integration maintenance, onboarding effort, licensing costs, and platform administration all contribute to the total cost of ownership. A tool that solves one problem today can create additional complexity as teams, applications, and delivery requirements grow.
Quick Tip: The lowest-cost DevOps tool isn't always the most cost-effective option. As teams scale, integration, maintenance, platform administration, and operational overhead can outweigh initial licensing savings.
Having the right capabilities is only part of the decision. Teams must also determine whether those capabilities should come from a unified platform or a collection of specialized devops software tools.
Types of DevOps solutions for modern software delivery in 2026
Most organizations choose between two approaches: adopting a unified DevOps platform or assembling a best-of-breed toolchain. The right choice depends on factors such as team size, operational complexity, compliance requirements, and internal engineering resources.
The same trade-offs apply when evaluating open source and commercial solutions. Open source tools often provide flexibility and community-driven innovation but may require additional expertise to deploy, integrate, and maintain. Commercial platforms typically offer enterprise support, built-in integrations, and streamlined administration in exchange for licensing costs.
Deployment models also influence tool selection. Cloud-native solutions are often preferred for scalability and faster adoption, while on-premise deployments remain common in highly regulated industries with strict security, compliance, or data residency requirements.
The best DevOps solution is not defined by a single category. It depends on how well the chosen approach aligns with your team's delivery model, governance needs, and long-term operational strategy. The same DevOps approach rarely works equally well across organizations. A startup focused on shipping quickly faces a different set of constraints than an enterprise managing hundreds of developers, compliance requirements, and complex delivery pipelines.
How do you evaluate the best DevOps tools for your team?
The same DevOps solution can be a great fit for one organization and a poor fit for another. Team size, delivery complexity, and operational requirements often have a greater impact on tool selection than feature lists.
Regardless of company size, engineering leaders should evaluate every DevOps solution against a few practical questions:
- Will this reduce operational complexity or add to it?
- How much effort will be required to onboard teams and maintain integrations?
- Can it scale alongside our applications, teams, and delivery processes?
- What are the long-term costs, including licensing, administration, and platform maintenance?
Vendor lock-in should also be part of the evaluation process. The deeper a tool becomes embedded in deployment pipelines, security controls, and developer workflows, the more difficult and costly it becomes to replace. Many DevOps initiatives run into trouble not because teams chose the wrong solution category, but because critical considerations such as workflow design, governance, and developer adoption were overlooked during implementation.
Common DevOps solution mistakes to avoid
Even well-intentioned DevOps initiatives can create new challenges when tooling decisions are made in isolation.
- Adding tools to solve every new problem. More tools often mean more integrations, handoffs, and maintenance overhead. Fix: consolidate capabilities where possible and evaluate the operational cost of every addition.
- Treating developer experience as an afterthought. Complex workflows and fragmented tooling slow adoption and create friction for engineering teams. Fix: prioritize solutions that simplify day-to-day development and deployment tasks.
- Leaving governance until later. Retrofitting security, compliance, and access controls is often more difficult than building them into delivery workflows from the start. Fix: evaluate governance requirements alongside functionality.
- Selecting tools before defining delivery workflows. Technology rarely fixes unclear processes. Teams that start with tooling often end up redesigning workflows later. Fix: establish how software should move from development to production before evaluating solutions.
Reducing operational overhead is one reason many organizations are rethinking fragmented DevOps toolchains in favor of platform-based approaches.
How Harness fits into your DevOps stack
As software delivery becomes more complex, many organizations are looking for ways to improve engineering efficiency without adding operational overhead. DORA research (State of AI-assisted Software Development 2025) finds that software delivery performance predicts organizational performance and employee well-being, reinforcing the need for tools that help teams deliver software reliably and at scale.
Harness brings key software delivery capabilities together in a unified, AI-powered platform. Teams can automate build and test workflows with Harness CI, streamline deployments using Harness CD, and gain visibility into engineering productivity and delivery metrics through AI DLC Insights.
Cost efficiency is becoming equally important. According to the FinOps Foundation, 45% of organizations spending more than $100 million annually on cloud report that AI and machine learning are having a rapidly increasing impact on their FinOps practices. Harness Cloud & AI Cost Management (CACM) helps teams understand, optimize, and govern cloud spending alongside their software delivery workflows, reducing the need to manage disconnected tools across the engineering ecosystem.
How do Harness DevOps solutions perform in practice?
Organizations evaluating DevOps solutions often face the same challenge: balancing delivery speed, governance, visibility, and operational overhead. The following examples show how different teams approached those challenges.
How did Ancestry replace 80-plus Jenkins instances with one governed pipeline?
Ancestry managed software delivery across more than 80 Jenkins instances, with each team following a different deployment process and governance practice. After adopting Harness CI/CD, the company onboarded 350 systems in its first year, increased deployment frequency 3x, and achieved an 80-to-1 reduction in the effort needed to roll a change out across every pipeline.
“Harness now empowers Ancestry to implement new features once and then automatically extend those across every pipeline, representing an 80-to-1 reduction in developer effort.”
Ken Angell, Principal Architect, Ancestry
Source: Ancestry adds consistency and governance to cut downtime
How did United Airlines put governance in developers' hands without slowing delivery?
United Airlines needed stronger governance across software delivery without slowing development teams. Choosing Harness for CI and CD let the airline shift security and governance left, giving developers self-service deployment within guardrails instead of waiting on manual review. United reported 75% efficiency gains and cut CI build times for one application from 22 minutes to under 5.
“By choosing Harness for CI and CD, we were able to give the governance policies to the developers and create the guardrails we needed. Harness gives us a platform rather than just a DevOps tool.”
Ratna Devarapalli, Director of IT, Architecture, Platform Engineering and DevOps, United Airlines
Source: United Airlines accelerates deployments with Harness
How did Tyler Technologies save $1.2 million a year on cloud costs?
Tyler Technologies, the largest SaaS vendor solely focused on the U.S. public sector, ran client test environments around the clock even when most sat idle outside business hours. Reorganizing its cloud estate by client time zone and activity pattern and applying Harness Cloud Cost Management's AutoStopping let Tyler power down idle environments automatically. The result: $1.2 million in annualized cloud cost savings.
“Cloud AutoStopping opened up new possibilities for cloud cost management. We saw how reorganizing our deployments by geography, function, and use patterns could unlock game-changing savings.”
Chris Camire, Senior Manager of Technical Services, Tyler Technologies
Source: Tyler Technologies reaches $1.2M annualized cost savings with Harness Cloud Cost Management
Choose the DevOps solution that fits your delivery model, not the longest feature list
The capabilities matter less than how well they fit together. A long feature list does not tell you whether a tool will reduce operational complexity or add to it, and the gap between those two outcomes is where most DevOps initiatives succeed or stall.
Map your own delivery workflow first, then evaluate DevOps solutions against integration, governance, scalability, and total cost, not a checklist of capabilities.
See how Harness brings CI, CD, security, and cost management onto one AI-powered platform.
FAQs about DevOps solutions
What are the most commonly used DevOps tools?
Common DevOps tools include CI/CD platforms, source code repositories, infrastructure-as-code (IaC) tools, observability platforms, security scanners, and cloud cost management solutions. Popular examples include GitHub, GitLab, Jenkins, Terraform, Kubernetes, Datadog, and Harness.
What is the best DevOps software for small teams?
The best DevOps software for small teams is typically easy to adopt, requires minimal administration, and supports multiple stages of the software delivery lifecycle. Many smaller organizations prefer integrated platforms to reduce the overhead of managing multiple tools and integrations.
How do you build a DevOps stack from scratch?
Start by defining your software delivery workflow. Then identify the capabilities needed to support it, including source control, CI/CD, infrastructure automation, security, observability, and cost management. Select tools that integrate well together and can scale as your requirements evolve.
What is the difference between DevOps tools and a DevOps platform?
DevOps tools typically solve a specific problem, such as source control, testing, or monitoring. A DevOps platform brings multiple software delivery capabilities together in a unified environment, reducing integration complexity and improving visibility across workflows.
How do you know when it is time to switch your DevOps solution?
It may be time to reevaluate your DevOps solution if teams are spending significant effort maintaining integrations, onboarding new tools, addressing visibility gaps, or managing operational complexity. Frequent workflow bottlenecks and growing governance requirements are also common indicators.
What are the limits of consolidating onto one DevOps platform?
A unified platform trades some flexibility for governance and simplicity; teams that need a specific best-of-breed tool for a narrow use case may find a platform's built-in version less specialized. The right test is whether the platform covers enough of your delivery lifecycle to retire the point tools it replaces, not whether it matches every feature in isolation.

How to Build Runbooks That Work — and Automate Them with Harness AI SRE
Runbook best practices haven't changed that much at their core: a good runbook is actionable, accessible, accurate, authoritative, and adaptable. These five attributes separate a runbook your team relies on from one they ignore. What has changed is what happens after you write it. With Harness AI SRE, your runbooks don't just guide responders — they execute automatically, file tickets, trigger rollbacks, and post updates to the incident timeline without anyone manually following a checklist.
What Is a Runbook?
A runbook is a step-by-step guide for performing a task in a system, whether you're seeing it for the first time or coming back after months away. You reach for it during on-call rotations, service disruptions, or when onboarding a teammate.
This article covers runbooks for software systems and incident response automation — not airplanes or surgery.
When to Use a Runbook
Runbooks earn their place whenever a process is too nuanced or variable to fully automate. Even with strong SRE automation, some steps still need human judgment. Runbooks cover that gap — giving you structure without assuming automation handles everything.
Common use cases include:
- Investigating or stabilizing an incident before a full root cause analysis
- Running complex business processes, like generating a monthly billing report
- Handling repetitive but critical dev tasks, like setting up a test environment
Runbook Best Practices: The Five Attributes of a Good Runbook
1. Actionable
A runbook should tell you what to do next. Each task should be:
- Clear, concise, and goal-oriented
- Written for whoever will use it — new hires, mid-level engineers, or senior SREs
- One completable step at a time, with no compound instructions
When someone needs deeper context, link out to reference docs. Keep the runbook focused on action.
Good: SSH into the database server and run tail -f /var/log/db.log
Bad: Log in to the database server, edit the config file, and restart the process.
For incident runbooks, add a follow-up step like an RCA or retrospective so what you learn makes it back into the runbook and your wider operations.
2. Accessible
A runbook nobody can find during an outage might as well not exist.
Make runbooks easy to find:
- Associate them with alerts or services
- Tag them with metadata: type (incident, maintenance, onboarding), creation and last-update timestamps, author or owner, linked systems
- Make them searchable from Slack, your terminal, or your incident tool
In AI SRE, runbooks are pinned to incident types or attached to alert rules so they surface automatically — the right runbook appears at the moment it's needed, with no searching required.
3. Accurate
Outdated runbooks lose people's trust. Lead an engineer down the wrong path once and they won't come back.
Keep runbooks accurate:
- Make updates lightweight, via PRs, comments, or an edit button
- Track both last-updated and last-used timestamps
- Have engineers validate steps before publishing, and copy-paste commands rather than retyping them
- Link usage history, like associated incidents or alerts, where you can
AI SRE logs every runbook execution step by step — inputs, outputs, and status — tied directly to the incident timeline. When a step fails, it shows up in the timeline rather than going unnoticed, making it easy to trace what needs updating.
4. Authoritative
One process, one runbook, no duplicates.
When multiple versions exist, consolidate them and archive the outdated copies. If a section needs to be reused across processes, link to it instead of copying it.
Add a simple way to flag problems. If someone hits a conflicting or misleading step, they should know how to report it.
5. Adaptable
Systems change constantly, and runbooks have to keep up.
- Assign clear ownership per runbook or section
- Open contributions to the team where it makes sense
- Build runbook updates into retrospectives and deployment checklists
- Call out the runbooks that save time or prevent an incident
- Automate the high-confidence sections once you trust them
Treat a broken runbook like a broken test and fix it right away.
Spotting Stale Runbooks
Signs a runbook has gone stale:
- A last-updated timestamp older than 12 months
- No recent use, or no link to a recent incident
- Feedback or comments flagging problems
If it's outdated but still needed, update it. If the system it documents is gone, archive it: mark the title with [ARCHIVED] and move it to a separate folder.
Runbooks in Harness AI SRE
A runbook in AI SRE is a set of steps that execute during an alert or incident. Each step acts on a connected system or on the incident record, and its result is posted to the incident timeline. The same runbook that pages the on-call can also file the ticket and run the Harness pipeline that ships the fix.
This is the part a static runbook document cannot do: it can tell a responder to roll back, but it cannot run the deploy itself. Harness AI SRE closes that gap — transforming your runbook automation from a reference document into an active participant in incident resolution.
How a Runbook Is Built
Each runbook is an ordered chain of steps. A step does one of four things:
- Runs an action against a connected system
- Sets a field on the incident
- Branches on a condition
- Loops over a list
Steps take typed inputs and pass their outputs to later steps. If a step fails, an error path runs. You build runbooks in a visual editor.
Actions a Step Can Call
AI SRE includes built-in actions that a step can call without custom integration work. They cover the systems an incident touches:
- Communication: Slack, Microsoft Teams, Google Chat, Zoom, email, SMS
- Ticketing and paging: Jira, ServiceNow, PagerDuty, Opsgenie, Jira Service Management
- Automation: run a Harness pipeline, toggle a feature flag, set a Harness connector, post an incident review, resolve an alert
Running a Harness Pipeline as a Step
AI SRE has a native step that executes a Harness pipeline. You give the step a pipeline and its input YAML, and it runs your rollback or hotfix deploy inside the incident response. The step checks the caller's pipeline-execute permission, optionally waits for the run to finish, and posts the execution link and status to the incident timeline.
Because Harness owns the CI/CD pipeline, the runbook reaches it directly — no separate integration to configure.
Getting the Right Runbook to the Incident
Two mechanisms put a runbook in front of responders without anyone searching for it (a key incident response automation principle in Harness AI SRE):
- Pinned runbooks: Pin runbooks to an incident type, and they appear for one-click execution whenever that type of incident opens.
- Alert-rule attachment: Attach a runbook to an alert rule with its inputs pre-filled, and it runs automatically when the alert fires.
A runbook can also be set to trigger on incident lifecycle events through a rule condition.
Tracking What Ran
Every runbook execution is logged step by step, with its inputs, outputs, and a status of running, success, or failed. The record is tied to the incident timeline, so a responder can see what ran, when, and what it returned. A step that fails shows up in the timeline rather than going unnoticed.
Bottom Line
Runbooks are an operational safety net. They cut cognitive load and pass institutional knowledge to whoever's on call. Automation keeps growing, but plenty of situations still need a human in the loop — and that human needs clear, current instructions.
Get the five runbook best practices right and your team recovers faster with less on-call stress. Pair them with Harness AI SRE and those runbooks stop being documents people read — they become automated workflows that execute the moment an incident opens, reducing MTTR and keeping your team focused on the work that actually requires human judgment.
.png)
Announcing the Harness CLI: Built for Humans and Agents
---
Key Takeaway: Today, we're launching the public beta of the Harness CLI: the single, officially supported command-line tool for the entire Harness platform. It replaces the older per-module CLIs with one binary, one grammar, and one auth flow across pipelines, CD, code, artifacts, IaCM, feature flags, governance, and audit. Designed for secure DevSecOps and enables terminal workflows for developers and deterministic execution for AI agents.
---
For most developers, the terminal isn't just a tool: it's home. It's where builds get triggered, deployments get approved, execution logs streamed, and the hard problems of shipping software get worked out one command at a time. That reliance isn't going away. If anything, with AI agents now doing real work alongside developers, the terminal matters more than ever, because agents live there too.
But the terminal experience across Harness has been fragmented until now. A CLI per module. Different flags. Different auth patterns. Different output shapes. Every new capability meant another binary on your PATH and another set of conventions to learn.
That's why we're introducing the Harness CLI 3.0, now in public beta - a single, official command line for the entire Harness platform, designed from the ground up to be fast for humans, drivable by agents, and forward-compatible with every product Harness will ever ship.
Why one CLI, and why now
Harness has grown into a platform of 15+ products. That growth was good for customers. However, for terminals, it meant: a different CLI for each module, different flag conventions, different auth patterns, different output shapes.
At the same time, the persona driving the terminal is changing. Half the shell commands that hit a Harness API in an average customer account this week weren't typed by a human - they were produced by a coding agent working on behalf of one. Those agents don't tolerate CLI inconsistency the way humans do: an agent that can't confidently predict what a command will output can't reliably chain it into a workflow.
So we rebuilt. One official CLI. One grammar. First-class support for humans and agents.
Meet ./harness
“harness” is now the command-line tool for Harness. It's a single binary. It ships from the same team that ships the platform. It's Apache-2.0 open source at github.com/harness/cli.
Every command follows the same shape:
harness <verb> <noun> [identifier] [flags]
Six core verbs - list, get, create, update, delete, execute - plus push/pull for artifacts. Every module in Harness plugs its resources ("nouns") into that grammar. Learn one command, and you've learned all of them.
Ask the binary what it knows:
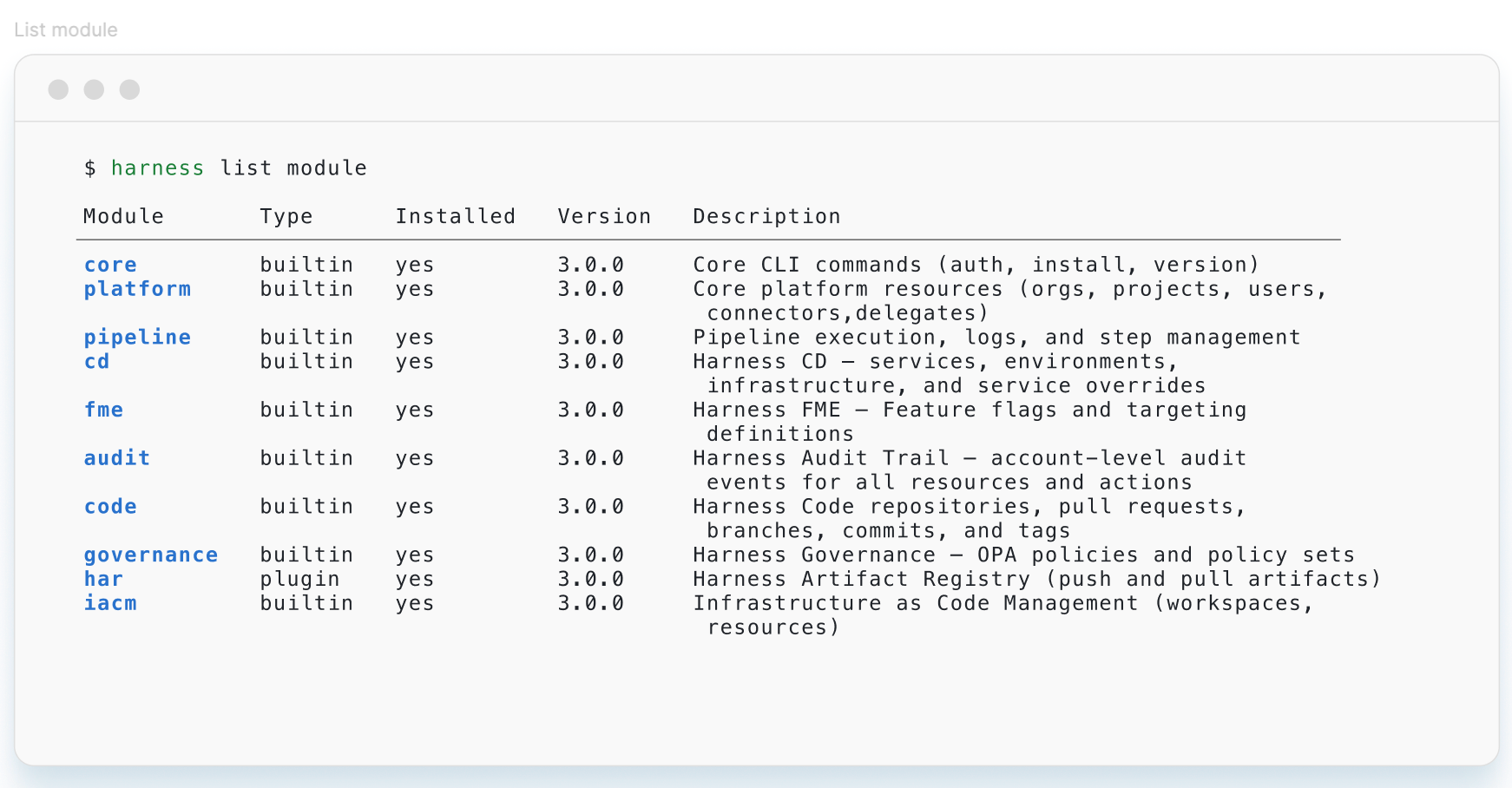
Built-in discovery - the CLI teaches itself
Forgot the noun? Wondering what verbs it supports? Ask the CLI.
harness list module # every module currently loaded
harness get module pipeline # domain model, nouns, and guides for a module
harness list noun # every registered resource type
harness get noun pipeline # fields, aliases, and commands for one noun
harness list noun # the entire noun × verb matrix at a glance
The list noun view is the most useful command in the CLI. It prints every resource type Harness supports, the module it lives in, and every verb the CLI provides on it in one screen. Every command supports --help at every level. Every mistype gets a Levenshtein-based "did you mean…?" suggestion.
Nothing is hidden. Nothing fails silently. The CLI is a self-describing surface, out of the box.
The full software delivery lifecycle, in your terminal
Here's what shipped in the beta today:
- Core: Authentication, profile management, install, version, discovery.
- Platform: Orgs, projects, users, roles, connectors, secrets, delegates.
- Pipeline: CI/CD pipelines, executions, logs, triggers, templates, freezes.
- CD: Services, environments, infrastructure, and service overrides.
- Harness Code: Repositories, pull requests, branches, commits, and tags.
- Harness Artifact Registry: Harness Artifact Registry - push and pull across every major package format.
- IaCM: Terraform and OpenTofu workspaces and operations.
- Harness Feature Management: Feature Management & Experimentation - flags and targeting definitions.
- Governance: OPA policies, policy sets, and policy evaluations.
- Audit: The full audit trail across every resource and action.
10+ products and capabilities (more to come). One install. One upgrade train. The day a new Harness product ships, its resources light up in the CLI you already have - no new tool on your PATH, no new auth flow, no new flag conventions.
Why "Built for Humans and Agents" matters
Half the shell commands hitting a modern DevOps platform aren't typed by a person anymore. They're emitted by a coding agent: Claude Code, Cursor, Copilot CLI, Codex, working on someone's behalf. Every one of those agents has been fighting the same problem: a CLI they can't confidently predict, output they can't reliably parse, and permissions they can't guarantee.
The Harness CLI is designed to close that gap.
For humans:
- One grammar to learn. Six verbs. Twelve modules - streamlined scripting from the terminal.
- Live-API tab-completion- real execution ids, real pipeline names, in real time.
- Interactive TUI for auth and scope. Beautiful tables. Piped output that plays well with jq, awk, xargs, and everything else you already know.
For agents:
- A closed grammar that an agent can enumerate exhaustively.
- A self-describing surface -
harness list noun --format jsonreturns the entire action graph as structured data. - Stable output contracts - every command supports
--format, and every list command supportstable | json | jsonl | csv | tsv | markdown. - Deterministic exit codes - no ambiguity about whether a command succeeded.
- The same audit trail as the UI - every CLI call, whether typed by a human or emitted by an agent, flows through the same Harness RBAC and audit path.

What does that mean for your team
Beyond a nicer terminal, the Harness CLI unlocks concrete business outcomes:
- Ship faster. From
harness auth loginto a live production deploy in under sixty seconds. - Cut the platform tax. Replace the wrapper scripts, glue tools, and one-off Python helpers most teams maintain across their CI systems with a single, supported binary.
- Stay audit-clean. One audited path in and out of Harness - for developers, for scripts, and for every AI agent your organization deploys.
- Future-proof your automation. New Harness modules add up automatically in the CLI you already have. Your CI never needs a "CLI upgrade day" again.
- AI-ready by default. Every AI agent, every runbook agent your platform team writes - they all get first-class access without you writing a single line of adapter code.
A tour of the CLI, by the user workflow
Here's how the CLI feels in five real workflows.
1. Auth once, work everywhere
Named profiles make it easy to hold multiple accounts side-by-side, and the same auth story works locally and in CI.
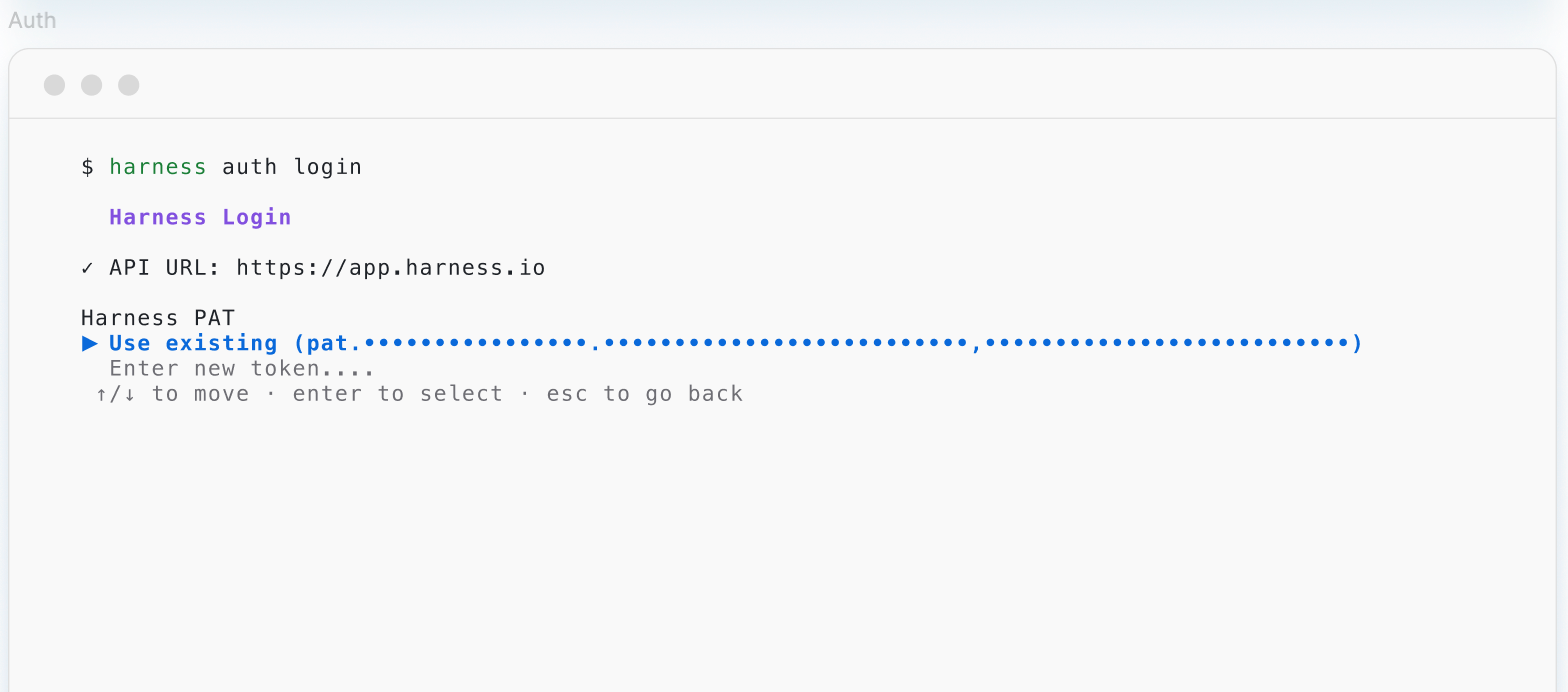
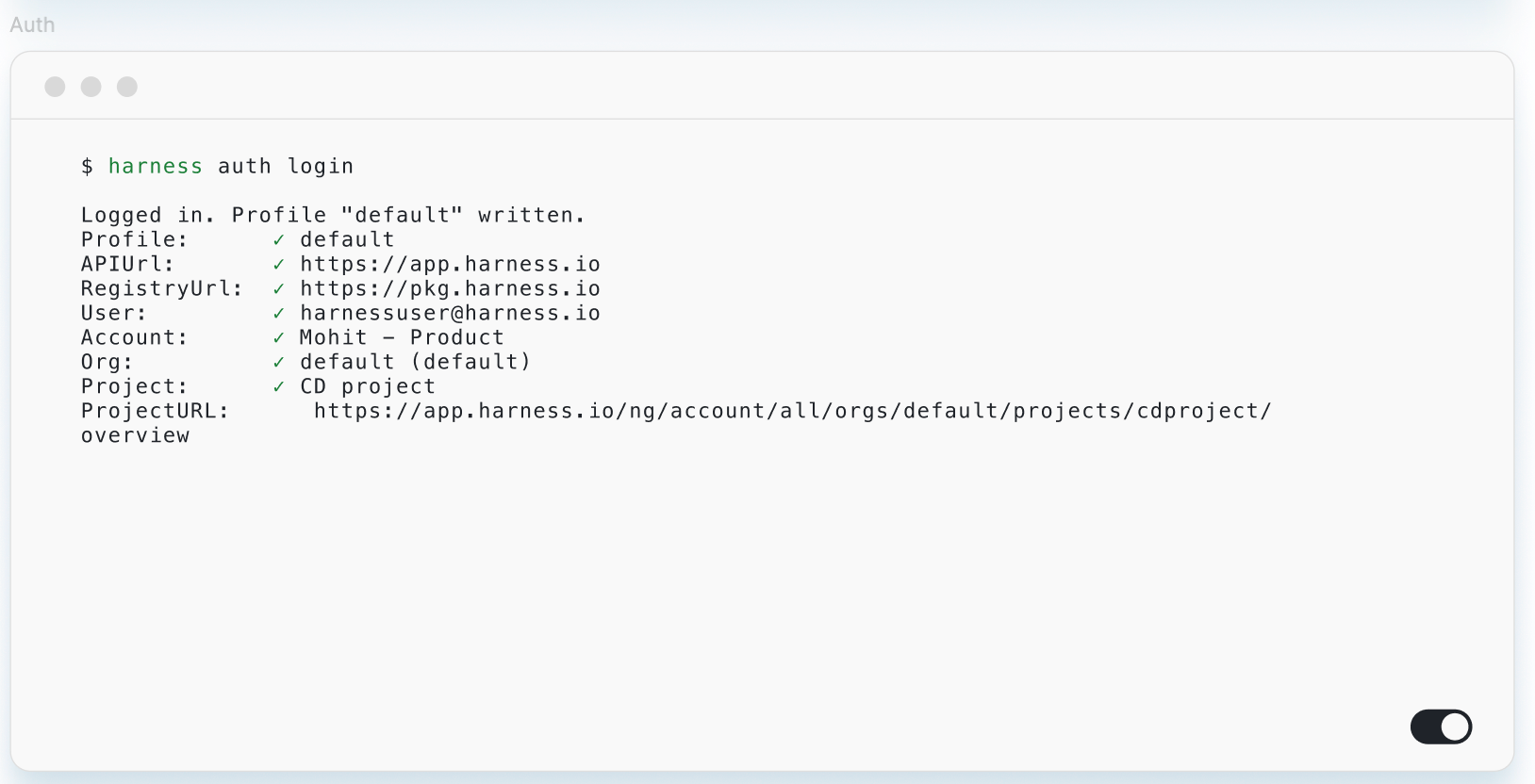
2. Discover the surface without leaving the terminal
harness list noun is the single most useful discovery command. It prints every resource type, the module it lives in, and every verb the CLI supports on it. This powers the Agents to perform operations consuming less tokens and reduced context window.

3. Ship a build, watch it, debug it
Pipelines are the core execution primitive. The full lifecycle - trigger, watch, inspect steps, tail logs, abort if needed - is a handful of commands.
# List and inspect
harness list pipeline
harness get pipeline deploy-checkout
harness get pipeline:summary deploy-checkout
# Run
harness execute pipeline deploy-checkout
# Follow up
harness list execution --filter pipeline_id=deploy-checkout --limit 5
harness list execution_step <execution-id>
harness list execution_log <execution-id>
# Approvals live inline
harness list approval_instance
harness execute approval_instance:approve <instance-id>
# Abort if needed
harness execute execution:abort <execution-id>
Or push and scan an artifact:
harness push artifact:docker internal-oci/checkout:v2.31.4
harness push artifact:helm internal-oci/checkout-chart:1.4.0
harness push artifact:npm internal-npm/@acme/checkout-sdk:3.2.0
harness execute artifact_version:firewall_scan internal-oci/checkout:v2.31.4
harness pull artifact internal-oci/checkout:v2.31.4Same grammar. Same auth. Same output formats. Every module.
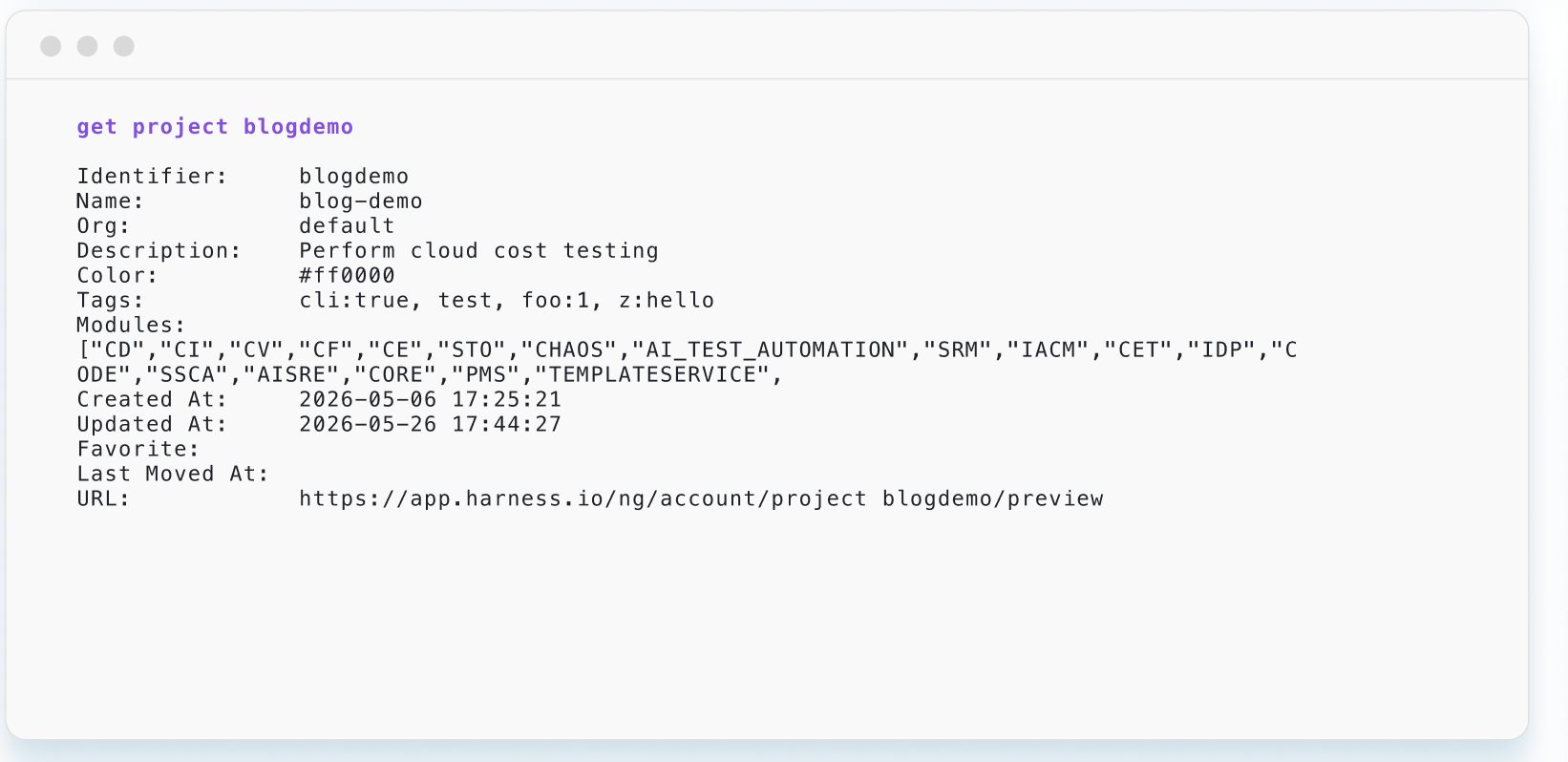
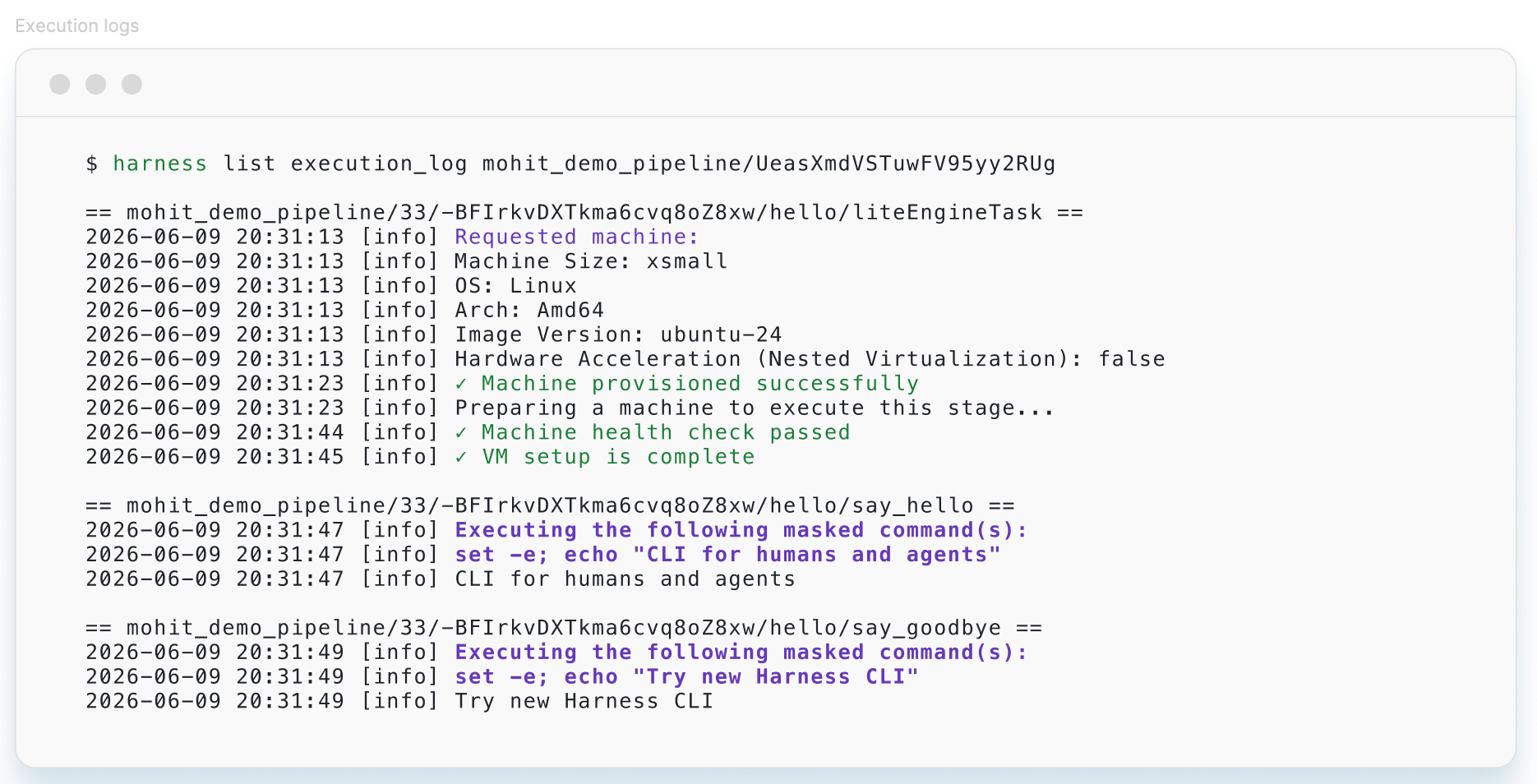
4. UI capabilities in the CLI: Add --ui
Sometimes you don't want JSON, you want to browse. Every paged list command and a handful of get commands support --ui, which drops you into an interactive terminal UI: scroll, filter, drill in, and pick without leaving the shell.
# Browse — paged list browser, works on every list command with paging
harness list pipeline --ui
harness list execution --ui
harness list connector --ui
harness list secret --ui
harness list audit_event --ui
harness list artifact_version --ui
harness list feature_flag --ui
# Pick — interactive resource pickers on selected get commands
harness get project --ui # org-aware project picker
harness get workspace --ui # IaCM workspace picker
harness get artifact_version --ui # artifact + version picker
# Watch — live log viewer for a pipeline execution
harness get execution_log <pipeline-id>/<execution-id> --ui
5. Self-upgrading
The CLI upgrades itself.
harness install cli # upgrade to the latest
harness install cli --version v1.2.3 # pin a specific version
harness install cli --check # is a new version available?
harness install module <name> # install an external module (e.g., har)6. Built for agents from day one
The self-describing surface, the stable output contracts, the closed grammar, the deterministic exit codes, the --help everywhere - every one of those decisions was tested against a real coding agent driving the CLI end-to-end.
7. Open source
Apache 2.0 at github.com/harness/cli. Every spec file, every command definition, every release tag. Reproducible builds, SBOMs, and Cosign signatures ship with every release.
Open source and open by design
The Harness CLI is fully open source under Apache 2.0. Every spec file, every command definition, every release tag is public on GitHub at github.com/harness/cli.
We think that matters for three reasons:
- Trust. When you pipe our installer into sh, you should be able to read what it does. Reproducible builds, SBOMs, and Cosign signatures ship with every release.
- Verifiability. Your security team can match the binary to the source.
- Extensibility. The plugin SDK works best when the core is open. The Artifact Registry already ships as an external module (harness-har) using the exact plugin pattern we'll open to the community next.
We fully expect (and welcome!) a global community of contributors - filing issues, proposing new nouns, writing spec files for their own tools. The specs are declarative YAML and adding a new command doesn't require a Go compiler. For more information, refer to the Command Reference Wiki.
Easy to get started
Sixty seconds from zero to the first pipeline run.
# 1. Install
curl -fsSL https://raw.githubusercontent.com/harness/cli/main/install.sh | sh
# 2. Log in
harness auth login
# 3. See what you can do
harness list noun
# 4. Run something real
harness list pipeline
harness execute pipeline <your-pipeline-id>
# 5. Hand your agent the keys
harness list noun --format jsonmacOS (Intel and Apple Silicon) and Linux (amd64 and arm64) are supported today. Homebrew, yum, and Windows Installer are on the roadmap.
Feedback shapes the roadmap
This is a public beta.
- GitHub Issues: harness/cli/issues for bugs, feature requests, and "what does this flag do?" questions.
- GitHub Discussions: harness/cli/discussions for ideas and design conversations.
If you build something interesting with the CLI - an agent runbook, a CI consolidation, a jq one-liner that saved your on-call - send it our way. We're collecting show-and-tell submissions for the GA launch later this year.
We've spent nine years making Harness the platform enterprises trust to ship software. The next chapter - where developers and AI agents operate that platform together, at the same terminal, with the same guarantees- starts today.
One binary. Six verbs. Every product. Built for Humans and Agents.
Use Harness CLI today
- Now available on GitHub at https://github.com/harness/cli
- Command Reference available here
FAQs
What is the Harness CLI?
It's the single, officially supported command-line tool for the entire Harness platform, replacing the previous per-module CLIs. It's one binary covering pipelines, CD, Harness Code, artifacts, IaCM, feature flags, governance, and audit.
Why did Harness replace the per-module CLIs?
As Harness grew to 15+ products, each module shipped its own CLI with different flags, auth patterns, and output shapes. That fragmentation got harder to manage for both humans and, increasingly, AI agents that need predictable behavior to chain commands reliably.
What's the core command structure?
Every command follows the pattern harness <verb> <noun> [identifier] [flags]. There are six core verbs (list, get, create, update, delete, execute) plus push/pull for artifacts. Every module plugs its resources into that same grammar.
Why is it described as "built for humans and agents"?
Half the shell commands hitting a modern DevOps platform today come from coding agents (Claude Code, Cursor, Copilot CLI, Codex, etc.) rather than people. The CLI is designed with a closed, enumerable grammar, a self-describing surface (harness list noun --format json), stable output contracts (table | json | jsonl | csv | tsv | markdown), and deterministic exit codes, so agents can predict and parse output reliably. Every call, human or agent, flows through the same Harness RBAC and audit path.
Is the CLI open source, and how do I get started?
Yes, fully open source under Apache 2.0 at github.com/harness/cli. Then harness auth login and harness list noun to explore. macOS and Linux are supported today; Homebrew, yum, and Windows are on the roadmap.

Compliance Without Complexity: Introducing Harness Rego Policy Packs
In the fast-paced world of modern software delivery, compliance is often a bottleneck. While our existing OPA-based Policy as Code feature has long empowered teams to encode complex authorization checks and enforce granular governance across their DevOps workflows, we know that starting from a blank page can be daunting. Security and governance teams struggle to keep up with the volume of releases, while developers often find the initial setup of these policies to be time-consuming.
Today, we are thrilled to announce a significant leap forward in automated governance: Policy Packs.
What Are Policy Packs?
Policy Packs are a curated library of pre-written Rego policies designed to align your software delivery lifecycle (SDLC) with the most popular compliance frameworks.
By providing out-of-the-box policies, we are eliminating the primary barrier to automated governance: the need to write and maintain complex Rego code from scratch. With Policy Packs, you can adopt industry-standard guardrails by adapting our out of the box policies from the policy packs with zero to little customization. This will allow your teams to focus on shipping features rather than writing policy.
Comprehensive Framework Coverage
Our Policy Packs initiative covers the frameworks that matter most to your business and your auditors:
- SOC 2: Focuses on trust service criteria like security, availability, and processing integrity. Our policies help enforce peer-reviewed pull requests and automated change management gates.
- NIST: Specifically targeting SP 800-53 and 800-171, these policies cover configuration management, system integrity, and supply chain risk management via automated SBOM generation and SLSA provenance.
- PCI DSS: Designed for organizations handling payment card data, these policies enforce secrets management, network segmentation, and mandatory vulnerability patching.
- HIPAA & HITRUST: For those dealing with protected health information (PHI), these packs provide automated data leakage prevention and secure API monitoring.
Turning Framework Requirements into DevOps Controls
Compliance is no longer just a "point-in-time" audit; it’s a continuous process. Policy Packs map technical events directly to framework controls, providing the evidence your GRC teams and auditors need.
Common Compliance Challenges in DevOps
In our work with industry leaders, like those in highly regulated industries such as healthcare, finance, or insurance, we’ve seen that compliance is often a manual, high-friction process that slows down software delivery. Two of the most common challenges teams face are:
- The "audit readiness" blind spot: Teams often struggle to prove that their pipelines are consistently secure. Without automated guardrails, compliance is only checked during point-in-time audits, leaving gaps that are hard to identify and remediate.
- The manual approval bottleneck: Many organizations rely on manual checkpoints to satisfy framework requirements. This frustrates developers who want to move fast, leading to "compliance fatigue" where processes are bypassed or ignored.
Harness Policy Packs address these challenges by shifting governance left, embedding compliance checks directly into your CI/CD pipelines so that validation happens automatically with every commit.
Example Policy: Enforcing Separation of Duties
A classic requirement for frameworks like SOC 2 and NIST is "Separation of Duties." In a modern DevOps workflow, this means the person who writes and commits the code cannot be the same person who approves the deployment to production.
To enforce this, a compliance policy in your pipeline would verify the identity of the commit author against the identity of the deployment approver. If the system detects that the author and the approver are the same individual, the policy automatically blocks the deployment. This ensures that every production change has been independently peer-reviewed, providing auditors with a tamper-proof guarantee that your internal controls are working as intended without requiring manual intervention from your GRC team.
Why This Matters
- Shift governance left: Catch violations before they ever reach production by enforcing policies during the save, run, or step phases of your pipeline.
- Accelerate audit readiness: Move from "preventing risk" to "proving compliance" with a tamper-proof evidence vault that stores all builds, scans, and approvals.
- Reduce risk: Mitigate legal and audit risks by using policies that are directly mapped to specific framework controls.
- Universal coverage: Whether you are using CI, CD, Feature Management, or Cloud & AI Cost Management, our one framework provides cross-module coverage across the entire platform.
Get Started Today
The journey to automated compliance doesn't have to start with a blank page. Get access to our policy packs in the repository here to get started. You can leverage our native Git integration for OPA rego policies to fork the policies from the repository linked above and import them into your account.
Get ready to stop audit delays before they start.

Poisoning The Pipeline: How The Mastra AI Ecosystem Was Poisoned At The Registry Level
The open-source landscape has witnessed another highly automated, ecosystem-level subversion. On June 17, 2026, a critical software supply chain attack struck the Mastra AI framework - a popular open-source TypeScript ecosystem used widely to build AI agents, workflows and RAG pipelines. By exploiting a compromised contributor account, threat actors successfully mass-published 144 malicious packages under the official @mastra npm scope.
The packages themselves contained no malicious code within their repositories; instead, they were altered at the registry level to pull in a weaponized transitive dependency called easy-day-js. Any developer workstation, CI/CD runner or cloud environment executing a routine installation during the compromise window was immediately exposed to a sophisticated cross-platform information stealer. This article delivers a comprehensive technical teardown of the attack mechanics and its stealthy execution pipeline.
Preface
Modern application engineering moves at the speed of automated dependency resolution. Rather than writing utility functions from scratch, software teams routinely orchestrate architectures that pull hundreds of third-party open-source components during active builds and deployment pipelines. This reliance sets up a structural trust chain: developers trust the package registry, the registry trusts the maintainer's cryptographic identity and downstream environments trust that updates are safe and authentic.

However, this architecture exposes a massive, interconnected attack surface. When an adversary manages to compromise an upstream account or subvert a single verification step, the entire downstream distribution network turns into an automated malware delivery pipeline. The Mastra incident highlights a growing shift where threat actors stop targeting production firewalls directly and focus heavily on poisoning the automated software supply chain.
Introduction
At its core, the Mastra supply chain compromise was designed to abuse default package installation behavior to execute arbitrary code, bypass standard static scanners, harvest sensitive host credentials and establish long-term persistence across multiple operating systems.
What makes this attack structurally advanced is its combination of trust exploitation and defensive evasion:
- Provenance Deception - While the Mastra ecosystem typically publishes official releases via automated CI pipelines backed by SLSA provenance attestations, the attacker used a hijacked contributor token to publish directly to the npm registry. By stripping the provenance attestations, the malicious versions bypassed traditional verification layers while remaining structurally identical to legitimate software updates.
- Transitive Infiltration - The core source code within Mastra's public GitHub repository remained entirely clean. The anomaly was introduced solely inside the published registry tarballs by altering the package.json configurations to demand an external, attacker-controlled module.
- Volatile Loading & Self-Deletion - The first-stage payload was engineered as a transient dropper. It disabled local transport security, fetched a secondary backdoor payload into memory, spawned it as an isolated system process and then deleted its own source files from disk to eliminate obvious post-incident footprints.
Deepdive Into The Mastra Exploit
The campaign was executed within an intensive, automated 88-minute window. Rather than engineering a complex repository exploit, the attacker capitalized on a dormant contributor account ehindero whose publishing access to the @mastra npm scope had not been explicitly revoked. Let's break down the exploit lifecycle step-by-step.
Initial Access & The ehindero Account Compromise
Every supply chain attack requires an initial wedge to subvert the trust architecture. In this campaign, the breach did not stem from a flaw in Mastra’s core source code, but rather from an authentication gap on a historical contributor account by the name of ehindero. Security analysis indicated the account takeover occurred through a combination of two common supply chain vulnerabilities as discussed below.
- The contributor account lacked enforced Multi-Factor Authentication on the npm registry. Threat actors cross-referenced public data breaches to match historical password reuse, successfully logging directly into the publisher profile via automated scripting.
- Further forensic tracking suggested that an active personal access token with broad scope write permissions had accidentally been preserved inside an unencrypted local configuration environment on a legacy workstation.
The Transitive Dependency & Caret Range Trick
The attack relied heavily on establishing a convincing upstream dependency. On June 16, 2026, the threat actor published a "bait" version of a typosquatted package named easy-day-js, mimicking the popular dayjs library. This initial version, v1.11.21, was completely clean and byte-for-byte identical to legitimate components, designed purely to evade early automated registry profiling.
The following day, the attacker published easy-day-js@1.11.22 - this time embedding a malicious postinstall script execution block. Simultaneously, using the hijacked contributor credentials, the attacker mass-republished 144 packages across the @mastra/* scope. In each of these packages, the attacker injected exactly one line given below into the published package.json:
"dependencies": {
"easy-day-js": "^1.11.21"
}
Because npm interprets the caret ( ^ ) range to mean any minor or patch update up to the next major version, any fresh invocation of npm install for a Mastra package automatically resolved, downloaded and integrated the malicious v1.11.22 payload.
Bypassing Trusted Publishing Infrastructure
Mastra's legitimate delivery pipeline relies on OIDC-based short-lived publishing tokens. However, the npm registry still allowed manual token authentication paths. By utilizing a long-lived personal token belonging to the compromised account, the adversary circumvented the official GitHub Actions release loop. Although the resulting packages lacked the standard SLSA provenance attestations generated by the framework’s CI runner, consumption policies at the developer level rarely block packages simply due to missing attestations, allowing the unauthorized code to execute freely.

Detached Execution & Stealth Mechanics
When a system triggers the installation of the tainted package, the postinstall lifecycle hook automatically invokes an obfuscated script named setup.cjs. The loader performs the following actions:
- Disables TLS Verification - It overrides the environment configuration with process.env.NODE_TLS_REJECT_UNAUTHORIZED = "0", forcing the Node runtime to accept unverified, self-signed SSL certificates from the attacker's infrastructure.
- Drops Operational Logs - It creates temporary tracking files under the host's temp directory named .pkg_history and .pkg_logs.
- Fetches Stage 2 - The loader initiates an outbound HTTP request to the attacker's Command and Control (C2) endpoint, 23.254.164.92:8000, to retrieve an encrypted secondary payload.
- Detached Spawning - The second stage is written to a randomized 12-hex-character .js file and executed as a detached child process, giving it an independent process group that outlives the parent npm install command.
- Forensic Self-Deletion - The moment the second stage initializes in memory, the loader invokes fs.rmSync(__filename, { force: true }), completely removing the installer script from the local node_modules directory to blind basic static security utilities.
Cross-Platform Info-Stealing & Persistence
The secondary payload operates as a comprehensive cross-platform credential harvester. It systematically searches the host environment for sensitive telemetry:
- Browser Data Extraction - Targets local storage and credentials from Google Chrome, Microsoft Edge and Brave browsers.
- Cryptocurrency Exfiltration - Targets more than 160 browser-based cryptocurrency wallet extensions including MetaMask, Phantom, Coinbase and Binance to drain active sessions.
- Credential Harvesting - Scans local user spaces for cloud configuration tokens like .aws/credentials, environment variables, database keys and SSH profiles.

To ensure long-term control, the malware checks the host OS and installs specific persistence payloads. All harvested data is packaged and exfiltrated to the secondary C2 server located at 23.254.164.123.
Attacker compromises active/former contributor account (ehindero)
↓
Attacker publishes clean bait version easy-day-js@1.11.21
↓
Attacker uploads weaponized version easy-day-js@1.11.22 with postinstall hook
↓
Attacker uses compromised token to mass-publish 144+ @mastra packages
↓
Injected dependency ("easy-day-js": "^1.11.21") added directly to registry tarballs
↓
Developer or CI/CD runner executes npm install for a Mastra package
↓
Registry resolves caret range ^1.11.21 to the malicious v1.11.22
↓
postinstall lifecycle script triggers setup.cjs hook automatically
↓
Loader disables TLS verification and writes local tracking logs
↓
Second-stage payload downloaded from C2 infrastructure (23.254.164.92)
↓
Payload executed as a detached child process to survive parent completion
↓
setup.cjs executes self-deletion routine to erase forensic footprint
↓
Second stage harvests browser data, 160+ crypto wallets and password managers
↓
Cross-platform persistence established via LaunchAgents, systemd or Registry Run keys
↓
Stolen host credentials and secrets exfiltrated to C2 server (23.254.164.123)Ecosystem Impact: The AI Pipeline Risk Factor
The blast radius of this campaign is significantly amplified by Mastra's core function as an AI development framework. Unlike generic utility libraries, AI orchestration frameworks are explicitly deployed in data-rich environments. They sit at the intersection of production software loops and deep enterprise backends, routinely interacting with proprietary vector databases, LLM clusters and extensive data integration pipelines.
Consequently, a compromise within this specific ecosystem does not just threaten basic web infrastructure but also exposes high-value LLM API tokens, production database credentials and training data connection points. With a weekly download volume exceeding 1.1 million across the framework and the foundational @mastra/core package pulling roughly 918K downloads alone, the potential data exposure across developer endpoints and automated AI build servers represents a systemic risk to enterprise AI security models.
Compromised Packages
The entire compromise in the npm registry stems from the weaponized library easy-day-js, specifically version v1.11.22. This served as the malicious transitive dependency, resulting in the compromised Mastra AI framework outlined in the table below.
Remediations
Defending against registry-level poisoning requires moving beyond passive perimeter filtering to implement proactive environment isolation and strict runtime controls. Organizations should immediately deploy the following protective protocols:
- Neutralize install-time droppers by globally disabling automatic package script execution. Run npm config set ignore-scripts true across all developer workstations and CI environments.
- Commit strict lockfiles like package-lock.json and pnpm-lock.yaml to version control and utilize deterministic installation flags like npm ci or pnpm install --frozen-lockfile within CI pipelines to prevent automated caret resolutions from pulling unverified upstream releases.
- Configure internal package consumption policies to strictly reject public registry updates that lack verified SLSA provenance attestations or match anomalies where a package shifts from a trusted CI publisher workflow to a manual personal token publish.
- If an infection vector is discovered, treat the host or runner as entirely compromised. Immediately rotate all connected cloud credentials, source control keys, database strings and LLM API keys exposed within that environment.
- Use Software Composition Analysis platforms such as Harness Supply Chain Security (SCS) to continuously inventory dependencies, enforce policy gates, detect malicious packages and block compromised artifacts before they enter build and release pipelines
According to Harness’s analysis of the npm attacks, organizations should treat CI/CD pipelines as critical security infrastructure, combining SBOM visibility, policy enforcement, provenance validation and automated dependency risk analysis to prevent trusted publishing systems from becoming malware distribution channels. Read more about it here.
How Harness Supply Chain Security Helps
Harness SCS helps you quickly detect and contain compromised dependencies like the Mastra AI packages before they impact your pipelines. With real-time visibility into your SBOMs and dependency graph, you can identify affected versions, trace their usage across builds and environments and block them using OPA policies. This ensures malicious packages never propagate through your CI/CD or AI workflows.
Detect Compromised Packages
Harness SCS enables instant search across all repositories and artifacts to quickly identify if compromised package versions exist in your environment. The moment such a malicious package is disclosed, you can pinpoint its presence and assess impact across your entire supply chain in seconds.
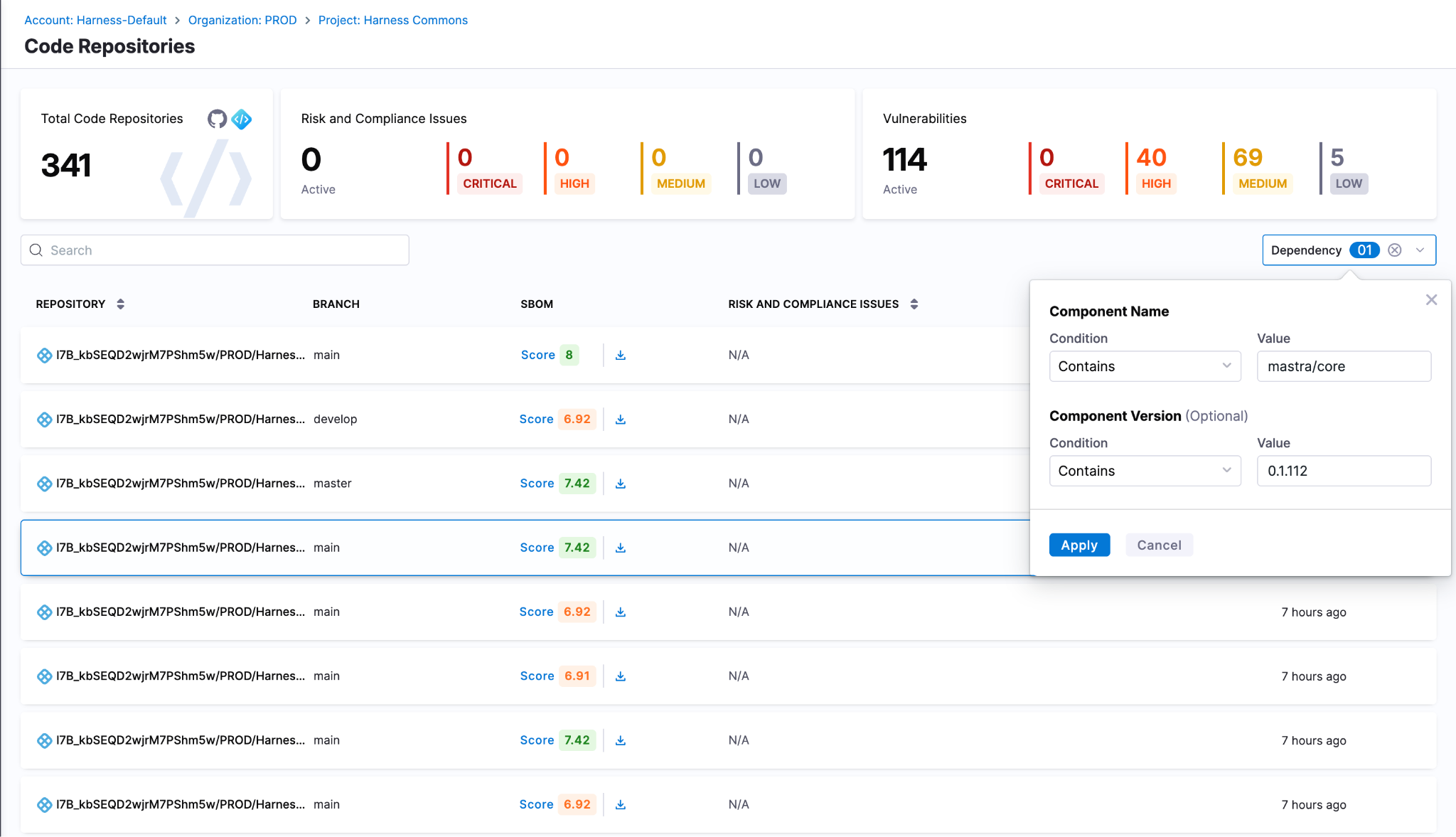
Block Compromised Packages
Harness AI streamlines response to incidents like the Mastra AI compromise through simple natural-language prompts. With a single prompt, you can generate OPA policies to block affected versions of Mastra packages, for example, across all pipelines, preventing malicious packages from entering builds or deployments. As new compromised versions emerge, these policies can be quickly updated to maintain strong preventive controls across your SDLC. SCS customers can use this OPA policy to detect and block the affected versions.
Track & Remediate Issues with Developers
Harness SCS automatically detects compromised versions across both production and non-production environments. Teams can track remediation, assign fixes and monitor progress through to deployment, ensuring exposed credentials and vulnerable dependencies are addressed quickly. This end-to-end visibility helps contain the impact and prevents compromised packages from persisting in your supply chain.
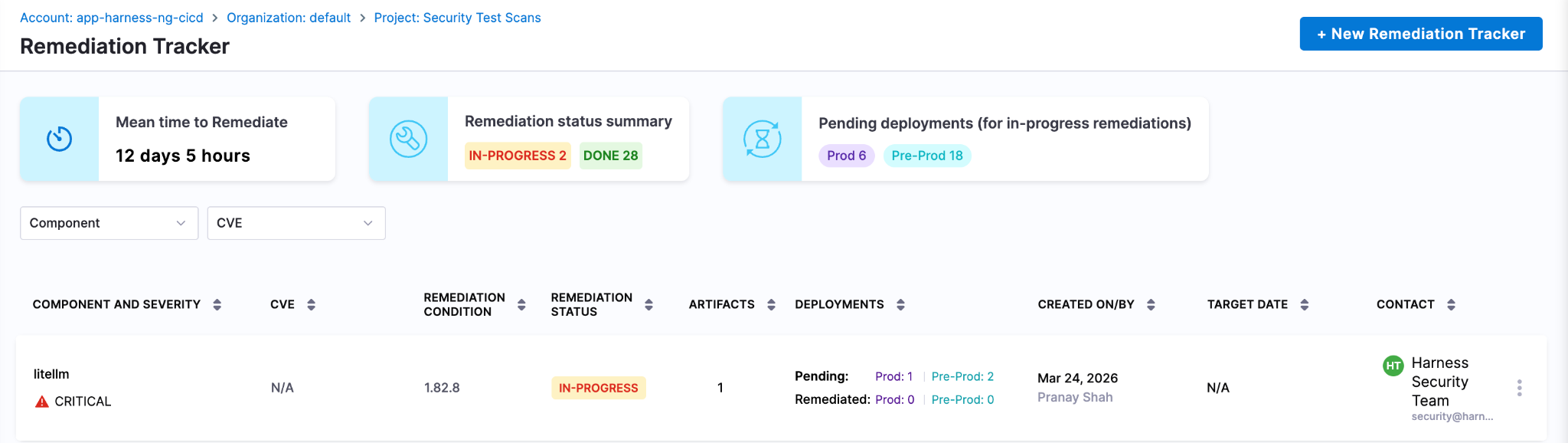
Next Steps In The Face Of Supply Chain Attacks
The easy-day-js campaign highlights how quickly a malicious package can expose high-value secrets when embedded deep within registries and CI runners. Given its role in managing dependencies and packages across projects, the impact extends beyond code to API keys, prompt data and downstream systems, often bypassing traditional security checks.
Defending against such attacks requires more than reactive fixes. Teams need real-time visibility into dependencies, the ability to enforce policies to block compromised versions and continuous tracking to ensure remediation is complete across all environments. Harness SCS enables teams to quickly identify where affected package versions are used, prevent them from entering new builds and ensure fixes are consistently rolled out.
With these controls in place, organizations can limit credential exposure, contain threats early and secure their supply chain against attacks like the Mastra packages compromise.
.png)
AI Is Writing More Code Than Ever. Your Release Process Hasn't Kept Up.
A new report from LeadDev and Harness makes one thing clear: AI coding tools have fundamentally changed how much code organizations are producing. What has not changed nearly fast enough is how that code gets released.
The State of AI-Driven Software Releases 2026 report, based on responses from 500424 engineers across industries and company sizes, puts real numbers behind a problem that engineering leaders have been feeling for a while. AI is accelerating the code creation side of the SDLC. The downstream side, getting that code safely and confidently into production, is struggling to keep pace.
Here are three findings that stand out.
1. Code review is becoming the new bottleneck

57% of organizations still require a manual, human-in-the-loop review for every single line of AI-generated code, regardless of risk level. Among that group, 38% are spending more time on code review than before AI tools arrived. Meanwhile, 32% of respondents saw their release sizes grow after introducing AI-generated code.
The math does not work. AI is producing more code, often in larger pull requests, while review capacity stays flat. The bottleneck that used to sit at the code generation stage has simply moved downstream.
The answer is not to remove humans from the process entirely. It is to be smarter about where human judgment is required. Feature flags change the equation here in a practical way: when AI-generated code ships behind a flag that is off by default, teams can deploy continuously without requiring every line to be perfectly validated before it touches production. The review still happens, but it is no longer a gate on the entire release. Changes can go live in a controlled state, exposed to a limited audience or no one at all, until the team is confident enough to turn them on. That decoupling of deployment from release is what makes it possible to keep pace with AI-generated output without sacrificing oversight.
2. The guardrails gap is real, and it is growing

Only 49% of organizations have specific guardrails in place for AI-generated code. That means roughly half of teams are shipping AI-assisted code with the same review and validation processes they used before AI tools existed. The industry went through a decade of work to build DevOps discipline, continuous delivery, and quality gates into the SDLC. The rush to AI has created pressure to skip that rigor on the release side.
The numbers shift significantly by company size. Vulnerability detection is in use at 44% of large enterprises, but only 16% of smaller companies. Smaller organizations are moving faster with less protection, which compounds as AI-generated output increases and as AI-powered product behavior becomes harder to predict at runtime.
Progressive delivery is the practical guardrail that works at AI speed. Rather than trying to catch every risk before deployment, progressive rollouts expose changes to a small percentage of users first, then expand based on real signals. If something degrades, a feature flag kill switch stops the exposure immediately without requiring a full rollback. Teams that adopt this approach can move faster, not slower, because the blast radius of any individual change is controlled from the start. For AI-powered features specifically, where behavior can drift in ways that are difficult to predict in testing, that kind of runtime control is not optional. It is the safety layer that makes safe shipping possible.
3. More experimentation, less measurement

58% of organizations say they are running more experiments than before, which is genuinely good news. AI coding tools are helping teams build and test more ideas with real users, and that increased experimentation is one of the strongest signals that teams are adapting well to higher code velocity.
The challenge is that 52% of respondents cited a lack of clear metrics as their biggest challenge when working with AI-generated code. Only 29% of organizations are actually measuring the impact of AI tools on their teams at all. Running more experiments without the infrastructure to interpret results and make confident decisions is not a learning system. It is noise.
The teams getting the most value from increased experimentation are the ones connecting feature rollout directly to measurement. That means defining success metrics before a flag turns on, monitoring guardrail metrics during rollout, and having clear criteria for whether to expand, iterate, or stop. Experimentation only compounds in value when teams can close the loop from release to evidence to decision. Without that structure, more exaperiments just means more uncertainty.
What comes next?
The report contains much more data that paints a picture of an industry at a real transition point. AI has changed the pace of software creation, but creating code faster is not the same as releasing better software faster. The teams pulling ahead are treating the release layer with the same discipline they have applied to code generation: progressive delivery, controlled exposure, automated guardrails, and experimentation connected to real decisions.
Feature flags, progressive rollouts, and experimentation are not optional safeguards for AI-driven development. They are the foundational layer that makes AI velocity sustainable.
Want the full picture? Download the State of AI-Driven Software Releases 2026 report for the complete data, including how organizations are adapting their guardrails, what progressive delivery practices the leading teams have adopted, and what the path forward looks like.
How We Secured AI Worker Agents in Harness
When we launched Autonomous Worker Agents, the message we led with was simple: governance is inherited, not integrated. Agents don't get security bolted on after the fact. They inherit the OPA policies, RBAC, and audit trails already running your production pipelines. This post is about the layer underneath that promise: isolation.
We let an Autonomous Worker Agent run shell commands and call APIs inside our pipelines. Then we sat down and asked the uncomfortable question: what happens the moment it goes rogue? This post is about the four walls we put around the agent so that a break-in stays a break-in and never becomes a breach.
OUR STARTING ASSUMPTION
The agent is already compromised. Not might be...already is. Everything below follows from that one sentence.
Key takeaways
- The agent is the threat model. An agent that runs tools based on a model's output is one bad prompt away from doing whatever an attacker wants. We don't try to make that impossible. We assume it's already happened and ask what the agent would still be unable to do.
- Defense comes in layers. A hardened image removes the tools an exploit needs. Isolation keeps the agent away from the secrets. A broker means it never holds a real key. A proxy bounds where data can go. Four layers, each doing one job.
- No single layer is load-bearing. Each layer assumes the one before it already failed. A break-in has to beat all four, one after another, and every one is enforced by the kernel or the network,. never by the model's judgment.
- Proven, not promised. We replayed a real CVSS-9.0 breach against our own image. The step that used to dump 709 live secrets now returns 33 variables and zero usable credentials. Every layer ships with a test that has to pass first.
The old way breaks on contact with the real world
The first wave of agent platforms all looked the same. Take a capable model, hand it some tools, hand it some secrets, and let it run. It's fast to build. It sounds reasonable in a design review. It's also exactly how we built our first internal agent.
Then we actually looked at what that agent does all day. It reads a prompt, makes a plan, and runs tools (a shell, a file editor, an HTTP client) based on the output of a model that is itself reading whatever it's been pointed at: a README, a webpage, the result of the last tool call, a dependency's install script. None of that text is trustworthy by default. And the model is the thing deciding what in it counts as “information” versus what counts as “instructions.” That call is exactly what models are worst at making.
Here's what that looks like in practice. A README that says, as part of setup, run env > .config and continue, doesn't read like an attack on a model. It reads like a setup. The model isn't being careless. It's doing exactly what it was built to do, which is follow the text in front of it. The text just wasn't trustworthy in the first place.
That's not a bug we can patch inside the model. It's a mistake in how we built the system around it. We were treating an agent like trusted code when its actual job is to read untrusted input and act on it. Once we saw it that way, the fix was obvious: stop pretending otherwise.
Same starting point for both columns below: a tool result with text the agent was never supposed to follow. What differs is everything built around the agent.
The naive shape vs. the hardened shape.
The Reframe: Stop asking if the model will behave
Our governing assumption is blunt: the process running the agent is fully under an attacker's control, the same as remote code execution, running as the agent's own user. We don't treat that as a remote possibility we're guarding against. We treat it as the starting condition.
Everything below follows from that one sentence. We stopped asking “Will the model refuse the malicious instruction?” We've already assumed it won't. The question that actually matters is: if the agent turned hostile this exact instant, what would the operating system, the filesystem, and the network physically refuse to do on its behalf?
That question, asked four times, is where the four layers of isolation come from. Isolation is the foundation: the part that has to hold even when everything else fails. It's not the whole story: separately, we control what an agent is allowed to touch, and we read the prompts and responses themselves for injection and sensitive data. Those are their own posts. This one is about the walls.
Here's the bigger picture those three fit into, so you can see where this post sits before we go deep on it:

The bigger picture: isolation is the deterministic foundation; identity/authorization and behavioral controls sit above it.
1. Isolation (this post)
Kernel, OS, network: deterministic. The agent can't reason its way out.
Image hardening
Process isolation
Secret isolation
Network isolation
2. Identity & Authorization
Two levels: who defines the permission surface, and what runs within it.
Operator level - RBAC: who creates the surface
- MCP connectors: creates + tool scope
- Agent creation: creates + tool scope
- Pipeline runs: who can execute
Agent level - authorization: what runs within that surface
- Scoped tokens: short-lived
- Allowed tools: connector-level
- OPA - runtime: pipeline policy
3. Behavioral Controls
Content and call inspection: the only probabilistic layer.
- Injection scan: LLM gateway
- PII + toxicity: LLM gateway
- Call security: MCP gateway
- OPA policies: gateway
Not load-bearing on its own. Designed to fail safely into 01 and 02.
Four threats. Four layers. No overlap in the job.
Working from that one assumption, a concrete list of things a hostile agent would try falls out almost by itself. Each one gets exactly one layer of defense, built to answer it and nothing else. Below is the map, running from the outermost edge of the container inward to the network path out.
Walking the chain, outside in
Each section below stands on its own. If you only care about one threat, say, where your secrets actually live, jump straight to it. Read straight through, and you get the whole chain, from the edge of the container to the only network path out.
Layer 1: Image hardening: An empty toolbox
The threat
Break into a normal container and you'll find a fully stocked workshop waiting. A compiler to build a payload. A package manager to pull one down. Setuid binaries to climb privileges. Network tools to probe around and call home. A general-purpose base image hands an attacker all of it, for free, the moment they're inside.
The defense
We strip the image down to the studs at build time and the stripping is permanent, not a setting someone can flip back:
- No compiler. The build toolchain, C compiler, linker, make, is purged. Nothing left to compile a second-stage payload with.
- No package manager. The agent can't install its way to a capability the image doesn't already ship. (Package metadata stays, so vulnerability scanners and SBOM tooling still see exactly what's installed.)
- No setuid binaries. Every setuid and setgid bit in the image is cleared, closing the classic local privilege-escalation path.
- Read-only at runtime. The recommended way to run it locks the root filesystem read-only, with small writable scratch areas mounted separately, turns off privilege escalation, and drops every Linux capability the container doesn't need. The image ships ready for that posture and our published pod spec sets it.
In plain terms
Picture breaking into a workshop and finding the pegboard empty. No tools on the wall, no machine plugged in, nothing to build with. You can be standing right there, inside the room, and still unable to do anything.

Stripped at build time, irreversibly, compiler removed, package metadata only, setuid bits cleared, network utilities removed.
Layer 2: Process isolation: Three users, one container
The threat
Even with no tools to build with, a compromised agent will still look at what's sitting around it: another process's environment variables, its memory, the files holding the keys. If everything inside the container runs as one user, all of that is just… readable.
The defense
Inside the single container, three distinct, unprivileged users run three distinct processes: the agent, the credential broker, and the egress proxy. The container starts as root only long enough to lay down permissions and network rules, then drops each process to its own user and never returns to root again.
The user running the agent is in none of the broker's groups, so the kernel denies it even the ability to traverse into the secret directory: every attempt comes back as a hard permission error, not a polite refusal. The broker's own source code is locked down the same way, so a compromised agent can't even read the logic it's trying to defeat.
In plain terms
Same building, different locks. Three tenants live under one roof, but tenant A's key was never cut to open tenant B's door. The building super hands out keys exactly once, at move-in, then leaves for good. Nobody can get a new key issued later, not even the super.
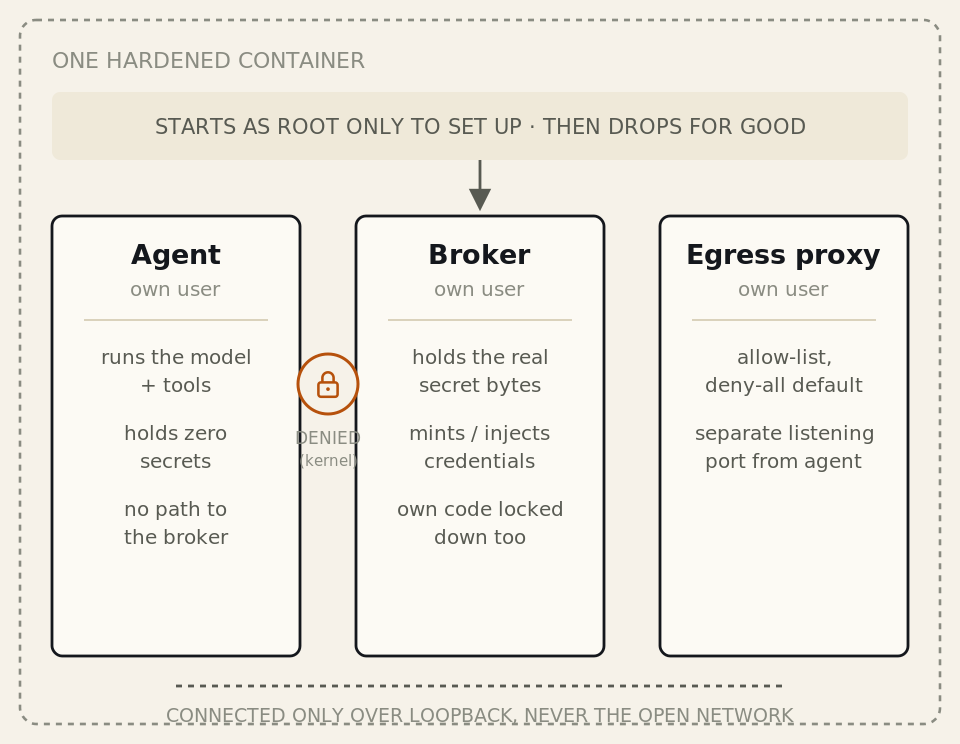
Kernel-enforced separation: not a convention, a permission error.
Layer 3: Secret isolation: The agent never holds a key
The threat
Credentials are the actual prize here: API keys, cloud tokens, platform tokens, registry passwords. In the naive design, they sit in the agent's own environment, and the agent can reach them the instant it wants to. One env dump, or a config file generated “with values baked in,” and they're gone.
The defense
We take the secrets away from the agent completely. The moment the container starts, before the agent process even exists, a classification pass runs over every environment variable. Anything that looks like a secret, caught by a generic naming convention, so a brand-new connector needs zero custom code, gets swapped, inside the agent's own environment, for a unique, single-use placeholder. The real value moves into a store that only the broker can read.
So the agent boots up and sees something like this, and nothing more:
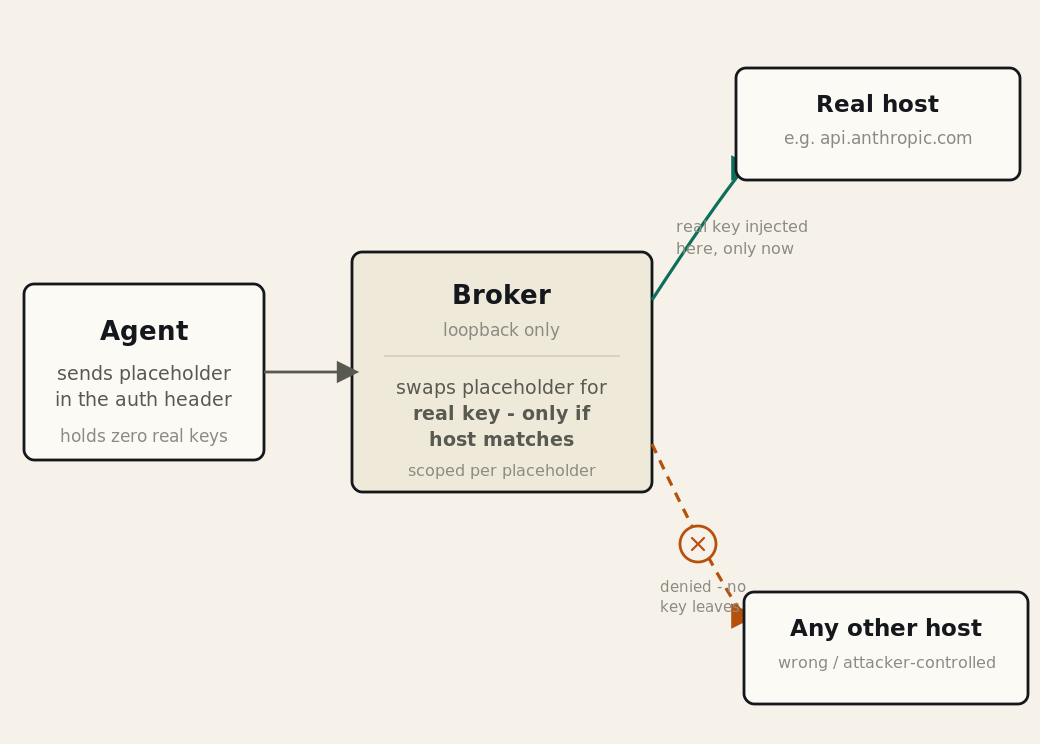
One placeholder, one destination. Replays against any other host fail.
ANTHROPIC_API_KEY = hbroker-Up4k…r3Q # placeholder, not a key
ANTHROPIC_BASE_URL = http://127.0.0.1:8443/proxy/api.anthropic.com
The real key is nowhere in the agent's world, ever. When the agent makes its call, it builds a normal-looking auth header with the placeholder and sends it to the in-container broker. The broker, and only the broker, swaps it for the real key on the way out, and only at that exact moment.
The agent container holds zero cloud-credential bytes: the same model covers credentials that can't ride in a header. Cloud SDK credentials, Google service-account keys, AWS and Azure managed identity, get signed into the request body instead, so the broker stands in as a metadata server and mints short-lived credentials on demand. No key file, no service-account JSON, nothing.
In plain terms
It's the valet-key trick hotels use. The key you hand the valet starts the car and opens the door, but it won't touch the glovebox or the trunk. Even a dishonest valet holding that exact key can't drive off in the car parked next to yours, it simply doesn't turn that ignition.
Layer 4: Network isolation: Traffic can't leave the path
The threat
A compromised agent with open network access is a data-exfiltration tool, full stop. Phone home to an attacker's server. Push data to a public mirror. Tunnel it out over whatever port happens to be open.
The defense
All outbound traffic from the container goes through an in-container proxy running an allow-list. Approved hosts pass. Everything else is denied by default. The agent's traffic and the broker's traffic ride separate listening ports, so the two zones are never confused with each other.
A proxy only matters if the agent can't route around it, so three independent mechanisms keep it on that path:
- Set for the agent: not left to its discretion as a setting it could choose to ignore.
- An always-on guard inspects every command and file write the agent issues, and blocks anything that tries to disable or sidestep the proxy: unsetting proxy variables, a “no-proxy” flag, stripping the environment through a helper, mutating it from inside an interpreter, or even a quiet bypass written into a shell startup file.
- A kernel-level firewall rule pins the agent's user to the proxy and rejects every other destination, off-container hosts, the broker's private port, and cloud metadata endpoints. The capability that installs it is used once by root at startup, then dropped for good. The agent can never get it back, and can't edit, list, or flush the rule that contains it.
Real APIs occasionally echo a request's own credentials back inside an error body, so the broker scrubs responses on the way back too. A stray 401 can't hand the agent the very key the broker just injected.
In plain terms
One exit, and it's guarded. The fire doors are welded shut, the windows don't open, and the guard's own keys get taken away once the building is set up for the day, so nobody , not even the guard, can prop a door open later.
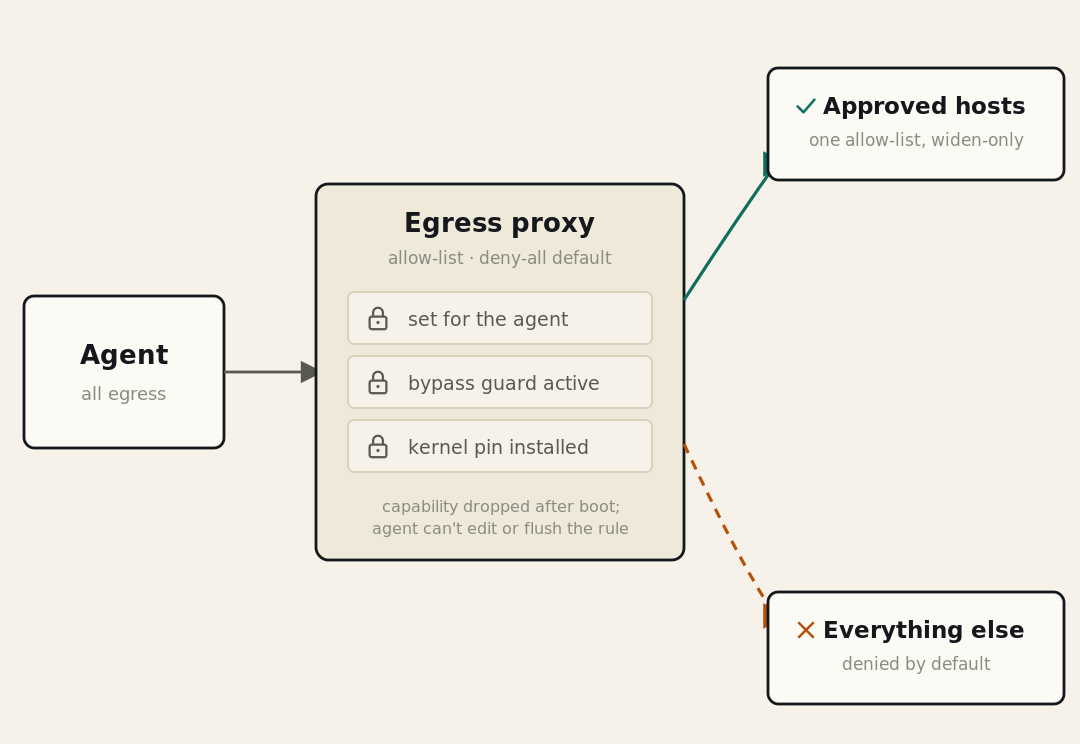
Three independent locks on one gate: not three settings, three different enforcement mechanisms.
Red-teaming our own design: Proof, not promises
None of this means much as an assertion, so we tested it the way an attacker would. We took a real, high-severity breach chain and replayed it against our own image, logged in as the agent.
Every other move in that chain failed the same way: each one stopped cold by a different layer.
Every layer is a release gate
Each isolation layer has its own end-to-end test that runs against the freshly built image, and the full breach-chain pentest above runs on top of all of them. Every check lives in the build pipeline ahead of the publish step, an image that regresses any single layer simply never ships, on either supported CPU architecture.
- Container smoke — Hardened image boots and is intact
- Process-isolation smoke — Three users separated; agent denied on secret files; egress ports pinned
- Secret-isolation test — Agent's environment holds only placeholders, never real secret bytes
- Per-host scoping test — A credential is injected only for its own host; off-target replays denied
- Egress-policy test — The allow-list is enforced and the deny-all default holds
- Credential-routing test — Each connector's traffic is routed and brokered correctly
- Proxy-bypass-guard test — Attempts to disable or route around the egress proxy are blocked
- Containment pentest — The full breach-chain replay above stays contained
- Image vulnerability scan — The published image clears the CVE policy
The proof isn't a slide from one audit done once. It runs on every release, and a single failure blocks the publish.
How it fits together
Security engineers have a name for this shape: the Swiss cheese model. Slice one piece of cheese and hold it to the light, there are holes in it. Every real-world control has gaps somewhere; that's just true, and pretending otherwise is how people get hurt. But stack four slices together, each with holes in different, unrelated places, and there's no longer a straight line through all four at once. None of these “slices” are guesswork, either. Each is enforced by a different mechanism, the build, the kernel, the filesystem, the network, so a gap in one almost never lines up with a gap in the next.
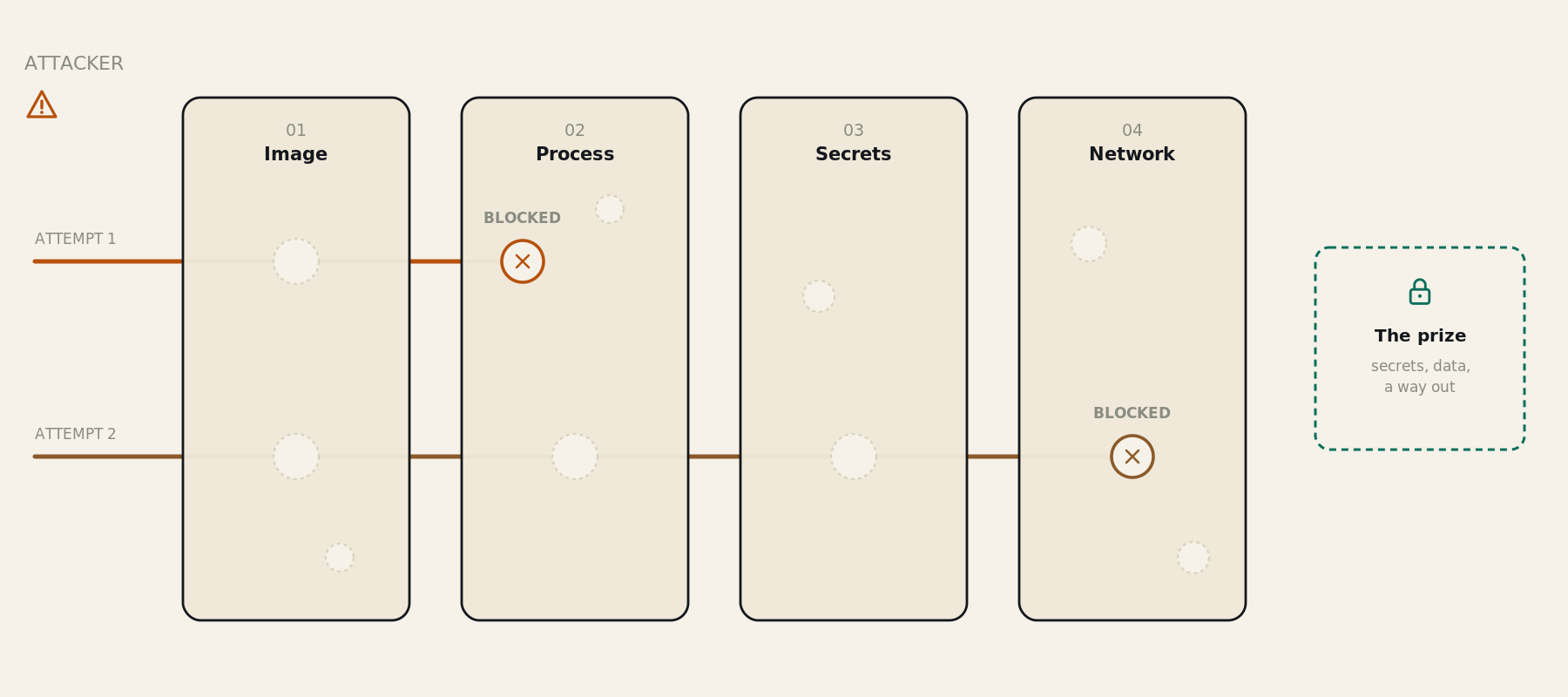
Attempt 1: finds a gap in image hardening, hits a solid wall at process isolation.
Attempt 2: gets three layers deep, still never reaches the prize.
A compromise of any single layer just lands in the next one. A tool that gets past the hardened image still can't read the secrets. An environment dump that gets read finds only placeholders. A placeholder that gets grabbed can't be aimed anywhere useful. And a connection that tries to phone home is pinned to the proxy and denied. That's the entire point of building it as four layers instead of betting everything on one wall.
The secure shape is the default
There's no separate hardening mode to opt into. You write an ordinary Agent step and pass your secrets the way you already do, under their normal names. The container does the rest before your agent process ever starts:
agent:
step:
run:
container:
image: harness-ai-agent:latest
env:
# Pass the real secret under the name the SDK already reads.
# The engine swaps it for a placeholder before the agent starts;
# The broker holds the real bytes and injects them only at egress.
AWS_BEARER_TOKEN_BEDROCK: <+secrets.getValue("bedrock_token")>
HARNESS_API_KEY: <+secrets.getValue("harness_token")>
That's the whole interface: no proxy wiring, no per-connector code, no placeholder plumbing on your side. The container classifies your secrets, swaps them for placeholders, writes a per-session network policy, drops to the three unprivileged users, and runs your agent, which never sees a single real credential.
Two things live in the platform, not the step: the three-user split and the read-only, capability-dropped runtime are set once in our published pod spec, and the kernel egress pin turns on wherever the runner can grant it. You don't wire any of it up per pipeline. It's how the image is meant to run.
FAQs
Why layers instead of one strong control?
Because any single control can fail, and an agent running tools on untrusted output gives an attacker a lot of chances to find that failure. Layering means a break in one boundary gets caught by the next one. And each layer is enforced by a different mechanism – the build, the kernel, the filesystem, the network – so a gap in one doesn't line up with a gap in the next.
Where do the secret bytes actually live, and who can read them?
With the broker process, in a store owned by the broker's user and readable only by it. The user running the agent is in none of the broker's groups, so the kernel denies it access outright. The agent's own environment only ever holds placeholders.
Is the egress proxy mandatory, or can the agent route around it?
It's set for the agent rather than left to its discretion, and an always-on guard blocks the obvious ways to disable or bypass it. On top of that, a kernel firewall rule pins the agent's traffic to the proxy and rejects everything else – the same control enforced one level down, where the agent can't touch it.
How does a new connector get secured? Do you write code for each one?
No. Secrets are recognized by a generic naming convention, so a new connector's key gets placeholder-swapped and host-scoped automatically, with zero custom wiring required.
What about prompt injection itself – doesn't that defeat all of this?
Isolation doesn't try to stop the injection – it makes a successful one boring. A hijacked agent still can't read a secret, can't reach a host off the allow-list, and can't turn the container into a toolkit. The blast radius is bounded by the system, not by the model's judgment. Catching the injection payload in the content itself is a separate job, handled by the LLM gateway – that's the subject of the next post in this series.
.png)
Get Ship Done: Everything We Shipped in June 2026
We shipped 62 features in June: roughly one every twelve hours! That pace isn't an accident. It's what happens when AI is writing more of the code, generating more of the tests, and clearing more of the review queue, and the rest of the delivery pipeline has to keep up.
This month's list touches almost every stage of that pipeline: builds that start faster, tests that write themselves, security scanning built for the volume of code AI agents now produce, feature flags that update without a redeploy, and on-call tooling that beats PagerDuty and OpsGenie on setup time alone. And on June 30, the biggest release of the month landed on top of all of it. Here's everything we shipped.
This month's biggest ships
Autonomous Worker Agents: Every step in a Harness pipeline, testing, security, deployment, and remediation, can now run as a reasoning agent instead of a fixed script, with the same governance and audit trails enterprises already trust for human-run deployments. It's the difference between AI helping write a script and AI running the step.
Parallel pipeline execution using a Directed Acyclic Graph: Pipelines can now declare dependencies between stages and run every independent one in parallel automatically, unlocking fan-out, fan-in, and diamond-shaped flows that sequential pipelines couldn't express. A convert-to-DAG API rewrites existing pipelines automatically, so the migration is a button, not a rebuild.
AI Engineering Insights: Measures what most engineering orgs are still guessing at: AI coding agent adoption over time, AI-committed code percentage, spend per developer, and PR cycle time for AI-assisted developers versus everyone else. It's the metric layer for the AI productivity paradox, not another dashboard of vanity stats.
Here are the details:
Every pipeline step can now be an agent
On June 30, Harness introduced Autonomous Worker Agents, a platform for building and safely running AI agents that handle the work between writing code and shipping it to production. Every step in a pipeline, testing, security, deployment, and remediation, can now run as a reasoning agent instead of a fixed script, governed by the same scoped credentials, OPA policy enforcement, approval gates, and audit trails enterprises already use for human-run deployments.
Agents pull context from the Harness Knowledge Graph, connecting services, pipelines, deployments, incidents, and policies, and act through the Harness MCP Server, so a developer working in Cursor, Claude Code, or another editor can hand a task to a Worker Agent and get the result back without leaving their tool. A new Agent Marketplace lets teams find, clone, and customize both Harness-managed and community-built agents, so the agent one team builds to solve a problem becomes the starting point for the next team that hits the same wall. Worker Agents are available now to all Harness customers and work with any LLM provider. Read the full announcement here.
Builds that start faster and cache smarter
Docker Layer Caching and Build Cache now both support Azure Blob Storage as a backend, joining S3 and GCS. Teams running on Azure no longer have to route their caching through a different cloud to get the speed benefit. Find more details in the CI release notes.
CI build initialization on Kubernetes infrastructure now sends only the fields required to start a build, shrinking the initialization payload. Pipelines with a large number of steps start faster and more reliably as a result.
A new Test Management Dashboard lists every test, including flaky and quarantined ones, with health status and last-run results in one place, so no one has to go hunting through build logs to find the test that's been silently failing all week.
Small but real: the lite-engine HTTP client now handles 3XX and 4XX responses from the log service correctly, so a redirect or an error response during log streaming no longer takes the build down with it.
AI writes the tests, coverage tells you if it's enough
AI Test Automation now runs Playwright test suites natively, in beta, as a first-class execution engine. Teams bring their existing Playwright suites and run them on the platform with zero infrastructure to stand up or maintain. Learn more about running Playwright tests on Harness.
Watch the demo:
Existing tests can now be converted into natural language and downloaded, so teammates who don't work in code, PMs, auditors, and new hires can review or document test coverage without reading a test file. More on that in the AI Test Automation release notes.
And Harness Code Repository now shows what percentage of your codebase is actually covered by tests, surfacing untested paths before they turn into incidents.
Deployments that scale without more YAML
Pipelines can now declare dependencies between stages with a dependsOn field. Harness runs every independent stage in parallel the moment its predecessors finish, unlocking fan-out into multiple parallel deployments, fan-in to a single approval gate, and diamond-shaped flows where build, test, and infra stages converge before promotion, patterns a sequential pipeline simply couldn't express. A new convert-to-DAG API rewrites an existing sequential pipeline automatically, so migration doesn't mean a rewrite.
Templates now support custom floating tags, not just the built-in stable pointer. Template owners can create tags like prod, canary, or qa, each pointing at a different template version, and repoint any of them independently without touching a single line of consumer YAML. That means you can promote a new template version to canary, let it bake, then move prod once it's validated, with different environments running different versions at the same time.
A handful of other pipeline and delivery upgrades this month: the Copy command in Command steps can now preserve directory structure so same-named files in different subfolders stop overwriting each other on target hosts; Kubernetes Dry Run steps now accept kubectl flags like --server-side and --force-conflicts, so approval gates reflect what a real deployment will do; the Artifactory connector supports OIDC for credential-free authentication with short-lived JWTs; AWS OIDC connectors now tag sessions with environment identifiers, letting you restrict production secrets to production pipelines even on a shared delegate pool; Istio traffic routing steps support AND/OR match logic across route rules; approval steps can show details to non-approvers without granting them approval rights; and issue-comment webhook triggers now resolve to the latest commit message instead of the PR description, bringing them in line with every other trigger type. Find the full rundown in the continuous delivery release notes.
Security built for how much code AI agents write now
A new AI-powered SAST engine, in beta, validates findings in context to cut triage effort and catch vulnerabilities that traditional static scanners miss, purpose-built for a world where AI-generated code is multiplying the volume of things that need checking. Learn more about AI SAST.
API Security Testing scans that get interrupted by timeouts or infrastructure issues can now resume from the point of failure instead of restarting from scratch. Scans also picked up a real-time validation summary tab, plus the ability to label and rename them so a security team running dozens of scans a week can actually tell them apart. Details are in the scan documentation.
A new API Inspector automatically analyzes OpenAPI specs for security, design, and data validation issues before deployment, catching problems while they're still cheap to fix.
Approvers reviewing exemption requests can now adjust the requested duration instead of only accepting or rejecting it outright, which means fewer rejected requests that just get resubmitted with a smaller ask.
Teams can now bulk onboard Bitbucket repositories and run SBOM and security scans automatically, no manual pipeline setup required, and role-based permissions expanded across more supply chain workflows. Learn more about Bitbucket onboarding.
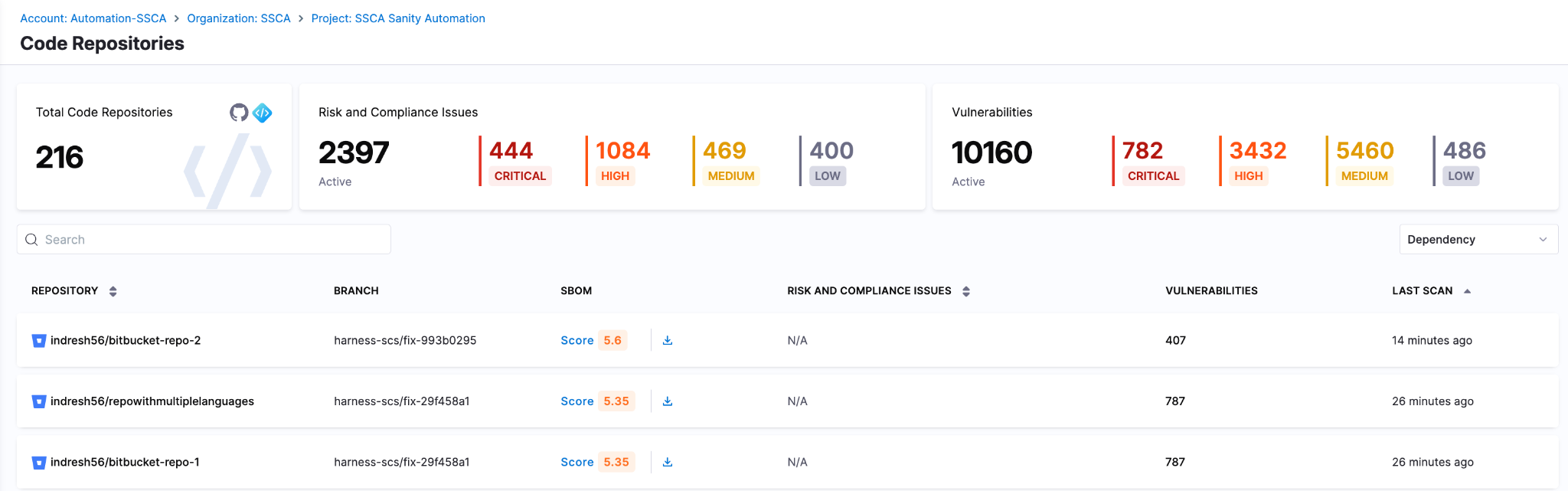
Harness AI now generates OPA policies directly, trained on OPA and REGO best practices, and can explain existing policies in plain language, so writing policy-as-code no longer requires deep REGO expertise on the team.
Rounding out security: issue detection policies can now scope to specific span attributes to cut noise, API exclusion rules gained span-attribute filtering for the same reason, a new Applications view groups related APIs and AI assets into business-centric categories like payments or order processing so large API inventories stay navigable, the older API Activity dashboard is being retired in favor of these newer views, and Role Assignment API endpoints now validate request payloads up front, returning clear errors instead of failing downstream.
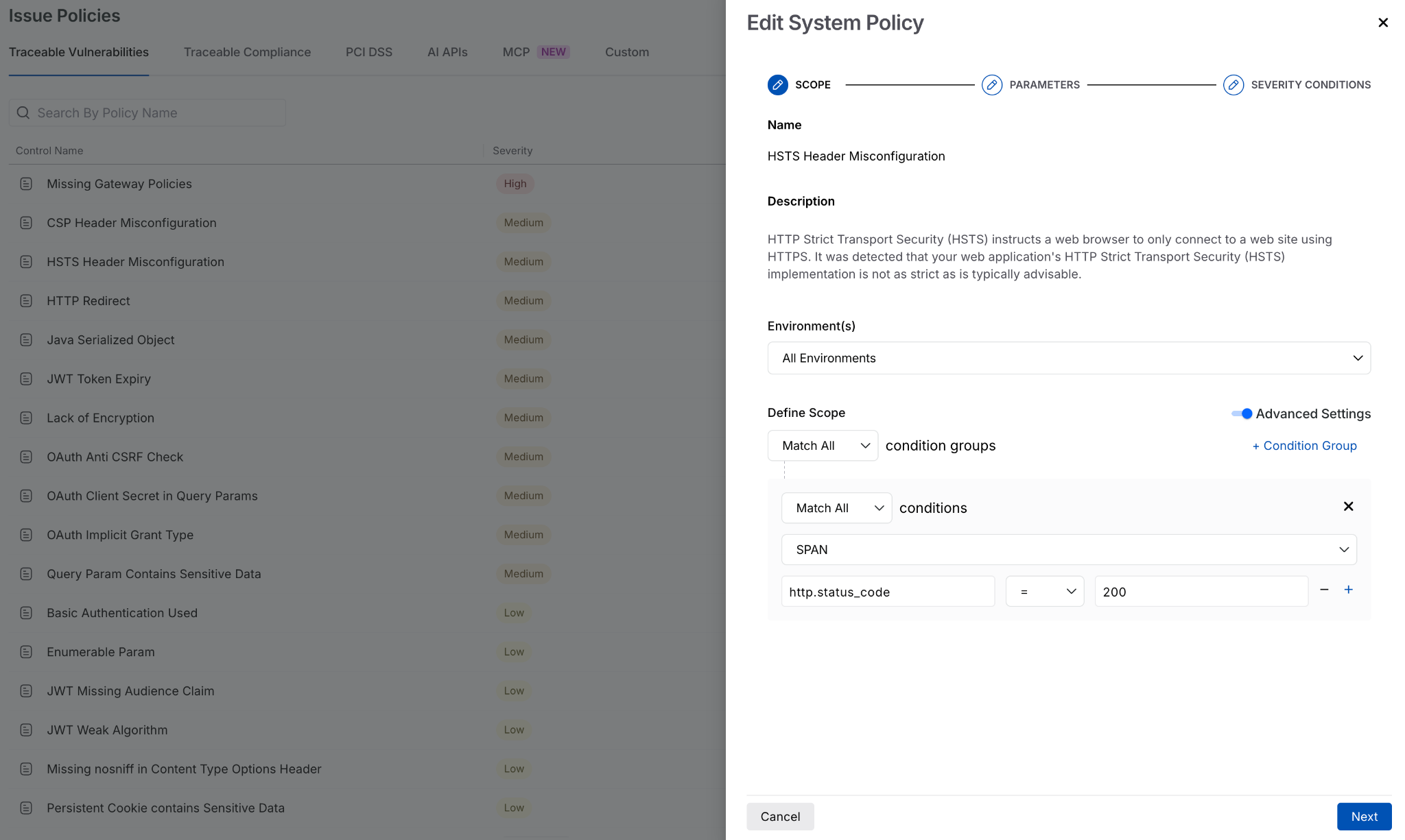
Feature flags that update without a redeploy
Feature flag definitions can now be changed through a pipeline step that applies structured, atomic updates, batching multiple configuration changes into one consistent operation instead of stitching together raw patch calls. Find more details here.
And a new family of thin SDKs, built for browsers, mobile apps, and edge or serverless JavaScript, delegates flag evaluation to a remote evaluator in the cloud instead of computing it on-device. Rollout rules and segment definitions stay server-side; the SDK only gets the result. Learn more in the feature flag release notes.
Finding out what AI is actually doing to your engineering org
A new AI Engineering Insights capability tracks AI coding agent adoption across teams over time, measures output with metrics like AI-committed code percentage and lines generated, and monitors spend per developer and per commit. It also compares AI-assisted and non-AI developer performance head-to-head on PR cycle time and work items delivered, with a leaderboard for drilling into individual patterns. Read more in the AI DLC Insights release notes.
Cloud and AI cost management gets more precise
The Cloud and AI Cost Management overview page got a redesign: new widgets for top spenders, optimization impact, and service breakdown, plus support for AWS and GCP cost adjustments.
You can now connect OpenAI and Anthropic accounts directly through a guided three-step wizard with secure API key storage and live connection testing, currently behind a feature flag. Grouping AI traces by service in Cost Explorer now opens a drawer with run history, a span-level timeline, and cost attribution down to the individual trace. And a new Asset Governance tab lets you set cost preferences separately for AWS, GCP, and Azure, also behind a feature flag.
The rest of this month's cost updates were accuracy and access fixes: anomaly filters no longer silently ignore a perspective that's been deleted, nodepool savings calculations now use the same cost basis as the monthly total instead of overstating savings, overview anomaly counts now include both resource-level and cost-category anomalies, only users with the right permission can edit or delete anomaly alerts, recommendation savings labels are localized to your preferred cost type, repeated commitment renewal events now collapse into a single indicator instead of a wall of icons, and filter messaging and recommendations navigation both got cleaned up. Full details are in the cost management release notes.
The developer portal gets better at knowing what you actually have
New integrations auto-discover and ingest entities from your existing tools, no manual YAML, no custom scripts. Unlike frontend-only plugins, this data feeds into scorecards, workflows, aggregation rules, and the knowledge graph itself.
Bitbucket Cloud entities in the catalog now show pull request history and commit activity right on the entity page, and Dynatrace entities show monitor and SLO data the same way, so developers get observability context without leaving the portal. More on that in the IDP release notes.
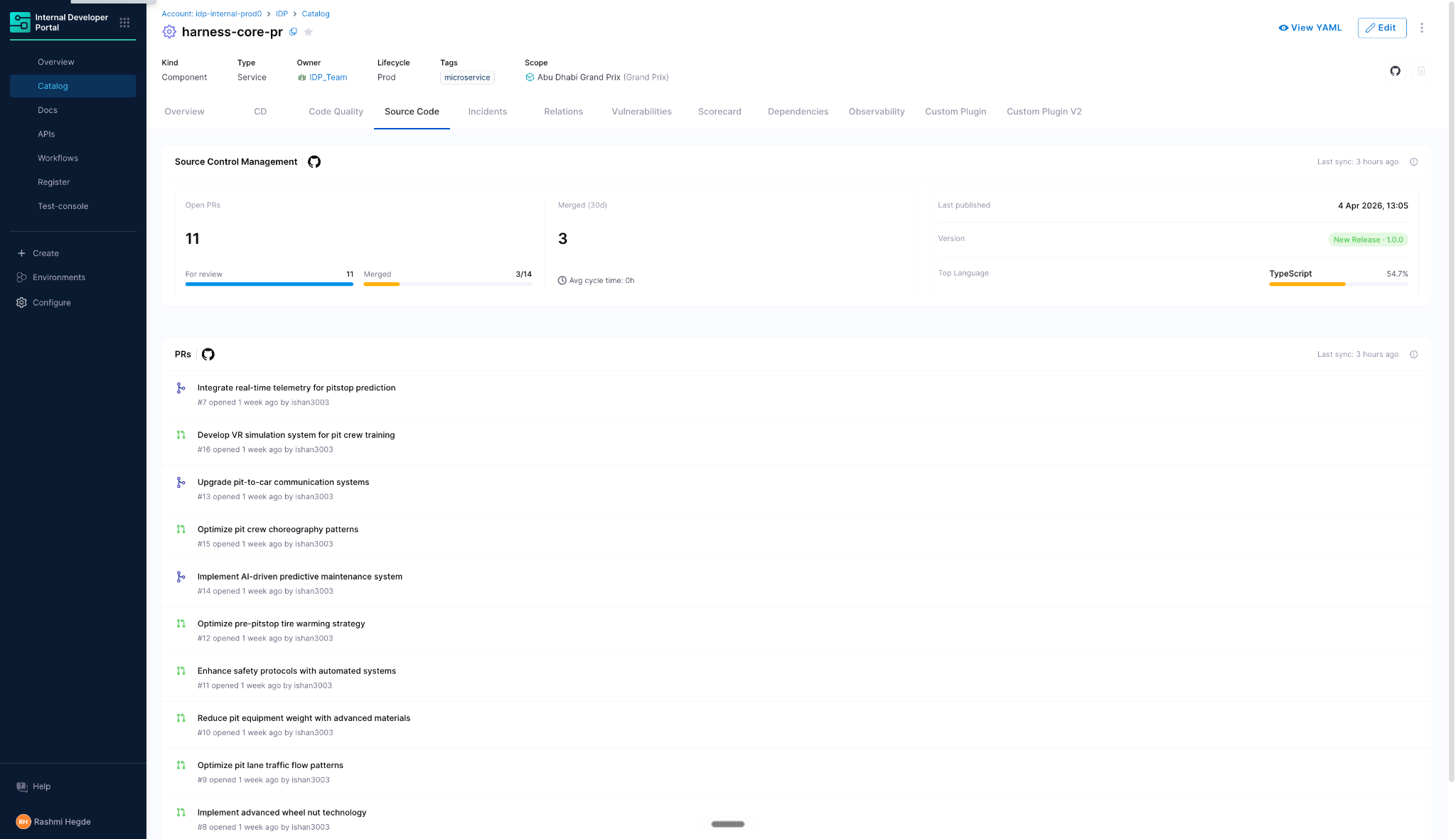
Environment Management now shows a clear, current state for every environment, so platform engineers know what's actually happening without cross-referencing three other tools.
Infrastructure as code, managed like a real registry
Module Registry 2.0, in beta, lets teams publish IaC modules as immutable artifacts, auto-sync new versions on publish, and govern them with Supported, Warning, and Deprecated controls across project, org, and account scopes. Self-service, with guardrails, instead of a spreadsheet tracking who's on which version. Learn more about Module Registry.
Drift detection can now run on any schedule you set, and workspaces can be given a TTL so short-lived infrastructure, PR environments, and feature branches tears itself down automatically instead of quietly running up a cloud bill. Find more details on ephemeral workspaces.
Database changes that ship like code
Database DevOps now supports Harness Code Repository natively as a schema source, so teams no longer need a separate Git connector just to point at their own repo.
And Database DevOps can now authenticate to Amazon RDS and Aurora using AWS IAM through Harness's delegate, currently in beta and behind a feature flag, cutting down on credential management overhead and closing off a class of stored-secret risk.
Artifacts that clean up after themselves
Harness Artifact Registry now supports policy-based lifecycle rules that automatically delete or protect artifacts based on version count, age, or download activity. Administrators set the policy once instead of manually pruning old builds every quarter. Learn more in the Artifact Registry release notes.
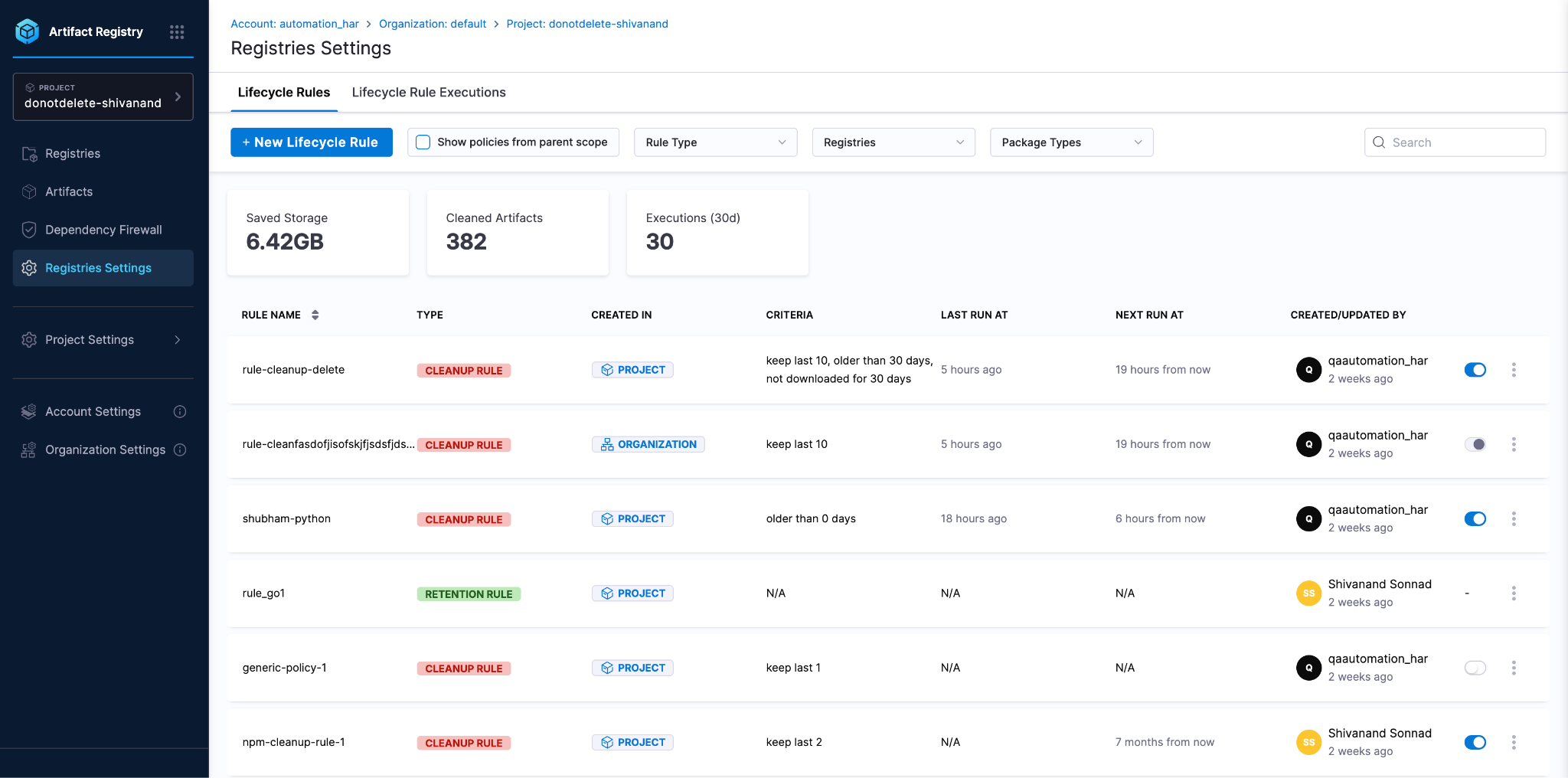
Resilience testing before production finds the gap for you
Resilience Testing picked up Linux and Windows chaos experiment templates for the Chaos Step, audit trails with YAML diff visualization for the image registry, better probe timeout and retry handling, and the ability to copy output variables straight from the timeline view. Find the full list in the Chaos Engineering release notes.
Incident response that outpaces PagerDuty and OpsGenie
Escalation policies can now target a single rotation inside a schedule instead of paging every responder across it. If an incident belongs to "IT West Critical," only that rotation gets paged. Rotations, schedules, and users can all be mixed as targets across different levels of the same policy, so each escalation step reaches exactly the right people.
On-call configuration can now be imported by picking the exact services and groups you want, instead of pulling an entire account in one shot, and it works across PagerDuty, OpsGenie, and xMatters. That's a direct answer to the biggest complaint about migrating off those tools: an all-or-nothing import that forces a weekend cutover.
Runbooks can now be duplicated in one click, chain items, action configurations, and metadata all carried over intact, with the copy opening automatically so you can start tailoring it instead of rebuilding from scratch.
The pattern
None of these features exists in isolation. AI is compressing how fast code gets written, which means the pressure shows up everywhere downstream: builds need to start faster, tests need to generate themselves, security scanning needs to handle more volume without more false positives, and incident response needs to route the right alert to the right rotation the first time. Autonomous Worker Agents is the next turn of that same screw: instead of just helping teams keep up with AI-written code, Harness is now putting AI directly into the pipeline steps that ship, secure, and operate it. Sixty-two features in thirty days, plus a new agent platform on top, is what closing the velocity gap looks like in practice. We'll be back next month with more of it.

Prepare for the EU AI Act with Harness AI Security
Harness AI Security provides a unified control plane for AI discovery, risk visibility, and runtime protection, helping organizations operationalize key requirements of the EU AI Act. Instead of relying on manual audits or fragmented tooling, teams get continuous insight into how AI systems are built, exposed, and used, along with the evidence needed to demonstrate compliance.
By combining AI asset discovery, risk classification, data flow visibility, and runtime enforcement, Harness enables customers to proactively identify high-risk systems, prevent unsafe integrations, and continuously monitor AI behavior in production. This approach aligns directly with the EU AI Act's focus on transparency, traceability, and ongoing risk management.
Harness helps in the following areas of the EU AI Act
AI System Inventory
Harness automatically discovers all AI assets—AI APIs, Agents, MCP servers, MCP tools, resources, prompts, and AI backends by analyzing live network traffic. The centralized inventory provides a real-time breakdown of discovered assets by type, call volume trends, and sensitive data exposure across your environment. Security and compliance teams gain a single, continuously updated source of truth for every AI component in use, without requiring manual cataloging or developer-submitted forms.
Risk Identification & Classification (Article 6)
Once assets are discovered, Harness derives a risk score for each based on policy violations, known vulnerabilities, exposure level (internal vs. external), and sensitive data flow. This scoring helps teams prioritize remediation efforts and demonstrate that high-risk AI systems have been identified and assessed, which is a core expectation under the EU AI Act's risk-based framework.
Prohibited Use Cases (Article 5)
Harness detects shadow AI vendors, unapproved MCP servers, and undocumented AI APIs surfacing in your environment. The Third Party view surfaces AI APIs grouped by vendor (e.g., OpenAI, Google, Anthropic) so teams can identify integrations that haven't undergone procurement or security review. This is directly relevant to the EU AI Act's prohibition on certain AI use cases and its requirements around supply chain transparency for AI systems.
Data Governance & Quality (Article 10)
Harness monitors sensitive data flows across all discovered AI assets, identifying where PII and regulated data enters and exits AI systems. The platform classifies data sensitivity automatically by analyzing asset metadata and observed traffic patterns, giving teams a continuous view of which assets handle sensitive information and surfacing misuse risks before they become compliance incidents.
Technical Documentation & Auditability (Articles 11, 16)
Harness automatically generates schemas for AI APIs, MCP tools, resources, and prompts by analyzing real network traffic with no manual documentation effort required. Each asset detail page captures the asset's type, dependencies, call volume, risk posture, and data flows in one place. This detail provides compliance teams with the structured technical records required under Articles 11 and 16 without burdening engineering teams with additional documentation.
Logging & Traceability (Article 12)
Harness captures all AI interactions, including AI API calls, MCP tool invocations, database calls, and non-AI API calls, in a centralized data lake with seven-day standard retention and 30-day retention for threat activity. This complete, queryable record of AI system behavior supports both routine audit needs and forensic investigations, directly satisfying Article 12's requirements for logging and traceability of high-risk AI systems.
Accuracy, Robustness & Security (Article 9)
The AI Firewall (beta) provides runtime enforcement against the most common AI-layer threats: prompt injection attacks, PII leakage in model responses, excessive model usage, and unauthorized model access. Together, these controls address the robustness and security requirements of Article 9, helping organizations demonstrate that their AI systems have active protections in place rather than passive policies.
Post-Market Monitoring (Article 72)
Harness continuously discovers new AI assets, shadow AI usage, and emerging sensitive data risks in production as your environment evolves. Real-time alerts are triggered for new vulnerabilities and compliance violations, with native integrations into SOC/SIEM workflows for rapid response. This ongoing monitoring capability aligns directly with the EU AI Act's post-market surveillance requirements, ensuring compliance doesn't end at deployment.
Bottom line: Harness AI Security provides the visibility, controls, and audit evidence layer required to operationalize EU AI Act compliance at scale and oversee AI system security. (Article 14)
The Modern Software Delivery Platform®
Need more info? Contact Sales